 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Rec: A Simulator-based Decision-making Approach to Optimize Real-World Long-term User Engagement in Sequential Recommender Systems
May 03, 2023Long-term user engagement (LTE) optimization in sequential recommender systems (SRS) is shown to be suited by reinforcement learning (RL) which finds a policy to maximize long-term rewards. Meanwhile, RL has its shortcomings, particularly requiring a large number of online samples for exploration, which is risky in real-world applications. One of the appealing ways to avoid the risk is to build a simulator and learn the optimal recommendation policy in the simulator. In LTE optimization, the simulator is to simulate multiple users' daily feedback for given recommendations. However, building a user simulator with no reality-gap, i.e., can predict user's feedback exactly, is unrealistic because the users' reaction patterns are complex and historical logs for each user are limited, which might mislead the simulator-based recommendation policy. In this paper, we present a practical simulator-based recommender policy training approach, Simulation-to-Recommendation (Sim2Rec) to handle the reality-gap problem for LTE optimization. Specifically, Sim2Rec introduces a simulator set to generate various possibilities of user behavior patterns, then trains an environment-parameter extractor to recognize users' behavior patterns in the simulators. Finally, a context-aware policy is trained to make the optimal decisions on all of the variants of the users based on the inferred environment-parameters. The policy is transferable to unseen environments (e.g., the real world) directly as it has learned to recognize all various user behavior patterns and to make the correct decisions based on the inferred environment-parameters. Experiments are conducted in synthetic environments and a real-world large-scale ride-hailing platform, DidiChuxing. The results show that Sim2Rec achieves significant performance improvement, and produces robust recommendations in unseen environments.
Environment Reconstruction with Hidden Confounders for Reinforcement Learning based Recommendation
Jul 12, 2019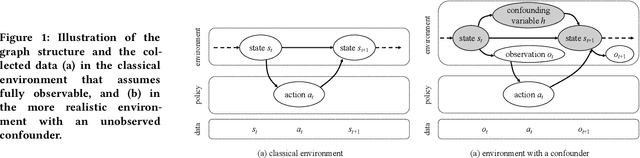
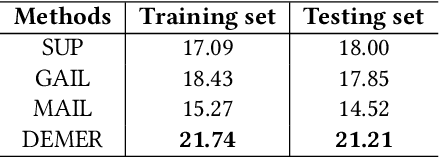
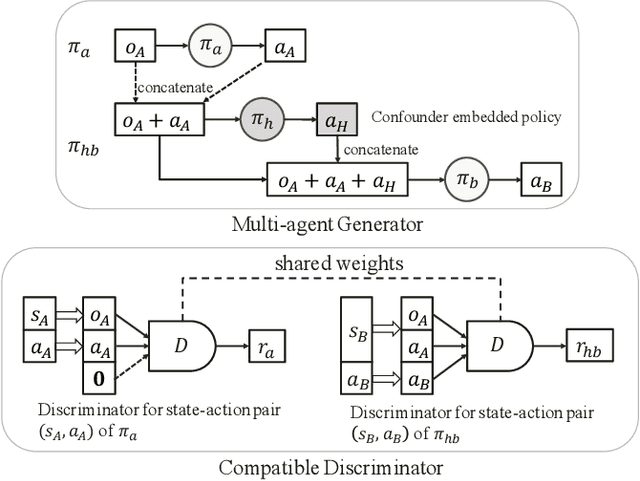
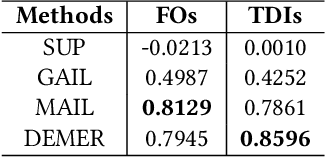
Reinforcement learning aims at searching the best policy model for decision making, and has been shown powerful for sequential recommendations. The training of the policy by reinforcement learning, however, is placed in an environment. In many real-world applications, however, the policy training in the real environment can cause an unbearable cost, due to the exploration in the environment. Environment reconstruction from the past data is thus an appealing way to release the power of reinforcement learning in these applications. The reconstruction of the environment is, basically, to extract the casual effect model from the data. However, real-world applications are often too complex to offer fully observable environment information. Therefore, quite possibly there are unobserved confounding variables lying behind the data. The hidden confounder can obstruct an effective reconstruction of the environment. In this paper, by treating the hidden confounder as a hidden policy, we propose a deconfounded multi-agent environment reconstruction (DEMER) approach in order to learn the environment together with the hidden confounder. DEMER adopts a multi-agent generative adversarial imitation learning framework. It proposes to introduce the confounder embedded policy, and use the compatible discriminator for training the policies. We then apply DEMER in an application of driver program recommendation. We firstly use an artificial driver program recommendation environment, abstracted from the real application, to verify and analyze the effectiveness of DEMER. We then test DEMER in the real application of Didi Chuxing. Experiment results show that DEMER can effectively reconstruct the hidden confounder, and thus can build the environment better. DEMER also derives a recommendation policy with a significantly improved performance in the test phase of the real application.