 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Recovery Matters: The Blind Spot of Surrogate Privacy in MLLM Editing
Jun 05, 2026Multimodal Large Language Models (MLLMs) enable flexible instruction-driven image editing, but privacy risks arise when user images expose diverse and user-specific private content. Canonical privacy protection strategies typically substitute sensitive regions with surrogate content before cloud editing. Yet, the resulting output is often an edited surrogate rather than the desired edited source image, neglecting the local recovery in both design and evaluation scope. To this end, we introduce SPPE (Surrogate-based Privacy-Preserving Editing), the first recovery-oriented benchmark covering 36 fine-grained privacy categories and 65 editing instructions. It defines two complementary tasks: 1) editability assessment, which estimates before cloud interaction whether a surrogate can induce an edit consistent with the original image; and 2) surrogate-to-source edit recovery, which evaluates whether the edited surrogate can be transferred back to the private source with the edit effect preserved. We address each task with a dedicated method: ERMA predicts surrogate editability through instruction-aware multimodal relation modeling, while \method performs cycle-consistent recovery by using the surrogate editing pair as visual edit evidence and the source image as a source-preserving anchor. Experiments on SPPE and InstructPix2Pix show consistent improvements on both tasks. For editability assessment, ERMA improves over the best-performing baselines by 13.9% in SRCC and 12.3% in PLCC. For surrogate-to-source edit recovery, C2E-S2SER outperforms SOER across all 8 source integrity and edit consistency metrics on SPPE.
Seeing Without Exposing: Adaptive Privacy Control for Open-World, Context-Hungry MLLMs
Jun 05, 2026Multimodal large language models (MLLMs) have raised new privacy challenges. On the data side, user-provided inputs often include unpredictable sensitive information; while on the downstream task side, model reasoning depends on rich visual context that may itself be privacy-sensitive. Existing privacy protection methods, however, rely on predefined sensitive categories and fixed obfuscation strategies, struggling to tackle such challenges in MLLMs. To address this dilemma, we propose Anchored Privacy Drifting (APD), a training-free method that drifts privacy-sensitive elements toward semantically equivalent alternatives while anchoring contextual cues to the source image. To systematically evaluate this dual objective of privacy protection and contextual preservation, we introduce AdaptShield, a comprehensive benchmark covering 22 privacy categories, which combines conventional privacy metrics with MLLM-based assessments of contextual utility. Extensive experiments show that our method achieves balanced improvements in both privacy sanitization and content retention, with average gains of 10.4% on textual categories and 8.5% under MLLM-based evaluation across four MLLM series, i.e., Qwen2.5, Qwen3, InternVL3, and InternVL3.5.
RAISE: RAG Design as an Architecture Search Problem
May 28, 2026Retrieval-augmented generation (RAG) systems expose numerous design choices spanning query rewriting, chunking, retrieval depth, reranking, and context compression. In practice, these choices are often configured through heuristics, hindering systematic evaluation and reproducibility across settings. We argue that this challenge is best formulated as RAG architecture search. To support controlled and reproducible study of this problem, we introduce the RAG Intelligence Search Engine (RAISE), a comprehensive framework and benchmark for RAG hyperparameter optimization, which evaluates optimization methods for RAG pipelines under standardized search spaces and budgets. RAISE implements 13 search algorithms and evaluates them across seven public text and multimodal datasets using three random seeds. Our experiments show that optimization performance is highly task-dependent: methods that perform strongly on one dataset may not generalize consistently across others, cautioning against interpreting aggregate rankings as evidence of universally superior strategies. RAISE provides a common experimental substrate for fair, reproducible, and systematic research on RAG hyperparameter optimization.
TIGER: Text-Informed Generalized Enzyme-Reaction Retrieval
May 23, 2026Enzyme-reaction retrieval is a fundamental problem in computational biology, underpinning enzyme characterization, reaction mechanism elucidation, and the rational design of metabolic pathways and biocatalysts. As a bidirectional task, it entails both enzyme-to-reaction and reaction-to-enzyme mapping. However, existing approaches suffer from poor generalization across tasks and distributions, with performance highly sensitive to dataset splits and substantial asymmetry between retrieval directions. To address these challenges, we present TIGER, a Text-Informed Generalized Enzyme-Reaction Retrieval framework that leverages protein-to-text generation models to distill textual semantic knowledge from enzyme sequences, providing a generalized representation that bridges enzymes and biochemical reactions. To ensure the quality and reliability of textual semantics, we design a Dynamic Gating Network that adaptively fuses text-derived knowledge with sequence features, enabling more consistent and informative enzyme representations, while a Structure-Shared Feature Projector aligns enzyme and reaction representations within a unified latent space. Extensive experiments demonstrate that, under bidirectional retrieval supervision, TIGER significantly outperforms state-of-the-art baselines across diverse distributions and exhibits strong robustness and transferability across tasks.
Orion-RAG: Path-Aligned Hybrid Retrieval for Graphless Data
Jan 08, 2026Retrieval-Augmented Generation (RAG) has proven effective for knowledge synthesis, yet it encounters significant challenges in practical scenarios where data is inherently discrete and fragmented. In most environments, information is distributed across isolated files like reports and logs that lack explicit links. Standard search engines process files independently, ignoring the connections between them. Furthermore, manually building Knowledge Graphs is impractical for such vast data. To bridge this gap, we present Orion-RAG. Our core insight is simple yet effective: we do not need heavy algorithms to organize this data. Instead, we use a low-complexity strategy to extract lightweight paths that naturally link related concepts. We demonstrate that this streamlined approach suffices to transform fragmented documents into semi-structured data, enabling the system to link information across different files effectively. Extensive experiments demonstrate that Orion-RAG consistently outperforms mainstream frameworks across diverse domains, supporting real-time updates and explicit Human-in-the-Loop verification with high cost-efficiency. Experiments on FinanceBench demonstrate superior precision with a 25.2% relative improvement over strong baselines.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
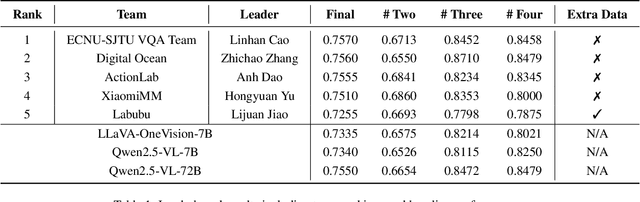
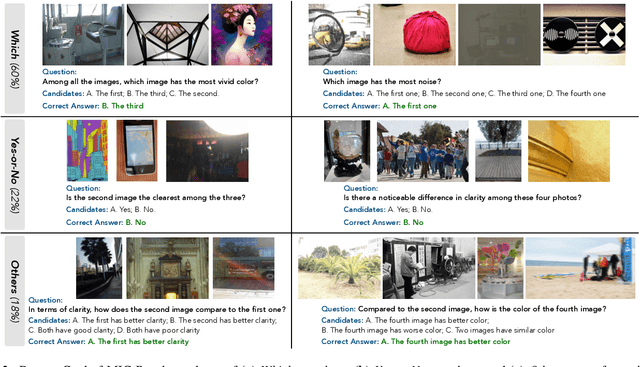
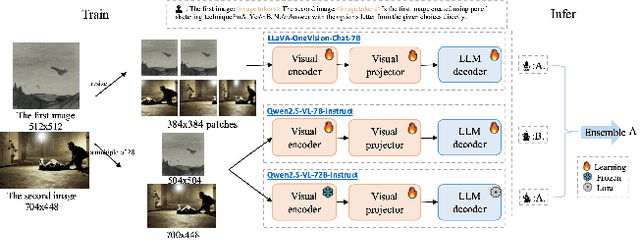
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Copyright Protection for 3D Molecular Structures with Watermarking
Aug 25, 2025



Artificial intelligence (AI) revolutionizes molecule generation in bioengineering and biological research, significantly accelerating discovery processes. However, this advancement introduces critical concerns regarding intellectual property protection. To address these challenges, we propose the first robust watermarking method designed for molecules, which utilizes atom-level features to preserve molecular integrity and invariant features to ensure robustness against affine transformations. Comprehensive experiments validate the effectiveness of our method using the datasets QM9 and GEOM-DRUG, and generative models GeoBFN and GeoLDM. We demonstrate the feasibility of embedding watermarks, maintaining basic properties higher than 90.00\% while achieving watermark accuracy greater than 95.00\%. Furthermore, downstream docking simulations reveal comparable performance between original and watermarked molecules, with binding affinities reaching -6.00 kcal/mol and root mean square deviations below 1.602 \AA. These results confirm that our watermarking technique effectively safeguards molecular intellectual property without compromising scientific utility, enabling secure and responsible AI integration in molecular discovery and research applications.
KEPLA: A Knowledge-Enhanced Deep Learning Framework for Accurate Protein-Ligand Binding Affinity Prediction
Jun 16, 2025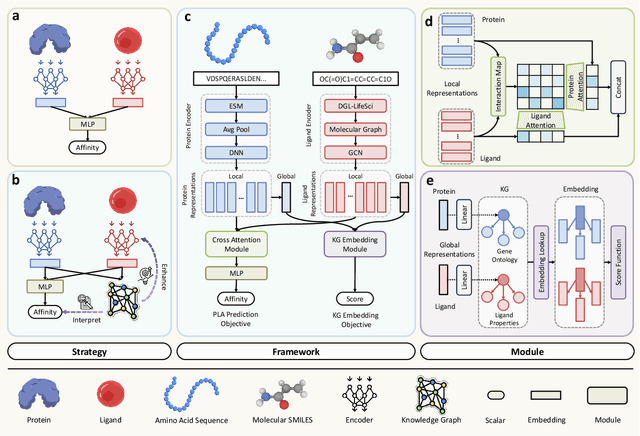
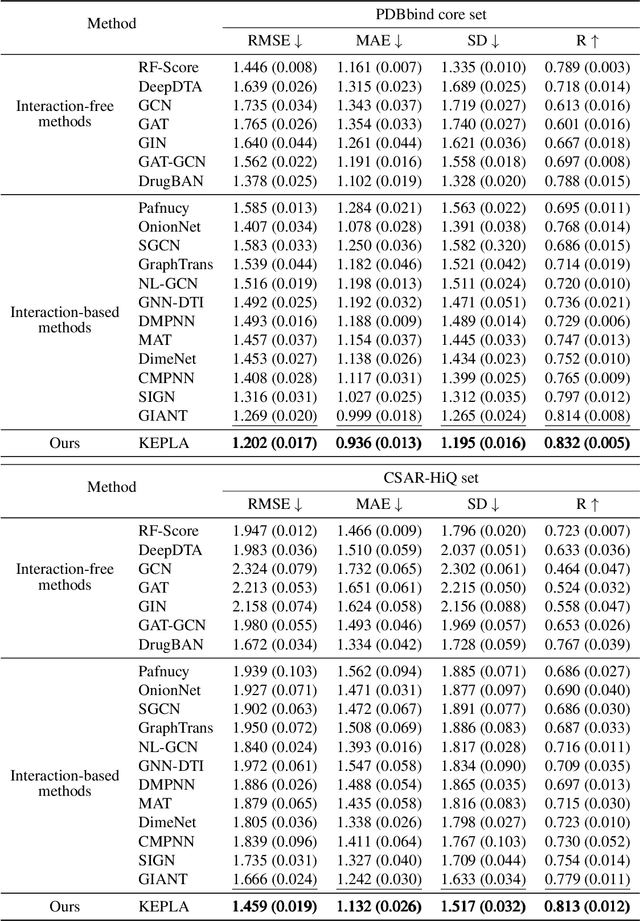
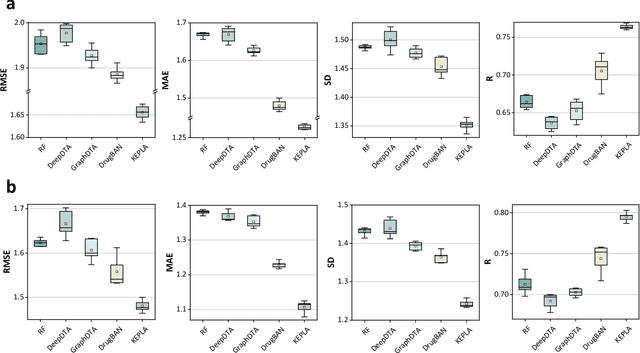
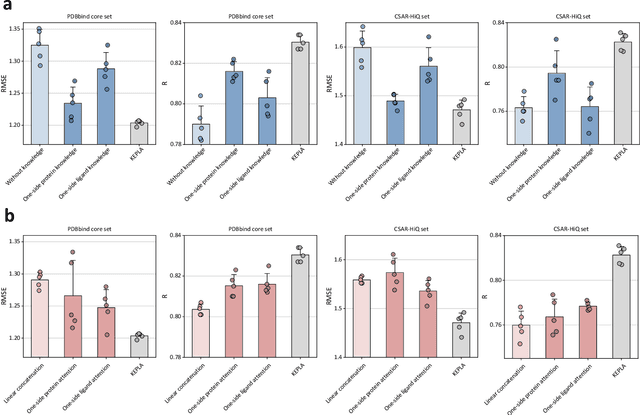
Accurate prediction of protein-ligand binding affinity is critical for drug discovery. While recent deep learning approaches have demonstrated promising results, they often rely solely on structural features, overlooking valuable biochemical knowledge associated with binding affinity. To address this limitation, we propose KEPLA, a novel deep learning framework that explicitly integrates prior knowledge from Gene Ontology and ligand properties of proteins and ligands to enhance prediction performance. KEPLA takes protein sequences and ligand molecular graphs as input and optimizes two complementary objectives: (1) aligning global representations with knowledge graph relations to capture domain-specific biochemical insights, and (2) leveraging cross attention between local representations to construct fine-grained joint embeddings for prediction. Experiments on two benchmark datasets across both in-domain and cross-domain scenarios demonstrate that KEPLA consistently outperforms state-of-the-art baselines. Furthermore, interpretability analyses based on knowledge graph relations and cross attention maps provide valuable insights into the underlying predictive mechanisms.
Fine-Grained Motion Compression and Selective Temporal Fusion for Neural B-Frame Video Coding
Jun 09, 2025With the remarkable progress in neural P-frame video coding, neural B-frame coding has recently emerged as a critical research direction. However, most existing neural B-frame codecs directly adopt P-frame coding tools without adequately addressing the unique challenges of B-frame compression, leading to suboptimal performance. To bridge this gap, we propose novel enhancements for motion compression and temporal fusion for neural B-frame coding. First, we design a fine-grained motion compression method. This method incorporates an interactive dual-branch motion auto-encoder with per-branch adaptive quantization steps, which enables fine-grained compression of bi-directional motion vectors while accommodating their asymmetric bitrate allocation and reconstruction quality requirements. Furthermore, this method involves an interactive motion entropy model that exploits correlations between bi-directional motion latent representations by interactively leveraging partitioned latent segments as directional priors. Second, we propose a selective temporal fusion method that predicts bi-directional fusion weights to achieve discriminative utilization of bi-directional multi-scale temporal contexts with varying qualities. Additionally, this method introduces a hyperprior-based implicit alignment mechanism for contextual entropy modeling. By treating the hyperprior as a surrogate for the contextual latent representation, this mechanism implicitly mitigates the misalignment in the fused bi-directional temporal priors. Extensive experiments demonstrate that our proposed codec outperforms state-of-the-art neural B-frame codecs and achieves comparable or even superior compression performance to the H.266/VVC reference software under random-access configurations.
Leveraging Diffusion Knowledge for Generative Image Compression with Fractal Frequency-Aware Band Learning
Mar 14, 2025By optimizing the rate-distortion-realism trade-off, generative image compression approaches produce detailed, realistic images instead of the only sharp-looking reconstructions produced by rate-distortion-optimized models. In this paper, we propose a novel deep learning-based generative image compression method injected with diffusion knowledge, obtaining the capacity to recover more realistic textures in practical scenarios. Efforts are made from three perspectives to navigate the rate-distortion-realism trade-off in the generative image compression task. First, recognizing the strong connection between image texture and frequency-domain characteristics, we design a Fractal Frequency-Aware Band Image Compression (FFAB-IC) network to effectively capture the directional frequency components inherent in natural images. This network integrates commonly used fractal band feature operations within a neural non-linear mapping design, enhancing its ability to retain essential given information and filter out unnecessary details. Then, to improve the visual quality of image reconstruction under limited bandwidth, we integrate diffusion knowledge into the encoder and implement diffusion iterations into the decoder process, thus effectively recovering lost texture details. Finally, to fully leverage the spatial and frequency intensity information, we incorporate frequency- and content-aware regularization terms to regularize the training of the generative image compression network. Extensive experiments in quantitative and qualitative evaluations demonstrate the superiority of the proposed method, advancing the boundaries of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.