 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLMMPR:Deep Learning-based Measurement Matrix for Phase Retrieval
Nov 16, 2025



This paper pioneers the integration of learning optimization into measurement matrix design for phase retrieval. We introduce the Deep Learning-based Measurement Matrix for Phase Retrieval (DLMMPR) algorithm, which parameterizes the measurement matrix within an end-to-end deep learning architecture. Synergistically augmented with subgradient descent and proximal mapping modules for robust recovery, DLMMPR's efficacy is decisively confirmed through comprehensive empirical validation across diverse noise regimes. Benchmarked against DeepMMSE and PrComplex, our method yields substantial gains in PSNR and SSIM, underscoring its superiority.
ProAV-DiT: A Projected Latent Diffusion Transformer for Efficient Synchronized Audio-Video Generation
Nov 15, 2025Sounding Video Generation (SVG) remains a challenging task due to the inherent structural misalignment between audio and video, as well as the high computational cost of multimodal data processing. In this paper, we introduce ProAV-DiT, a Projected Latent Diffusion Transformer designed for efficient and synchronized audio-video generation. To address structural inconsistencies, we preprocess raw audio into video-like representations, aligning both the temporal and spatial dimensions between audio and video. At its core, ProAV-DiT adopts a Multi-scale Dual-stream Spatio-Temporal Autoencoder (MDSA), which projects both modalities into a unified latent space using orthogonal decomposition, enabling fine-grained spatiotemporal modeling and semantic alignment. To further enhance temporal coherence and modality-specific fusion, we introduce a multi-scale attention mechanism, which consists of multi-scale temporal self-attention and group cross-modal attention. Furthermore, we stack the 2D latents from MDSA into a unified 3D latent space, which is processed by a spatio-temporal diffusion Transformer. This design efficiently models spatiotemporal dependencies, enabling the generation of high-fidelity synchronized audio-video content while reducing computational overhead. Extensive experiments conducted on standard benchmarks demonstrate that ProAV-DiT outperforms existing methods in both generation quality and computational efficiency.
Textual Self-attention Network: Test-Time Preference Optimization through Textual Gradient-based Attention
Nov 10, 2025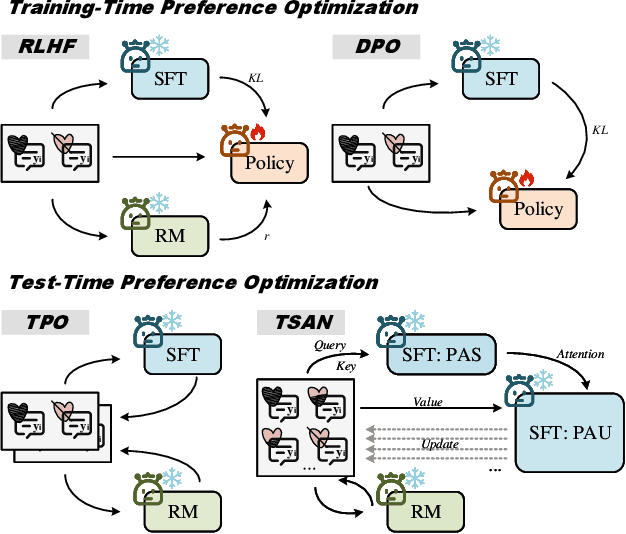
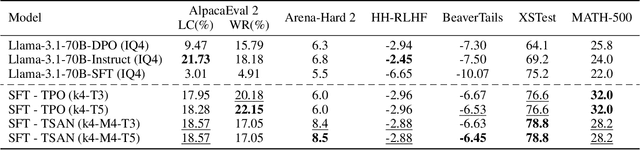
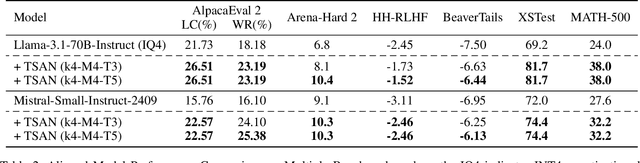
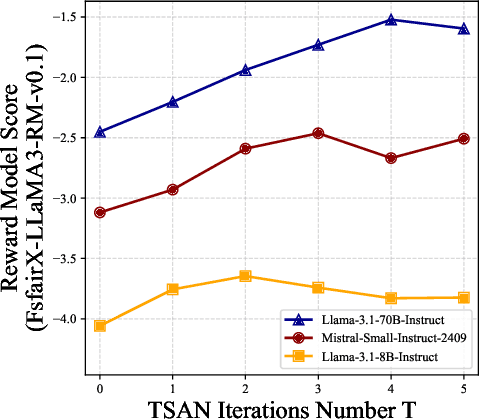
Large Language Models (LLMs) have demonstrated remarkable generalization capabilities, but aligning their outputs with human preferences typically requires expensive supervised fine-tuning. Recent test-time methods leverage textual feedback to overcome this, but they often critique and revise a single candidate response, lacking a principled mechanism to systematically analyze, weigh, and synthesize the strengths of multiple promising candidates. Such a mechanism is crucial because different responses may excel in distinct aspects (e.g., clarity, factual accuracy, or tone), and combining their best elements may produce a far superior outcome. This paper proposes the Textual Self-Attention Network (TSAN), a new paradigm for test-time preference optimization that requires no parameter updates. TSAN emulates self-attention entirely in natural language to overcome this gap: it analyzes multiple candidates by formatting them into textual keys and values, weighs their relevance using an LLM-based attention module, and synthesizes their strengths into a new, preference-aligned response under the guidance of the learned textual attention. This entire process operates in a textual gradient space, enabling iterative and interpretable optimization. Empirical evaluations demonstrate that with just three test-time iterations on a base SFT model, TSAN outperforms supervised models like Llama-3.1-70B-Instruct and surpasses the current state-of-the-art test-time alignment method by effectively leveraging multiple candidate solutions.
C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Oct 23, 2025Embodied agents are expected to perform object navigation in dynamic, open-world environments. However, existing approaches typically rely on static trajectories and a fixed set of object categories during training, overlooking the real-world requirement for continual adaptation to evolving scenarios. To facilitate related studies, we introduce the continual object navigation benchmark, which requires agents to acquire navigation skills for new object categories while avoiding catastrophic forgetting of previously learned knowledge. To tackle this challenge, we propose C-Nav, a continual visual navigation framework that integrates two key innovations: (1) A dual-path anti-forgetting mechanism, which comprises feature distillation that aligns multi-modal inputs into a consistent representation space to ensure representation consistency, and feature replay that retains temporal features within the action decoder to ensure policy consistency. (2) An adaptive sampling strategy that selects diverse and informative experiences, thereby reducing redundancy and minimizing memory overhead. Extensive experiments across multiple model architectures demonstrate that C-Nav consistently outperforms existing approaches, achieving superior performance even compared to baselines with full trajectory retention, while significantly lowering memory requirements. The code will be publicly available at https://bigtree765.github.io/C-Nav-project.
RealClass: A Framework for Classroom Speech Simulation with Public Datasets and Game Engines
Oct 01, 2025The scarcity of large-scale classroom speech data has hindered the development of AI-driven speech models for education. Classroom datasets remain limited and not publicly available, and the absence of dedicated classroom noise or Room Impulse Response (RIR) corpora prevents the use of standard data augmentation techniques. In this paper, we introduce a scalable methodology for synthesizing classroom noise and RIRs using game engines, a versatile framework that can extend to other domains beyond the classroom. Building on this methodology, we present RealClass, a dataset that combines a synthesized classroom noise corpus with a classroom speech dataset compiled from publicly available corpora. The speech data pairs a children's speech corpus with instructional speech extracted from YouTube videos to approximate real classroom interactions in clean conditions. Experiments on clean and noisy speech show that RealClass closely approximates real classroom speech, making it a valuable asset in the absence of abundant real classroom speech.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025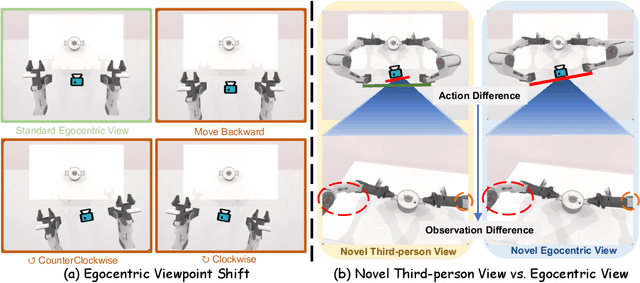

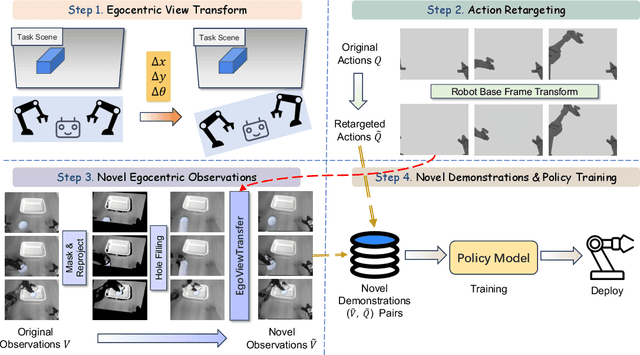
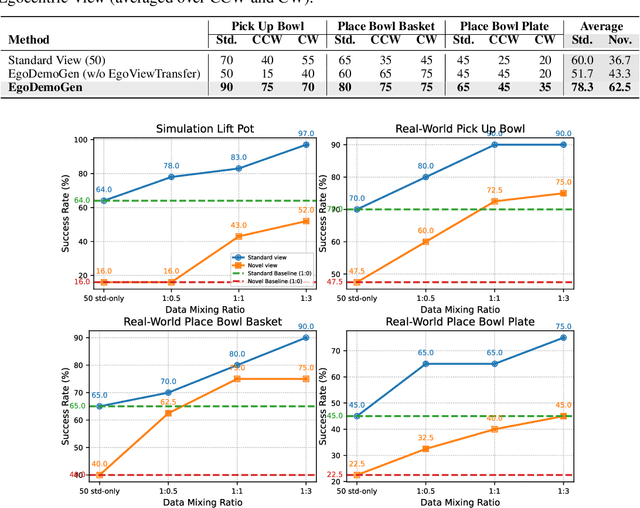
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
Lynx: Towards High-Fidelity Personalized Video Generation
Sep 19, 2025We present Lynx, a high-fidelity model for personalized video synthesis from a single input image. Built on an open-source Diffusion Transformer (DiT) foundation model, Lynx introduces two lightweight adapters to ensure identity fidelity. The ID-adapter employs a Perceiver Resampler to convert ArcFace-derived facial embeddings into compact identity tokens for conditioning, while the Ref-adapter integrates dense VAE features from a frozen reference pathway, injecting fine-grained details across all transformer layers through cross-attention. These modules collectively enable robust identity preservation while maintaining temporal coherence and visual realism. Through evaluation on a curated benchmark of 40 subjects and 20 unbiased prompts, which yielded 800 test cases, Lynx has demonstrated superior face resemblance, competitive prompt following, and strong video quality, thereby advancing the state of personalized video generation.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
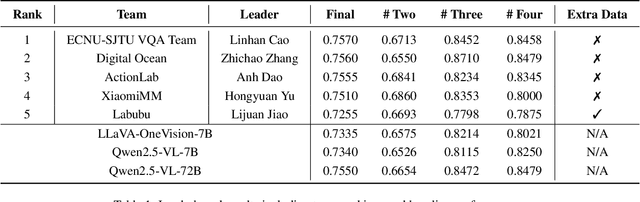
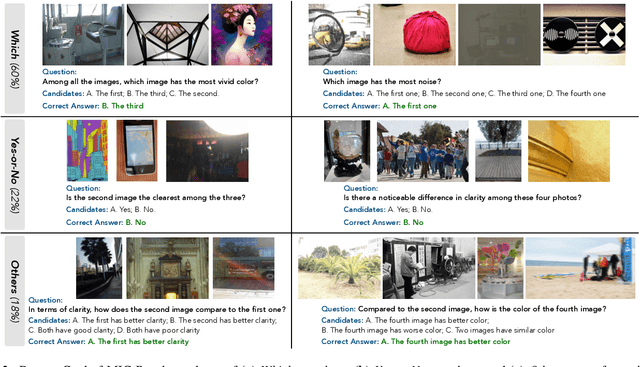
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
AniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025


We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.