 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through Words: Controlling Visual Retrieval Quality with Language Models
Feb 24, 2026Text-to-image retrieval is a fundamental task in vision-language learning, yet in real-world scenarios it is often challenged by short and underspecified user queries. Such queries are typically only one or two words long, rendering them semantically ambiguous, prone to collisions across diverse visual interpretations, and lacking explicit control over the quality of retrieved images. To address these issues, we propose a new paradigm of quality-controllable retrieval, which enriches short queries with contextual details while incorporating explicit notions of image quality. Our key idea is to leverage a generative language model as a query completion function, extending underspecified queries into descriptive forms that capture fine-grained visual attributes such as pose, scene, and aesthetics. We introduce a general framework that conditions query completion on discretized quality levels, derived from relevance and aesthetic scoring models, so that query enrichment is not only semantically meaningful but also quality-aware. The resulting system provides three key advantages: 1) flexibility, it is compatible with any pretrained vision-language model (VLMs) without modification; 2) transparency, enriched queries are explicitly interpretable by users; and 3) controllability, enabling retrieval results to be steered toward user-preferred quality levels. Extensive experiments demonstrate that our proposed approach significantly improves retrieval results and provides effective quality control, bridging the gap between the expressive capacity of modern VLMs and the underspecified nature of short user queries. Our code is available at https://github.com/Jianglin954/QCQC.
RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward
Feb 19, 2026Recent advances in multimodal large language models (MLLMs) have shown great potential for extending vision-language reasoning to professional tool-based image editing, enabling intuitive and creative editing. A promising direction is to use reinforcement learning (RL) to enable MLLMs to reason about and execute optimal tool-use plans within professional image-editing software. However, training remains challenging due to the lack of reliable, verifiable reward signals that can reflect the inherently subjective nature of creative editing. In this work, we introduce RetouchIQ, a framework that performs instruction-based executable image editing through MLLM agents guided by a generalist reward model. RetouchIQ interprets user-specified editing intentions and generates corresponding, executable image adjustments, bridging high-level aesthetic goals with precise parameter control. To move beyond conventional, rule-based rewards that compute similarity against a fixed reference image using handcrafted metrics, we propose a generalist reward model, an RL fine-tuned MLLM that evaluates edited results through a set of generated metrics on a case-by-case basis. Then, the reward model provides scalar feedback through multimodal reasoning, enabling reinforcement learning with high-quality, instruction-consistent gradients. We curate an extended dataset with 190k instruction-reasoning pairs and establish a new benchmark for instruction-based image editing. Experiments show that RetouchIQ substantially improves both semantic consistency and perceptual quality over previous MLLM-based and diffusion-based editing systems. Our findings demonstrate the potential of generalist reward-driven MLLM agents as flexible, explainable, and executable assistants for professional image editing.
More Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt Ensembles
Sep 10, 2025Multimodal large language models (MLLMs) are increasingly used to evaluate text-to-image (TTI) generation systems, providing automated judgments based on visual and textual context. However, these "judge" models often suffer from biases, overconfidence, and inconsistent performance across diverse image domains. While prompt ensembling has shown promise for mitigating these issues in unimodal, text-only settings, our experiments reveal that standard ensembling methods fail to generalize effectively for TTI tasks. To address these limitations, we propose a new multimodal-aware method called Multimodal Mixture-of-Bayesian Prompt Ensembles (MMB). Our method uses a Bayesian prompt ensemble approach augmented by image clustering, allowing the judge to dynamically assign prompt weights based on the visual characteristics of each sample. We show that MMB improves accuracy in pairwise preference judgments and greatly enhances calibration, making it easier to gauge the judge's true uncertainty. In evaluations on two TTI benchmarks, HPSv2 and MJBench, MMB outperforms existing baselines in alignment with human annotations and calibration across varied image content. Our findings highlight the importance of multimodal-specific strategies for judge calibration and suggest a promising path forward for reliable large-scale TTI evaluation.
Plot'n Polish: Zero-shot Story Visualization and Disentangled Editing with Text-to-Image Diffusion Models
Sep 04, 2025Text-to-image diffusion models have demonstrated significant capabilities to generate diverse and detailed visuals in various domains, and story visualization is emerging as a particularly promising application. However, as their use in real-world creative domains increases, the need for providing enhanced control, refinement, and the ability to modify images post-generation in a consistent manner becomes an important challenge. Existing methods often lack the flexibility to apply fine or coarse edits while maintaining visual and narrative consistency across multiple frames, preventing creators from seamlessly crafting and refining their visual stories. To address these challenges, we introduce Plot'n Polish, a zero-shot framework that enables consistent story generation and provides fine-grained control over story visualizations at various levels of detail.
MS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
Jun 14, 2025We study multi-modal summarization for instructional videos, whose goal is to provide users an efficient way to learn skills in the form of text instructions and key video frames. We observe that existing benchmarks focus on generic semantic-level video summarization, and are not suitable for providing step-by-step executable instructions and illustrations, both of which are crucial for instructional videos. We propose a novel benchmark for user interface (UI) instructional video summarization to fill the gap. We collect a dataset of 2,413 UI instructional videos, which spans over 167 hours. These videos are manually annotated for video segmentation, text summarization, and video summarization, which enable the comprehensive evaluations for concise and executable video summarization. We conduct extensive experiments on our collected MS4UI dataset, which suggest that state-of-the-art multi-modal summarization methods struggle on UI video summarization, and highlight the importance of new methods for UI instructional video summarization.
MAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
Jan 15, 2025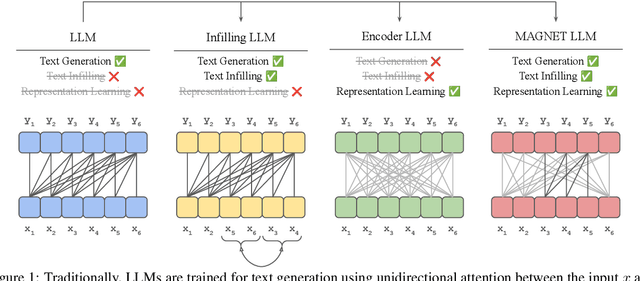
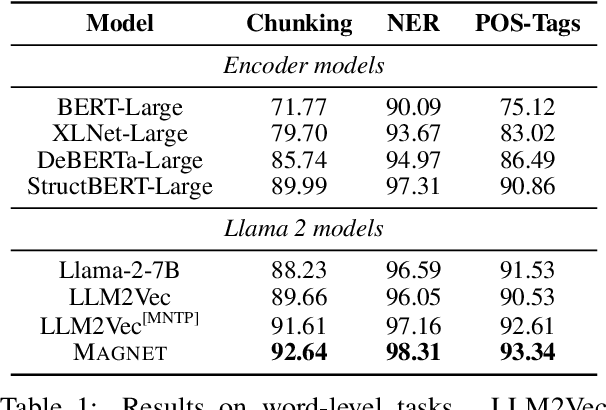
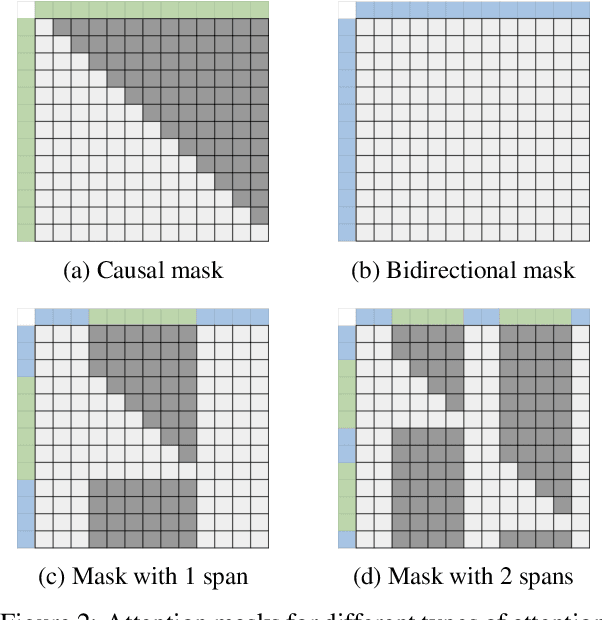
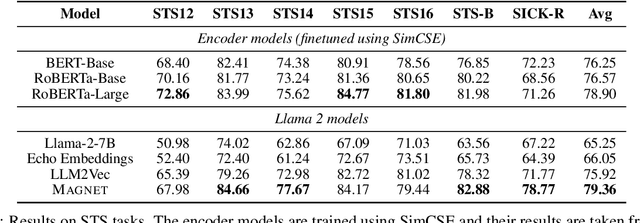
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning, respectively). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we introduce MAGNET, an adaptation of decoder-only LLMs that enhances their ability to generate robust representations and infill missing text spans, while preserving their knowledge and text generation capabilities. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging future context, (3) retain the ability for open-ended text generation without exhibiting repetition problem, and (4) preserve the knowledge gained by the LLM during pretraining.
Revisiting Multi-Modal LLM Evaluation
Aug 09, 2024



With the advent of multi-modal large language models (MLLMs), datasets used for visual question answering (VQA) and referring expression comprehension have seen a resurgence. However, the most popular datasets used to evaluate MLLMs are some of the earliest ones created, and they have many known problems, including extreme bias, spurious correlations, and an inability to permit fine-grained analysis. In this paper, we pioneer evaluating recent MLLMs (LLaVA 1.5, LLaVA-NeXT, BLIP2, InstructBLIP, GPT-4V, and GPT-4o) on datasets designed to address weaknesses in earlier ones. We assess three VQA datasets: 1) TDIUC, which permits fine-grained analysis on 12 question types; 2) TallyQA, which has simple and complex counting questions; and 3) DVQA, which requires optical character recognition for chart understanding. We also study VQDv1, a dataset that requires identifying all image regions that satisfy a given query. Our experiments reveal the weaknesses of many MLLMs that have not previously been reported. Our code is integrated into the widely used LAVIS framework for MLLM evaluation, enabling the rapid assessment of future MLLMs. Project webpage: https://kevinlujian.github.io/MLLM_Evaluations/
They're All Doctors: Synthesizing Diverse Counterfactuals to Mitigate Associative Bias
Jun 17, 2024Vision Language Models (VLMs) such as CLIP are powerful models; however they can exhibit unwanted biases, making them less safe when deployed directly in applications such as text-to-image, text-to-video retrievals, reverse search, or classification tasks. In this work, we propose a novel framework to generate synthetic counterfactual images to create a diverse and balanced dataset that can be used to fine-tune CLIP. Given a set of diverse synthetic base images from text-to-image models, we leverage off-the-shelf segmentation and inpainting models to place humans with diverse visual appearances in context. We show that CLIP trained on such datasets learns to disentangle the human appearance from the context of an image, i.e., what makes a doctor is not correlated to the person's visual appearance, like skin color or body type, but to the context, such as background, the attire they are wearing, or the objects they are holding. We demonstrate that our fine-tuned CLIP model, $CF_\alpha$, improves key fairness metrics such as MaxSkew, MinSkew, and NDKL by 40-66\% for image retrieval tasks, while still achieving similar levels of performance in downstream tasks. We show that, by design, our model retains maximal compatibility with the original CLIP models, and can be easily controlled to support different accuracy versus fairness trade-offs in a plug-n-play fashion.
FairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset Deduplication
Apr 24, 2024



Recent dataset deduplication techniques have demonstrated that content-aware dataset pruning can dramatically reduce the cost of training Vision-Language Pretrained (VLP) models without significant performance losses compared to training on the original dataset. These results have been based on pruning commonly used image-caption datasets collected from the web -- datasets that are known to harbor harmful social biases that may then be codified in trained models. In this work, we evaluate how deduplication affects the prevalence of these biases in the resulting trained models and introduce an easy-to-implement modification to the recent SemDeDup algorithm that can reduce the negative effects that we observe. When examining CLIP-style models trained on deduplicated variants of LAION-400M, we find our proposed FairDeDup algorithm consistently leads to improved fairness metrics over SemDeDup on the FairFace and FACET datasets while maintaining zero-shot performance on CLIP benchmarks.