 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
Jan 15, 2025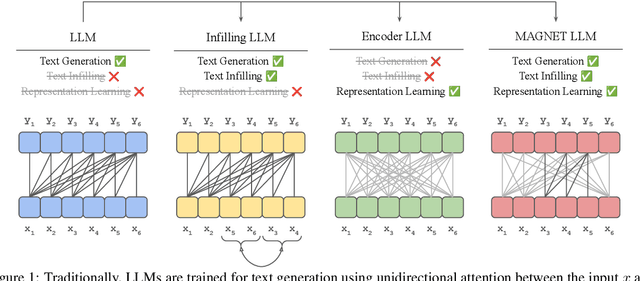
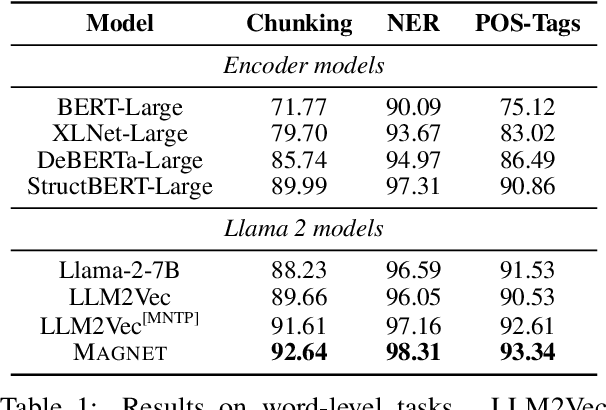
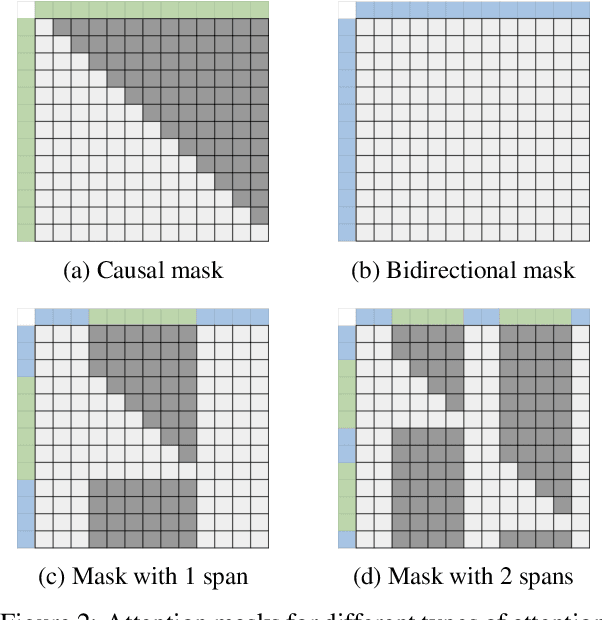
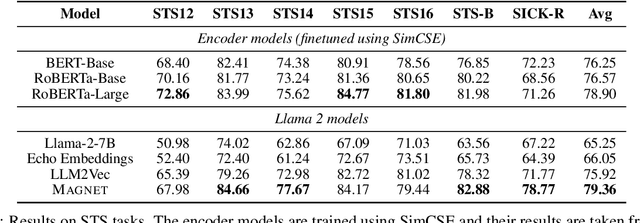
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning, respectively). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we introduce MAGNET, an adaptation of decoder-only LLMs that enhances their ability to generate robust representations and infill missing text spans, while preserving their knowledge and text generation capabilities. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging future context, (3) retain the ability for open-ended text generation without exhibiting repetition problem, and (4) preserve the knowledge gained by the LLM during pretraining.
Toward Robust Hyper-Detailed Image Captioning: A Multiagent Approach and Dual Evaluation Metrics for Factuality and Coverage
Dec 24, 2024Multimodal large language models (MLLMs) excel at generating highly detailed captions but often produce hallucinations. Our analysis reveals that existing hallucination detection methods struggle with detailed captions. We attribute this to the increasing reliance of MLLMs on their generated text, rather than the input image, as the sequence length grows. To address this issue, we propose a multiagent approach that leverages LLM-MLLM collaboration to correct given captions. Additionally, we introduce an evaluation framework and a benchmark dataset to facilitate the systematic analysis of detailed captions. Our experiments demonstrate that our proposed evaluation method better aligns with human judgments of factuality than existing metrics and that existing approaches to improve the MLLM factuality may fall short in hyper-detailed image captioning tasks. In contrast, our proposed method significantly enhances the factual accuracy of captions, even improving those generated by GPT-4V. Finally, we highlight a limitation of VQA-centric benchmarking by demonstrating that an MLLM's performance on VQA benchmarks may not correlate with its ability to generate detailed image captions.
GUI Agents: A Survey
Dec 18, 2024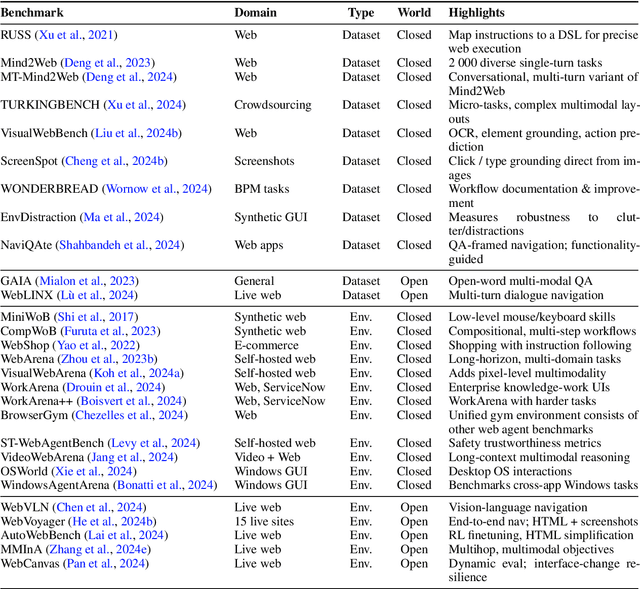
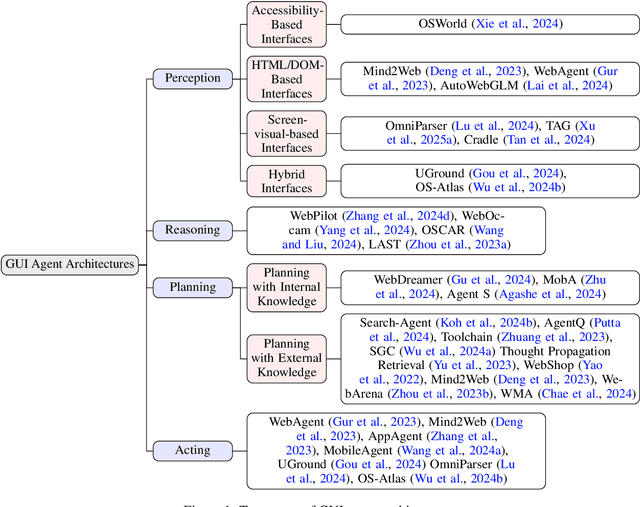

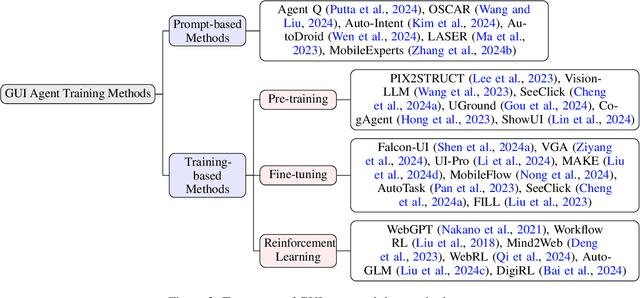
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
SUGAR: Subject-Driven Video Customization in a Zero-Shot Manner
Dec 13, 2024We present SUGAR, a zero-shot method for subject-driven video customization. Given an input image, SUGAR is capable of generating videos for the subject contained in the image and aligning the generation with arbitrary visual attributes such as style and motion specified by user-input text. Unlike previous methods, which require test-time fine-tuning or fail to generate text-aligned videos, SUGAR achieves superior results without the need for extra cost at test-time. To enable zero-shot capability, we introduce a scalable pipeline to construct synthetic dataset which is specifically designed for subject-driven customization, leading to 2.5 millions of image-video-text triplets. Additionally, we propose several methods to enhance our model, including special attention designs, improved training strategies, and a refined sampling algorithm. Extensive experiments are conducted. Compared to previous methods, SUGAR achieves state-of-the-art results in identity preservation, video dynamics, and video-text alignment for subject-driven video customization, demonstrating the effectiveness of our proposed method.
FINECAPTION: Compositional Image Captioning Focusing on Wherever You Want at Any Granularity
Nov 23, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal tasks, enabling more sophisticated and accurate reasoning across various applications, including image and video captioning, visual question answering, and cross-modal retrieval. Despite their superior capabilities, VLMs struggle with fine-grained image regional composition information perception. Specifically, they have difficulty accurately aligning the segmentation masks with the corresponding semantics and precisely describing the compositional aspects of the referred regions. However, compositionality - the ability to understand and generate novel combinations of known visual and textual components - is critical for facilitating coherent reasoning and understanding across modalities by VLMs. To address this issue, we propose FINECAPTION, a novel VLM that can recognize arbitrary masks as referential inputs and process high-resolution images for compositional image captioning at different granularity levels. To support this endeavor, we introduce COMPOSITIONCAP, a new dataset for multi-grained region compositional image captioning, which introduces the task of compositional attribute-aware regional image captioning. Empirical results demonstrate the effectiveness of our proposed model compared to other state-of-the-art VLMs. Additionally, we analyze the capabilities of current VLMs in recognizing various visual prompts for compositional region image captioning, highlighting areas for improvement in VLM design and training.
GroundingBooth: Grounding Text-to-Image Customization
Sep 13, 2024Recent studies in text-to-image customization show great success in generating personalized object variants given several images of a subject. While existing methods focus more on preserving the identity of the subject, they often fall short of controlling the spatial relationship between objects. In this work, we introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed text-image grounding module and masked cross-attention layer allow us to generate personalized images with both accurate layout alignment and identity preservation while maintaining text-image coherence. With such layout control, our model inherently enables the customization of multiple subjects at once. Our model is evaluated on both layout-guided image synthesis and reference-based customization tasks, showing strong results compared to existing methods. Our work is the first work to achieve a joint grounding of both subject-driven foreground generation and text-driven background generation.
Topological GCN for Improving Detection of Hip Landmarks from B-Mode Ultrasound Images
Aug 24, 2024



The B-mode ultrasound based computer-aided diagnosis (CAD) has demonstrated its effectiveness for diagnosis of Developmental Dysplasia of the Hip (DDH) in infants. However, due to effect of speckle noise in ultrasound im-ages, it is still a challenge task to accurately detect hip landmarks. In this work, we propose a novel hip landmark detection model by integrating the Topological GCN (TGCN) with an Improved Conformer (TGCN-ICF) into a unified frame-work to improve detection performance. The TGCN-ICF includes two subnet-works: an Improved Conformer (ICF) subnetwork to generate heatmaps and a TGCN subnetwork to additionally refine landmark detection. This TGCN can effectively improve detection accuracy with the guidance of class labels. Moreo-ver, a Mutual Modulation Fusion (MMF) module is developed for deeply ex-changing and fusing the features extracted from the U-Net and Transformer branches in ICF. The experimental results on the real DDH dataset demonstrate that the proposed TGCN-ICF outperforms all the compared algorithms.
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Jun 11, 2024



Recent Diffusion Transformers (DiTs) have shown impressive capabilities in generating high-quality single-modality content, including images, videos, and audio. However, it is still under-explored whether the transformer-based diffuser can efficiently denoise the Gaussian noises towards superb multimodal content creation. To bridge this gap, we introduce AV-DiT, a novel and efficient audio-visual diffusion transformer designed to generate high-quality, realistic videos with both visual and audio tracks. To minimize model complexity and computational costs, AV-DiT utilizes a shared DiT backbone pre-trained on image-only data, with only lightweight, newly inserted adapters being trainable. This shared backbone facilitates both audio and video generation. Specifically, the video branch incorporates a trainable temporal attention layer into a frozen pre-trained DiT block for temporal consistency. Additionally, a small number of trainable parameters adapt the image-based DiT block for audio generation. An extra shared DiT block, equipped with lightweight parameters, facilitates feature interaction between audio and visual modalities, ensuring alignment. Extensive experiments on the AIST++ and Landscape datasets demonstrate that AV-DiT achieves state-of-the-art performance in joint audio-visual generation with significantly fewer tunable parameters. Furthermore, our results highlight that a single shared image generative backbone with modality-specific adaptations is sufficient for constructing a joint audio-video generator. Our source code and pre-trained models will be released.
FINEMATCH: Aspect-based Fine-grained Image and Text Mismatch Detection and Correction
Apr 23, 2024



Recent progress in large-scale pre-training has led to the development of advanced vision-language models (VLMs) with remarkable proficiency in comprehending and generating multimodal content. Despite the impressive ability to perform complex reasoning for VLMs, current models often struggle to effectively and precisely capture the compositional information on both the image and text sides. To address this, we propose FineMatch, a new aspect-based fine-grained text and image matching benchmark, focusing on text and image mismatch detection and correction. This benchmark introduces a novel task for boosting and evaluating the VLMs' compositionality for aspect-based fine-grained text and image matching. In this task, models are required to identify mismatched aspect phrases within a caption, determine the aspect's class, and propose corrections for an image-text pair that may contain between 0 and 3 mismatches. To evaluate the models' performance on this new task, we propose a new evaluation metric named ITM-IoU for which our experiments show a high correlation to human evaluation. In addition, we also provide a comprehensive experimental analysis of existing mainstream VLMs, including fully supervised learning and in-context learning settings. We have found that models trained on FineMatch demonstrate enhanced proficiency in detecting fine-grained text and image mismatches. Moreover, models (e.g., GPT-4V, Gemini Pro Vision) with strong abilities to perform multimodal in-context learning are not as skilled at fine-grained compositional image and text matching analysis. With FineMatch, we are able to build a system for text-to-image generation hallucination detection and correction.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Mar 14, 2024



We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen