 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADD: Path-Aligned Decompression Distillation for Non-Router Teacher to Guide MoE Student Learning
Jun 09, 2026As large language models (LLMs) continue to scale, it becomes increasingly challenging to grow model capacity under fixed computation budgets. We propose Path-Aligned Decompression Distillation (PADD), a framework for distilling knowledge from dense teachers without explicit routing into mixture-of-experts (MoE) students while learning high-quality routing policies. PADD organizes knowledge distillation into four stages in two phases: an initialization phase (Stage I) that builds diverse functionality in the student's experts through teacher neuron clustering and student-expert warmup, and a training phase (Stages II--IV) that integrates online adaptive distillation, path-refined policy optimization, and reward-augmented load balancing in a single training pipeline. Experiments on mathematical reasoning benchmarks demonstrate that PADD yields substantial gains over strong baselines at the same inference cost and that the MoE student can match or surpass its dense teacher. They also demonstrate effective teacher-to-student knowledge distillation and stable routing behavior.
Cross-dataset Training for Class Increasing Object Detection
Jan 14, 2020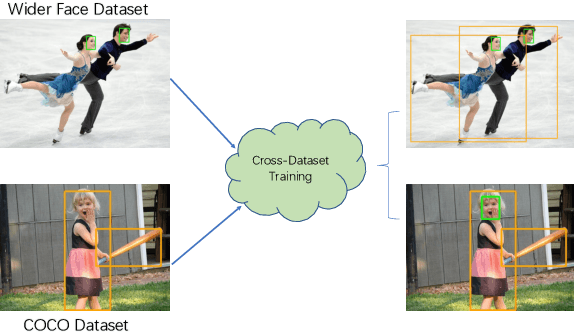
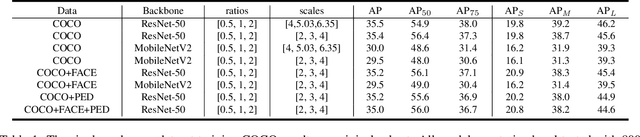
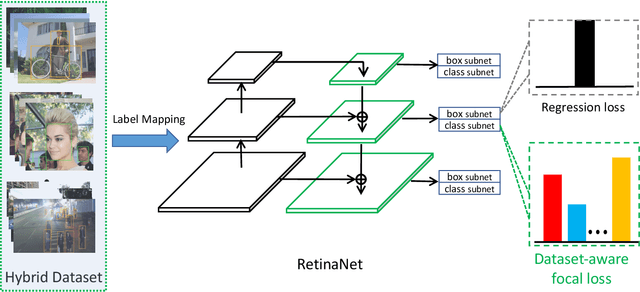

We present a conceptually simple, flexible and general framework for cross-dataset training in object detection. Given two or more already labeled datasets that target for different object classes, cross-dataset training aims to detect the union of the different classes, so that we do not have to label all the classes for all the datasets. By cross-dataset training, existing datasets can be utilized to detect the merged object classes with a single model. Further more, in industrial applications, the object classes usually increase on demand. So when adding new classes, it is quite time-consuming if we label the new classes on all the existing datasets. While using cross-dataset training, we only need to label the new classes on the new dataset. We experiment on PASCAL VOC, COCO, WIDER FACE and WIDER Pedestrian with both solo and cross-dataset settings. Results show that our cross-dataset pipeline can achieve similar impressive performance simultaneously on these datasets compared with training independently.