 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLynx: Towards High-Fidelity Personalized Video Generation
Sep 19, 2025We present Lynx, a high-fidelity model for personalized video synthesis from a single input image. Built on an open-source Diffusion Transformer (DiT) foundation model, Lynx introduces two lightweight adapters to ensure identity fidelity. The ID-adapter employs a Perceiver Resampler to convert ArcFace-derived facial embeddings into compact identity tokens for conditioning, while the Ref-adapter integrates dense VAE features from a frozen reference pathway, injecting fine-grained details across all transformer layers through cross-attention. These modules collectively enable robust identity preservation while maintaining temporal coherence and visual realism. Through evaluation on a curated benchmark of 40 subjects and 20 unbiased prompts, which yielded 800 test cases, Lynx has demonstrated superior face resemblance, competitive prompt following, and strong video quality, thereby advancing the state of personalized video generation.
CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration
Apr 17, 2024



Reconstructing degraded images is a critical task in image processing. Although CNN and Transformer-based models are prevalent in this field, they exhibit inherent limitations, such as inadequate long-range dependency modeling and high computational costs. To overcome these issues, we introduce the Channel-Aware U-Shaped Mamba (CU-Mamba) model, which incorporates a dual State Space Model (SSM) framework into the U-Net architecture. CU-Mamba employs a Spatial SSM module for global context encoding and a Channel SSM component to preserve channel correlation features, both in linear computational complexity relative to the feature map size. Extensive experimental results validate CU-Mamba's superiority over existing state-of-the-art methods, underscoring the importance of integrating both spatial and channel contexts in image restoration.
Duolando: Follower GPT with Off-Policy Reinforcement Learning for Dance Accompaniment
Mar 27, 2024



We introduce a novel task within the field of 3D dance generation, termed dance accompaniment, which necessitates the generation of responsive movements from a dance partner, the "follower", synchronized with the lead dancer's movements and the underlying musical rhythm. Unlike existing solo or group dance generation tasks, a duet dance scenario entails a heightened degree of interaction between the two participants, requiring delicate coordination in both pose and position. To support this task, we first build a large-scale and diverse duet interactive dance dataset, DD100, by recording about 117 minutes of professional dancers' performances. To address the challenges inherent in this task, we propose a GPT-based model, Duolando, which autoregressively predicts the subsequent tokenized motion conditioned on the coordinated information of the music, the leader's and the follower's movements. To further enhance the GPT's capabilities of generating stable results on unseen conditions (music and leader motions), we devise an off-policy reinforcement learning strategy that allows the model to explore viable trajectories from out-of-distribution samplings, guided by human-defined rewards. Based on the collected dataset and proposed method, we establish a benchmark with several carefully designed metrics.
Deep Geometrized Cartoon Line Inbetweening
Sep 28, 2023



We aim to address a significant but understudied problem in the anime industry, namely the inbetweening of cartoon line drawings. Inbetweening involves generating intermediate frames between two black-and-white line drawings and is a time-consuming and expensive process that can benefit from automation. However, existing frame interpolation methods that rely on matching and warping whole raster images are unsuitable for line inbetweening and often produce blurring artifacts that damage the intricate line structures. To preserve the precision and detail of the line drawings, we propose a new approach, AnimeInbet, which geometrizes raster line drawings into graphs of endpoints and reframes the inbetweening task as a graph fusion problem with vertex repositioning. Our method can effectively capture the sparsity and unique structure of line drawings while preserving the details during inbetweening. This is made possible via our novel modules, i.e., vertex geometric embedding, a vertex correspondence Transformer, an effective mechanism for vertex repositioning and a visibility predictor. To train our method, we introduce MixamoLine240, a new dataset of line drawings with ground truth vectorization and matching labels. Our experiments demonstrate that AnimeInbet synthesizes high-quality, clean, and complete intermediate line drawings, outperforming existing methods quantitatively and qualitatively, especially in cases with large motions. Data and code are available at https://github.com/lisiyao21/AnimeInbet.
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion
Mar 25, 2022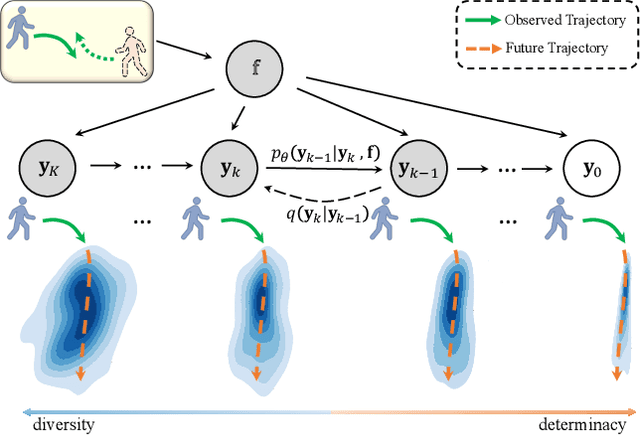
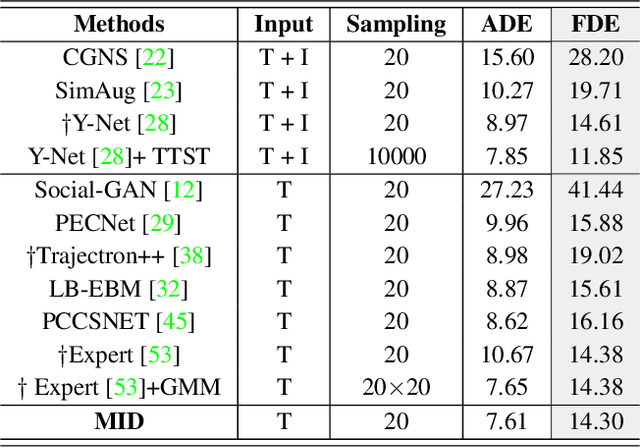
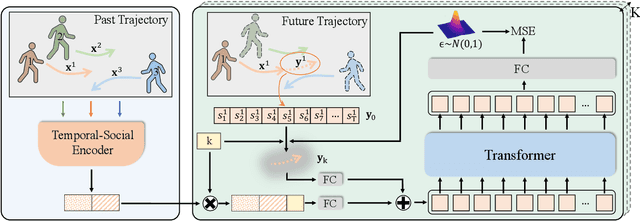
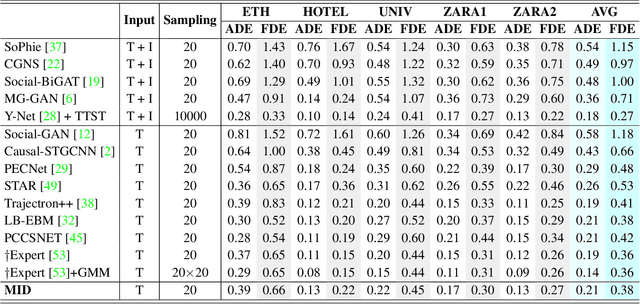
Human behavior has the nature of indeterminacy, which requires the pedestrian trajectory prediction system to model the multi-modality of future motion states. Unlike existing stochastic trajectory prediction methods which usually use a latent variable to represent multi-modality, we explicitly simulate the process of human motion variation from indeterminate to determinate. In this paper, we present a new framework to formulate the trajectory prediction task as a reverse process of motion indeterminacy diffusion (MID), in which we progressively discard indeterminacy from all the walkable areas until reaching the desired trajectory. This process is learned with a parameterized Markov chain conditioned by the observed trajectories. We can adjust the length of the chain to control the degree of indeterminacy and balance the diversity and determinacy of the predictions. Specifically, we encode the history behavior information and the social interactions as a state embedding and devise a Transformer-based diffusion model to capture the temporal dependencies of trajectories. Extensive experiments on the human trajectory prediction benchmarks including the Stanford Drone and ETH/UCY datasets demonstrate the superiority of our method. Code is available at https://github.com/gutianpei/MID.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022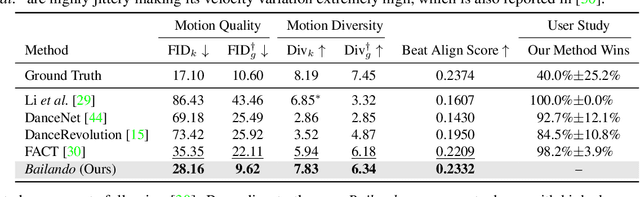
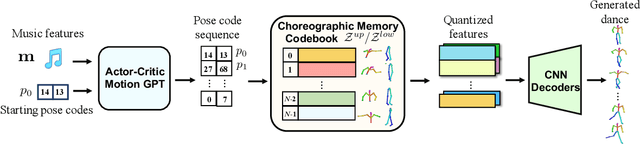
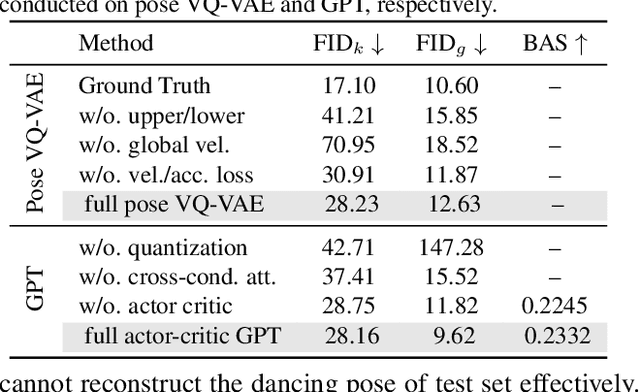
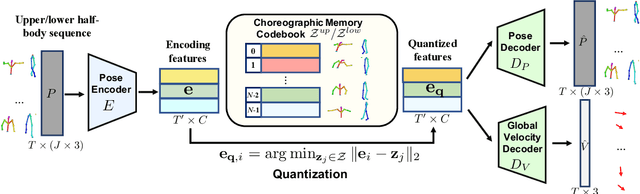
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
Person Re-identification via Attention Pyramid
Aug 11, 2021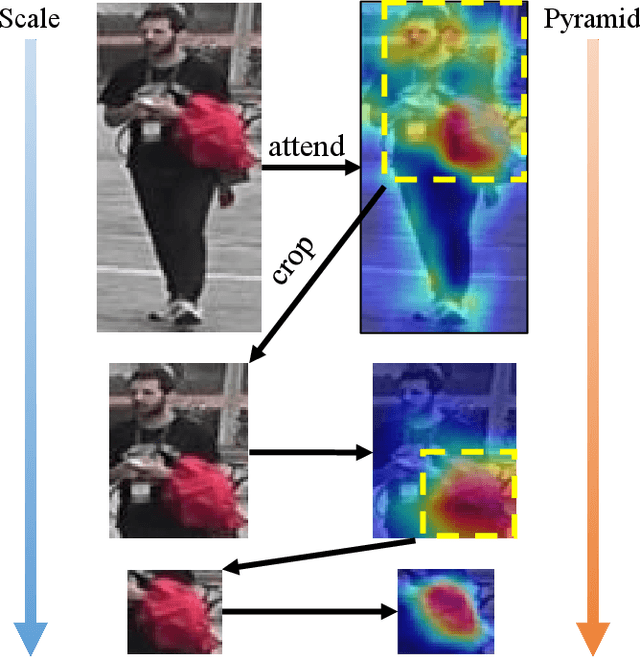
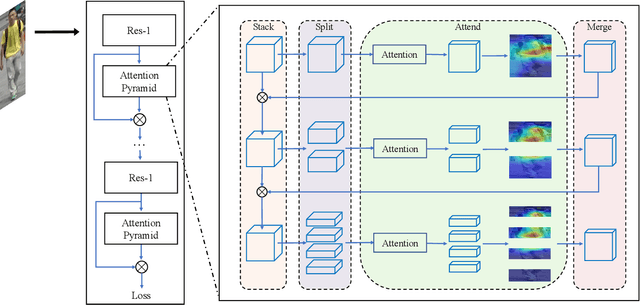
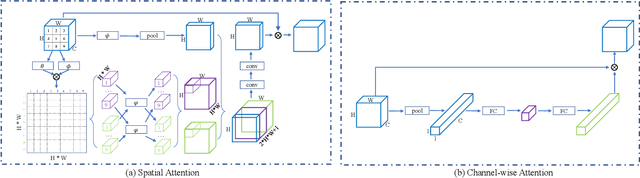
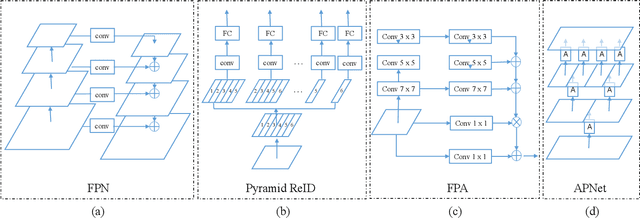
In this paper, we propose an attention pyramid method for person re-identification. Unlike conventional attention-based methods which only learn a global attention map, our attention pyramid exploits the attention regions in a multi-scale manner because human attention varies with different scales. Our attention pyramid imitates the process of human visual perception which tends to notice the foreground person over the cluttered background, and further focus on the specific color of the shirt with close observation. Specifically, we describe our attention pyramid by a "split-attend-merge-stack" principle. We first split the features into multiple local parts and learn the corresponding attentions. Then, we merge local attentions and stack these merged attentions with the residual connection as an attention pyramid. The proposed attention pyramid is a lightweight plug-and-play module that can be applied to off-the-shelf models. We implement our attention pyramid method in two different attention mechanisms including channel-wise attention and spatial attention. We evaluate our method on four largescale person re-identification benchmarks including Market-1501, DukeMTMC, CUHK03, and MSMT17. Experimental results demonstrate the superiority of our method, which outperforms the state-of-the-art methods by a large margin with limited computational cost.