 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse-Aware Dual-Track Streaming Response for Low-Latency Spoken Dialogue Systems
Feb 26, 2026Achieving human-like responsiveness is a critical yet challenging goal for cascaded spoken dialogue systems. Conventional ASR-LLM-TTS pipelines follow a strictly sequential paradigm, requiring complete transcription and full reasoning before speech synthesis can begin, which results in high response latency. We propose the Discourse-Aware Dual-Track Streaming Response (DDTSR) framework, a low-latency architecture that enables listen-while-thinking and speak-while-thinking. DDTSR is built upon three key mechanisms: (1) connective-guided small-large model synergy, where an auxiliary small model generates minimal-committal discourse connectives while a large model performs knowledge-intensive reasoning in parallel; (2) streaming-based cross-modal collaboration, which dynamically overlaps ASR, LLM inference, and TTS to advance the earliest speakable moment; and (3) curriculum-learning-based discourse continuity enhancement, which maintains coherence and logical consistency between early responses and subsequent reasoning outputs. Experiments on two spoken dialogue benchmarks demonstrate that DDTSR reduces response latency by 19%-51% while preserving discourse quality. Further analysis shows that DDTSR functions as a plug-and-play module compatible with diverse LLM backbones, and remains robust across varying utterance lengths, indicating strong practicality and scalability for real-time spoken interaction.
Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection
Dec 15, 2020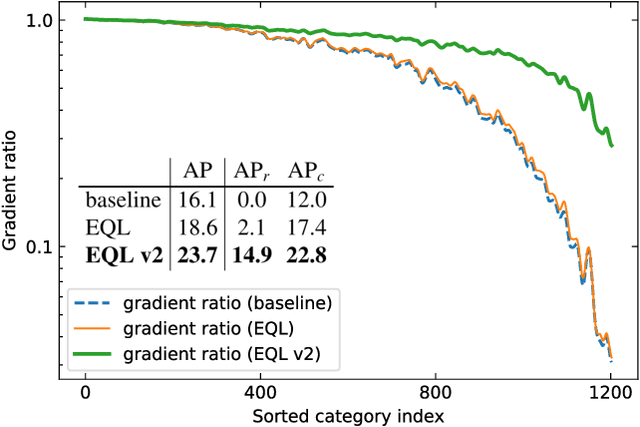
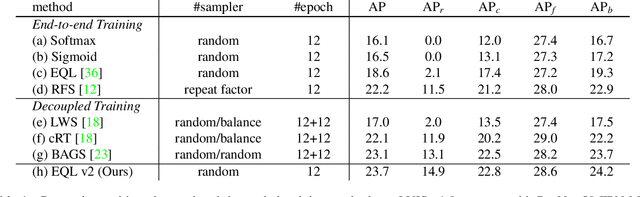
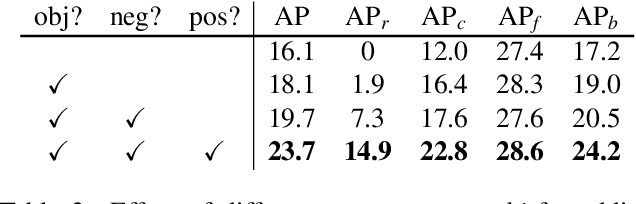
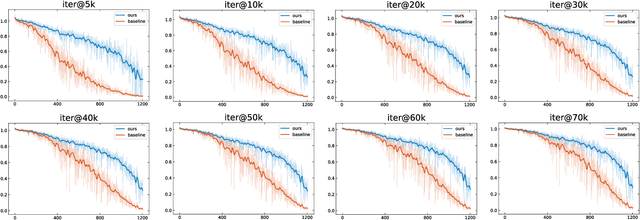
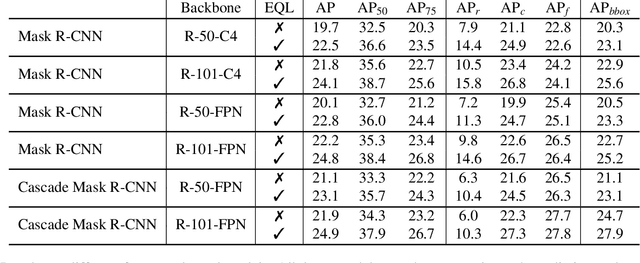
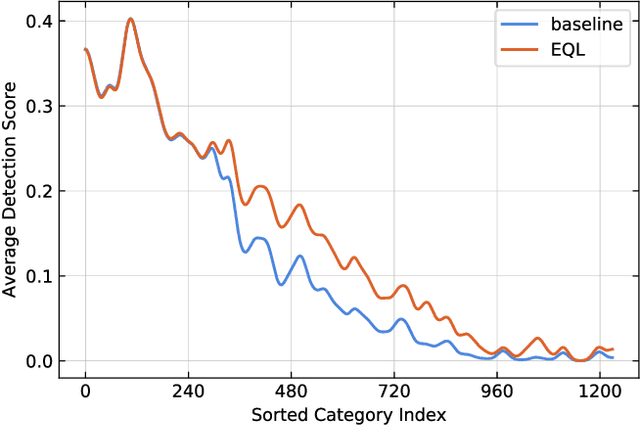
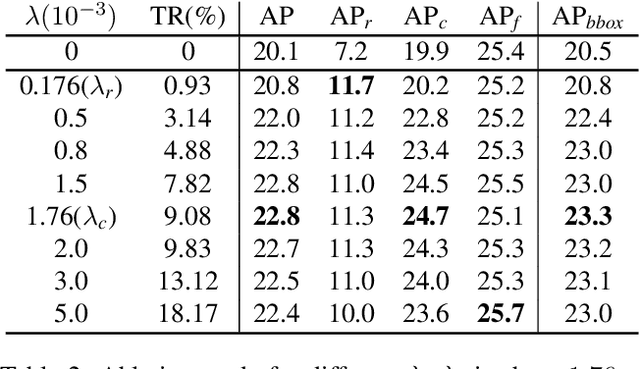
Recently proposed decoupled training methods emerge as a dominant paradigm for long-tailed object detection. But they require an extra fine-tuning stage, and the disjointed optimization of representation and classifier might lead to suboptimal results. However, end-to-end training methods, like equalization loss (EQL), still perform worse than decoupled training methods. In this paper, we reveal the main issue in long-tailed object detection is the imbalanced gradients between positives and negatives, and find that EQL does not solve it well. To address the problem of imbalanced gradients, we introduce a new version of equalization loss, called equalization loss v2 (EQL v2), a novel gradient guided reweighing mechanism that re-balances the training process for each category independently and equally. Extensive experiments are performed on the challenging LVIS benchmark. EQL v2 outperforms origin EQL by about 4 points overall AP with 14-18 points improvements on the rare categories. More importantly, It also surpasses decoupled training methods. Without further tuning for the Open Images dataset, EQL v2 improves EQL by 6.3 points AP, showing strong generalization ability. Codes will be released at https://github.com/tztztztztz/eqlv2
Equalization Loss for Long-Tailed Object Recognition
Apr 14, 2020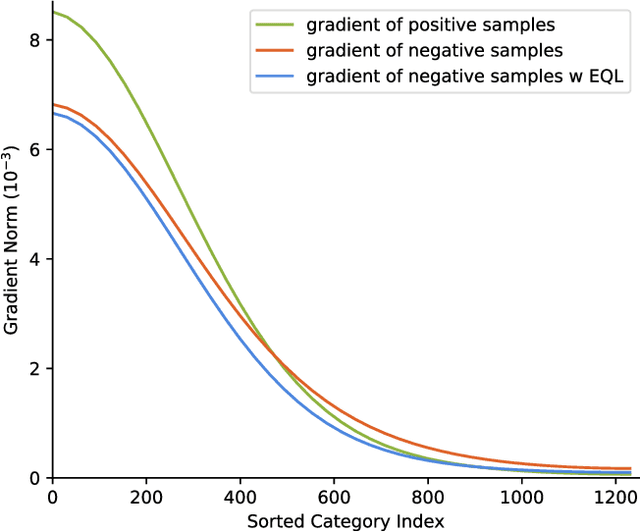
Object recognition techniques using convolutional neural networks (CNN) have achieved great success. However, state-of-the-art object detection methods still perform poorly on large vocabulary and long-tailed datasets, e.g. LVIS. In this work, we analyze this problem from a novel perspective: each positive sample of one category can be seen as a negative sample for other categories, making the tail categories receive more discouraging gradients. Based on it, we propose a simple but effective loss, named equalization loss, to tackle the problem of long-tailed rare categories by simply ignoring those gradients for rare categories. The equalization loss protects the learning of rare categories from being at a disadvantage during the network parameter updating. Thus the model is capable of learning better discriminative features for objects of rare classes. Without any bells and whistles, our method achieves AP gains of 4.1% and 4.8% for the rare and common categories on the challenging LVIS benchmark, compared to the Mask R-CNN baseline. With the utilization of the effective equalization loss, we finally won the 1st place in the LVIS Challenge 2019. Code has been made available at: https: //github.com/tztztztztz/eql.detectron2