 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Application of Large-scale Pre-trained Models on Adverse Weather Removal
Jun 15, 2023Image restoration under adverse weather conditions (e.g., rain, snow and haze) is a fundamental computer vision problem and has important indications for various downstream applications. Different from early methods that are specially designed for specific type of weather, most recent works tend to remove various adverse weather effects simultaneously through either spatial feature representation learning or semantic information embedding. Inspired by the various successful applications of large-scale pre-trained models (e.g, CLIP), in this paper, we explore the potential benefits of them for this task through both spatial feature representation learning and semantic information embedding aspects: 1) for spatial feature representation learning, we design a Spatially-Adaptive Residual (\textbf{SAR}) Encoder to extract degraded areas adaptively. To facilitate its training, we propose a Soft Residual Distillation (\textbf{CLIP-SRD}) strategy to transfer the spatial knowledge from CLIP between clean and adverse weather images; 2) for semantic information embedding, we propose a CLIP Weather Prior (\textbf{CWP}) embedding module to make the network handle different weather conditions adaptively. This module integrates the sample specific weather prior extracted by CLIP image encoder together with the distribution specific information learned by a set of parameters, and embeds them through a cross attention mechanism. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art performance under different and challenging adverse weather conditions. Code will be made available.
Ultra-High Resolution Segmentation with Ultra-Rich Context: A Novel Benchmark
May 18, 2023



With the increasing interest and rapid development of methods for Ultra-High Resolution (UHR) segmentation, a large-scale benchmark covering a wide range of scenes with full fine-grained dense annotations is urgently needed to facilitate the field. To this end, the URUR dataset is introduced, in the meaning of Ultra-High Resolution dataset with Ultra-Rich Context. As the name suggests, URUR contains amounts of images with high enough resolution (3,008 images of size 5,120x5,120), a wide range of complex scenes (from 63 cities), rich-enough context (1 million instances with 8 categories) and fine-grained annotations (about 80 billion manually annotated pixels), which is far superior to all the existing UHR datasets including DeepGlobe, Inria Aerial, UDD, etc.. Moreover, we also propose WSDNet, a more efficient and effective framework for UHR segmentation especially with ultra-rich context. Specifically, multi-level Discrete Wavelet Transform (DWT) is naturally integrated to release computation burden while preserve more spatial details, along with a Wavelet Smooth Loss (WSL) to reconstruct original structured context and texture with a smooth constrain. Experiments on several UHR datasets demonstrate its state-of-the-art performance. The dataset is available at https://github.com/jankyee/URUR.
Self-Learning Symmetric Multi-view Probabilistic Clustering
May 12, 2023



Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete multi-view clustering. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. Moreover, category information is required in most existing methods, which severely affects the clustering performance. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution from the aspect of consistency in single-view, cross-view and multi-view. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively, in which category information is not required. Extensive experiments on multiple benchmarks for incomplete and complete MVC show that SLS-MPC significantly outperforms previous state-of-the-art methods.
Sim2Rec: A Simulator-based Decision-making Approach to Optimize Real-World Long-term User Engagement in Sequential Recommender Systems
May 03, 2023Long-term user engagement (LTE) optimization in sequential recommender systems (SRS) is shown to be suited by reinforcement learning (RL) which finds a policy to maximize long-term rewards. Meanwhile, RL has its shortcomings, particularly requiring a large number of online samples for exploration, which is risky in real-world applications. One of the appealing ways to avoid the risk is to build a simulator and learn the optimal recommendation policy in the simulator. In LTE optimization, the simulator is to simulate multiple users' daily feedback for given recommendations. However, building a user simulator with no reality-gap, i.e., can predict user's feedback exactly, is unrealistic because the users' reaction patterns are complex and historical logs for each user are limited, which might mislead the simulator-based recommendation policy. In this paper, we present a practical simulator-based recommender policy training approach, Simulation-to-Recommendation (Sim2Rec) to handle the reality-gap problem for LTE optimization. Specifically, Sim2Rec introduces a simulator set to generate various possibilities of user behavior patterns, then trains an environment-parameter extractor to recognize users' behavior patterns in the simulators. Finally, a context-aware policy is trained to make the optimal decisions on all of the variants of the users based on the inferred environment-parameters. The policy is transferable to unseen environments (e.g., the real world) directly as it has learned to recognize all various user behavior patterns and to make the correct decisions based on the inferred environment-parameters. Experiments are conducted in synthetic environments and a real-world large-scale ride-hailing platform, DidiChuxing. The results show that Sim2Rec achieves significant performance improvement, and produces robust recommendations in unseen environments.
Semi-Supervised 2D Human Pose Estimation Driven by Position Inconsistency Pseudo Label Correction Module
Mar 08, 2023



In this paper, we delve into semi-supervised 2D human pose estimation. The previous method ignored two problems: (i) When conducting interactive training between large model and lightweight model, the pseudo label of lightweight model will be used to guide large models. (ii) The negative impact of noise pseudo labels on training. Moreover, the labels used for 2D human pose estimation are relatively complex: keypoint category and keypoint position. To solve the problems mentioned above, we propose a semi-supervised 2D human pose estimation framework driven by a position inconsistency pseudo label correction module (SSPCM). We introduce an additional auxiliary teacher and use the pseudo labels generated by the two teacher model in different periods to calculate the inconsistency score and remove outliers. Then, the two teacher models are updated through interactive training, and the student model is updated using the pseudo labels generated by two teachers. To further improve the performance of the student model, we use the semi-supervised Cut-Occlude based on pseudo keypoint perception to generate more hard and effective samples. In addition, we also proposed a new indoor overhead fisheye human keypoint dataset WEPDTOF-Pose. Extensive experiments demonstrate that our method outperforms the previous best semi-supervised 2D human pose estimation method. We will release the code and dataset at https://github.com/hlz0606/SSPCM.
Provably Efficient Fictitious Play Policy Optimization for Zero-Sum Markov Games with Structured Transitions
Jul 25, 2022
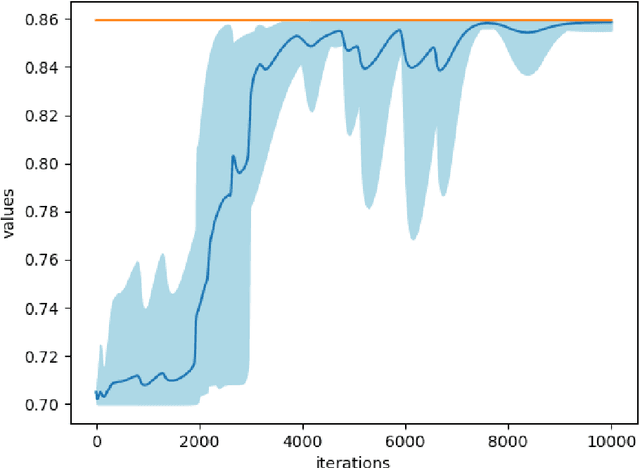
While single-agent policy optimization in a fixed environment has attracted a lot of research attention recently in the reinforcement learning community, much less is known theoretically when there are multiple agents playing in a potentially competitive environment. We take steps forward by proposing and analyzing new fictitious play policy optimization algorithms for zero-sum Markov games with structured but unknown transitions. We consider two classes of transition structures: factored independent transition and single-controller transition. For both scenarios, we prove tight $\widetilde{\mathcal{O}}(\sqrt{K})$ regret bounds after $K$ episodes in a two-agent competitive game scenario. The regret of each agent is measured against a potentially adversarial opponent who can choose a single best policy in hindsight after observing the full policy sequence. Our algorithms feature a combination of Upper Confidence Bound (UCB)-type optimism and fictitious play under the scope of simultaneous policy optimization in a non-stationary environment. When both players adopt the proposed algorithms, their overall optimality gap is $\widetilde{\mathcal{O}}(\sqrt{K})$.
ResNorm: Tackling Long-tailed Degree Distribution Issue in Graph Neural Networks via Normalization
Jun 16, 2022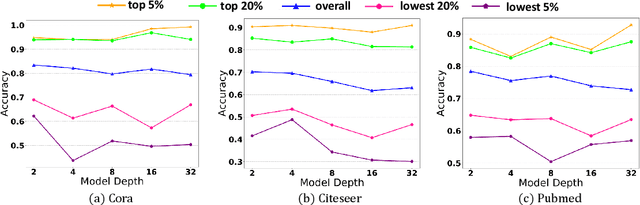
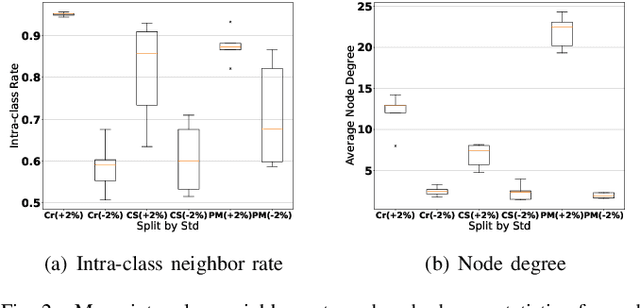
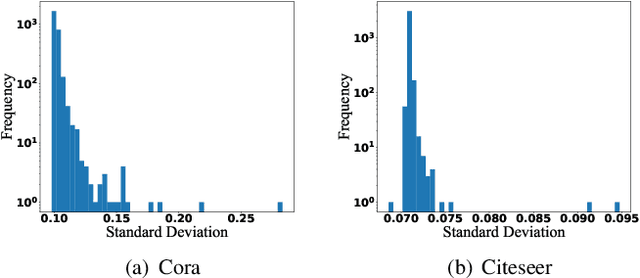
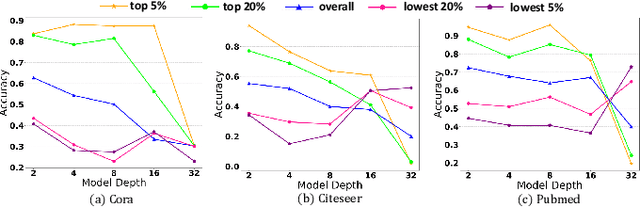
Graph Neural Networks (GNNs) have attracted much attention due to their ability in learning representations from graph-structured data. Despite the successful applications of GNNs in many domains, the optimization of GNNs is less well studied, and the performance on node classification heavily suffers from the long-tailed node degree distribution. This paper focuses on improving the performance of GNNs via normalization. In detail, by studying the long-tailed distribution of node degrees in the graph, we propose a novel normalization method for GNNs, which is termed ResNorm (\textbf{Res}haping the long-tailed distribution into a normal-like distribution via \textbf{norm}alization). The $scale$ operation of ResNorm reshapes the node-wise standard deviation (NStd) distribution so as to improve the accuracy of tail nodes (\textit{i}.\textit{e}., low-degree nodes). We provide a theoretical interpretation and empirical evidence for understanding the mechanism of the above $scale$. In addition to the long-tailed distribution issue, over-smoothing is also a fundamental issue plaguing the community. To this end, we analyze the behavior of the standard shift and prove that the standard shift serves as a preconditioner on the weight matrix, increasing the risk of over-smoothing. With the over-smoothing issue in mind, we design a $shift$ operation for ResNorm that simulates the degree-specific parameter strategy in a low-cost manner. Extensive experiments have validated the effectiveness of ResNorm on several node classification benchmark datasets.
Stochastic Gradient Descent without Full Data Shuffle
Jun 12, 2022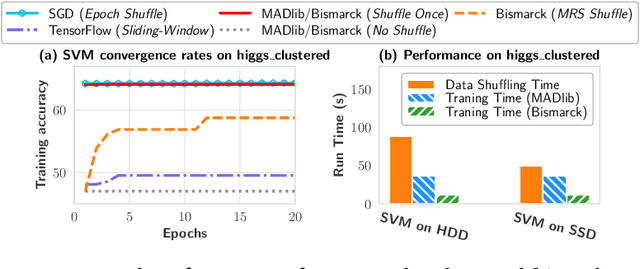

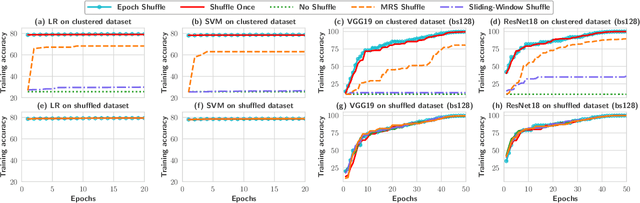
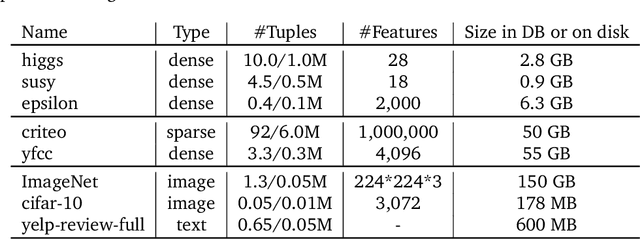
Stochastic gradient descent (SGD) is the cornerstone of modern machine learning (ML) systems. Despite its computational efficiency, SGD requires random data access that is inherently inefficient when implemented in systems that rely on block-addressable secondary storage such as HDD and SSD, e.g., TensorFlow/PyTorch and in-DB ML systems over large files. To address this impedance mismatch, various data shuffling strategies have been proposed to balance the convergence rate of SGD (which favors randomness) and its I/O performance (which favors sequential access). In this paper, we first conduct a systematic empirical study on existing data shuffling strategies, which reveals that all existing strategies have room for improvement -- they all suffer in terms of I/O performance or convergence rate. With this in mind, we propose a simple but novel hierarchical data shuffling strategy, CorgiPile. Compared with existing strategies, CorgiPile avoids a full data shuffle while maintaining comparable convergence rate of SGD as if a full shuffle were performed. We provide a non-trivial theoretical analysis of CorgiPile on its convergence behavior. We further integrate CorgiPile into PyTorch by designing new parallel/distributed shuffle operators inside a new CorgiPileDataSet API. We also integrate CorgiPile into PostgreSQL by introducing three new physical operators with optimizations. Our experimental results show that CorgiPile can achieve comparable convergence rate with the full shuffle based SGD for both deep learning and generalized linear models. For deep learning models on ImageNet dataset, CorgiPile is 1.5X faster than PyTorch with full data shuffle. For in-DB ML with linear models, CorgiPile is 1.6X-12.8X faster than two state-of-the-art in-DB ML systems, Apache MADlib and Bismarck, on both HDD and SSD.
Policy Evaluation for Temporal and/or Spatial Dependent Experiments in Ride-sourcing Platforms
Feb 22, 2022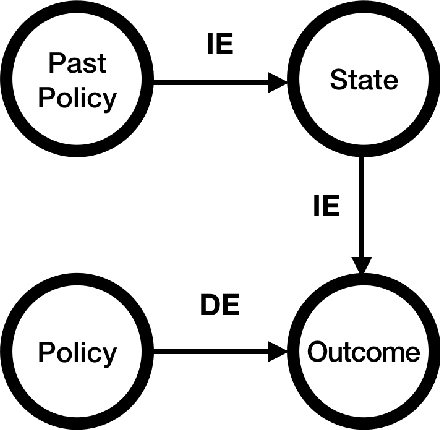
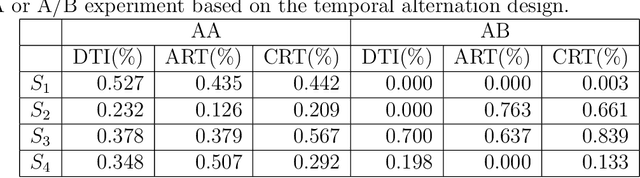
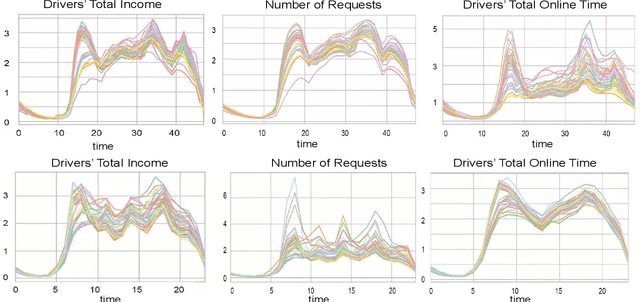

Policy evaluation based on A/B testing has attracted considerable interest in digital marketing, but such evaluation in ride-sourcing platforms (e.g., Uber and Didi) is not well studied primarily due to the complex structure of their temporal and/or spatial dependent experiments. Motivated by policy evaluation in ride-sourcing platforms, the aim of this paper is to establish causal relationship between platform's policies and outcomes of interest under a switchback design. We propose a novel potential outcome framework based on a temporal varying coefficient decision process (VCDP) model to capture the dynamic treatment effects in temporal dependent experiments. We further characterize the average treatment effect by decomposing it as the sum of direct effect (DE) and indirect effect (IE). We develop estimation and inference procedures for both DE and IE. Furthermore, we propose a spatio-temporal VCDP to deal with spatiotemporal dependent experiments. For both VCDP models, we establish the statistical properties (e.g., weak convergence and asymptotic power) of our estimation and inference procedures. We conduct extensive simulations to investigate the finite-sample performance of the proposed estimation and inference procedures. We examine how our VCDP models can help improve policy evaluation for various dispatching and dispositioning policies in Didi.
Rethinking Graph Convolutional Networks in Knowledge Graph Completion
Feb 08, 2022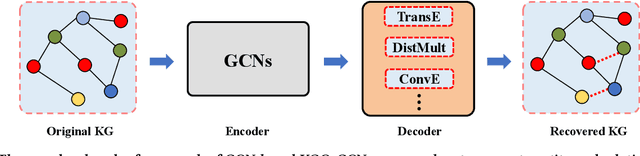

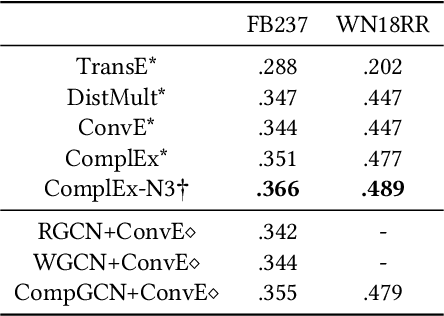
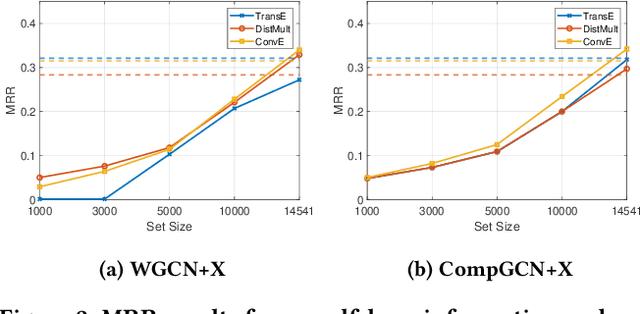
Graph convolutional networks (GCNs) -- which are effective in modeling graph structures -- have been increasingly popular in knowledge graph completion (KGC). GCN-based KGC models first use GCNs to generate expressive entity representations and then use knowledge graph embedding (KGE) models to capture the interactions among entities and relations. However, many GCN-based KGC models fail to outperform state-of-the-art KGE models though introducing additional computational complexity. This phenomenon motivates us to explore the real effect of GCNs in KGC. Therefore, in this paper, we build upon representative GCN-based KGC models and introduce variants to find which factor of GCNs is critical in KGC. Surprisingly, we observe from experiments that the graph structure modeling in GCNs does not have a significant impact on the performance of KGC models, which is in contrast to the common belief. Instead, the transformations for entity representations are responsible for the performance improvements. Based on the observation, we propose a simple yet effective framework named LTE-KGE, which equips existing KGE models with linearly transformed entity embeddings. Experiments demonstrate that LTE-KGE models lead to similar performance improvements with GCN-based KGC methods, while being more computationally efficient. These results suggest that existing GCNs are unnecessary for KGC, and novel GCN-based KGC models should count on more ablation studies to validate their effectiveness. The code of all the experiments is available on GitHub at https://github.com/MIRALab-USTC/GCN4KGC.