 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAM: A Normalization Attention Model for Personalized Product Search In Fliggy
Jun 10, 2025Personalized product search provides significant benefits to e-commerce platforms by extracting more accurate user preferences from historical behaviors. Previous studies largely focused on the user factors when personalizing the search query, while ignoring the item perspective, which leads to the following two challenges that we summarize in this paper: First, previous approaches relying only on co-occurrence frequency tend to overestimate the conversion rates for popular items and underestimate those for long-tail items, resulting in inaccurate item similarities; Second, user purchasing propensity is highly heterogeneous according to the popularity of the target item: it is less correlated with the user's historical behavior for a popular item and more correlated for a long-tail item. To address these challenges, in this paper we propose NAM, a Normalization Attention Model, which optimizes ''when to personalize'' by utilizing Inverse Item Frequency (IIF) and employing a gating mechanism, as well as optimizes ''how to personalize'' by normalizing the attention mechanism from a global perspective. Through comprehensive experiments, we demonstrate that our proposed NAM model significantly outperforms state-of-the-art baseline models. Furthermore, we conducted an online A/B test at Fliggy, and obtained a significant improvement of 0.8% over the latest production system in conversion rate.
Category-Extensible Out-of-Distribution Detection via Hierarchical Context Descriptions
Jul 23, 2024The key to OOD detection has two aspects: generalized feature representation and precise category description. Recently, vision-language models such as CLIP provide significant advances in both two issues, but constructing precise category descriptions is still in its infancy due to the absence of unseen categories. This work introduces two hierarchical contexts, namely perceptual context and spurious context, to carefully describe the precise category boundary through automatic prompt tuning. Specifically, perceptual contexts perceive the inter-category difference (e.g., cats vs apples) for current classification tasks, while spurious contexts further identify spurious (similar but exactly not) OOD samples for every single category (e.g., cats vs panthers, apples vs peaches). The two contexts hierarchically construct the precise description for a certain category, which is, first roughly classifying a sample to the predicted category and then delicately identifying whether it is truly an ID sample or actually OOD. Moreover, the precise descriptions for those categories within the vision-language framework present a novel application: CATegory-EXtensible OOD detection (CATEX). One can efficiently extend the set of recognizable categories by simply merging the hierarchical contexts learned under different sub-task settings. And extensive experiments are conducted to demonstrate CATEX's effectiveness, robustness, and category-extensibility. For instance, CATEX consistently surpasses the rivals by a large margin with several protocols on the challenging ImageNet-1K dataset. In addition, we offer new insights on how to efficiently scale up the prompt engineering in vision-language models to recognize thousands of object categories, as well as how to incorporate large language models (like GPT-3) to boost zero-shot applications. Code will be made public soon.
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection
Feb 06, 2024Knowledge hallucination have raised widespread concerns for the security and reliability of deployed LLMs. Previous efforts in detecting hallucinations have been employed at logit-level uncertainty estimation or language-level self-consistency evaluation, where the semantic information is inevitably lost during the token-decoding procedure. Thus, we propose to explore the dense semantic information retained within LLMs' \textbf{IN}ternal \textbf{S}tates for halluc\textbf{I}nation \textbf{DE}tection (\textbf{INSIDE}). In particular, a simple yet effective \textbf{EigenScore} metric is proposed to better evaluate responses' self-consistency, which exploits the eigenvalues of responses' covariance matrix to measure the semantic consistency/diversity in the dense embedding space. Furthermore, from the perspective of self-consistent hallucination detection, a test time feature clipping approach is explored to truncate extreme activations in the internal states, which reduces overconfident generations and potentially benefits the detection of overconfident hallucinations. Extensive experiments and ablation studies are performed on several popular LLMs and question-answering (QA) benchmarks, showing the effectiveness of our proposal.
Optimal Parameter and Neuron Pruning for Out-of-Distribution Detection
Feb 04, 2024For a machine learning model deployed in real world scenarios, the ability of detecting out-of-distribution (OOD) samples is indispensable and challenging. Most existing OOD detection methods focused on exploring advanced training skills or training-free tricks to prevent the model from yielding overconfident confidence score for unknown samples. The training-based methods require expensive training cost and rely on OOD samples which are not always available, while most training-free methods can not efficiently utilize the prior information from the training data. In this work, we propose an \textbf{O}ptimal \textbf{P}arameter and \textbf{N}euron \textbf{P}runing (\textbf{OPNP}) approach, which aims to identify and remove those parameters and neurons that lead to over-fitting. The main method is divided into two steps. In the first step, we evaluate the sensitivity of the model parameters and neurons by averaging gradients over all training samples. In the second step, the parameters and neurons with exceptionally large or close to zero sensitivities are removed for prediction. Our proposal is training-free, compatible with other post-hoc methods, and exploring the information from all training data. Extensive experiments are performed on multiple OOD detection tasks and model architectures, showing that our proposed OPNP consistently outperforms the existing methods by a large margin.
* Accepted by NeurIPS 2023. 19 pages
ChangeNet: Multi-Temporal Asymmetric Change Detection Dataset
Dec 29, 2023



Change Detection (CD) has been attracting extensive interests with the availability of bi-temporal datasets. However, due to the huge cost of multi-temporal images acquisition and labeling, existing change detection datasets are small in quantity, short in temporal, and low in practicability. Therefore, a large-scale practical-oriented dataset covering wide temporal phases is urgently needed to facilitate the community. To this end, the ChangeNet dataset is presented especially for multi-temporal change detection, along with the new task of ``Asymmetric Change Detection". Specifically, ChangeNet consists of 31,000 multi-temporal images pairs, a wide range of complex scenes from 100 cities, and 6 pixel-level annotated categories, which is far superior to all the existing change detection datasets including LEVIR-CD, WHU Building CD, etc.. In addition, ChangeNet contains amounts of real-world perspective distortions in different temporal phases on the same areas, which is able to promote the practical application of change detection algorithms. The ChangeNet dataset is suitable for both binary change detection (BCD) and semantic change detection (SCD) tasks. Accordingly, we benchmark the ChangeNet dataset on six BCD methods and two SCD methods, and extensive experiments demonstrate its challenges and great significance. The dataset is available at https://github.com/jankyee/ChangeNet.
Ultra-High Resolution Segmentation with Ultra-Rich Context: A Novel Benchmark
May 18, 2023



With the increasing interest and rapid development of methods for Ultra-High Resolution (UHR) segmentation, a large-scale benchmark covering a wide range of scenes with full fine-grained dense annotations is urgently needed to facilitate the field. To this end, the URUR dataset is introduced, in the meaning of Ultra-High Resolution dataset with Ultra-Rich Context. As the name suggests, URUR contains amounts of images with high enough resolution (3,008 images of size 5,120x5,120), a wide range of complex scenes (from 63 cities), rich-enough context (1 million instances with 8 categories) and fine-grained annotations (about 80 billion manually annotated pixels), which is far superior to all the existing UHR datasets including DeepGlobe, Inria Aerial, UDD, etc.. Moreover, we also propose WSDNet, a more efficient and effective framework for UHR segmentation especially with ultra-rich context. Specifically, multi-level Discrete Wavelet Transform (DWT) is naturally integrated to release computation burden while preserve more spatial details, along with a Wavelet Smooth Loss (WSL) to reconstruct original structured context and texture with a smooth constrain. Experiments on several UHR datasets demonstrate its state-of-the-art performance. The dataset is available at https://github.com/jankyee/URUR.
Structural and Statistical Texture Knowledge Distillation for Semantic Segmentation
May 06, 2023Existing knowledge distillation works for semantic segmentation mainly focus on transferring high-level contextual knowledge from teacher to student. However, low-level texture knowledge is also of vital importance for characterizing the local structural pattern and global statistical property, such as boundary, smoothness, regularity and color contrast, which may not be well addressed by high-level deep features. In this paper, we are intended to take full advantage of both structural and statistical texture knowledge and propose a novel Structural and Statistical Texture Knowledge Distillation (SSTKD) framework for semantic segmentation. Specifically, for structural texture knowledge, we introduce a Contourlet Decomposition Module (CDM) that decomposes low-level features with iterative Laplacian pyramid and directional filter bank to mine the structural texture knowledge. For statistical knowledge, we propose a Denoised Texture Intensity Equalization Module (DTIEM) to adaptively extract and enhance statistical texture knowledge through heuristics iterative quantization and denoised operation. Finally, each knowledge learning is supervised by an individual loss function, forcing the student network to mimic the teacher better from a broader perspective. Experiments show that the proposed method achieves state-of-the-art performance on Cityscapes, Pascal VOC 2012 and ADE20K datasets.
Invariant Feature Learning for Generalized Long-Tailed Classification
Jul 19, 2022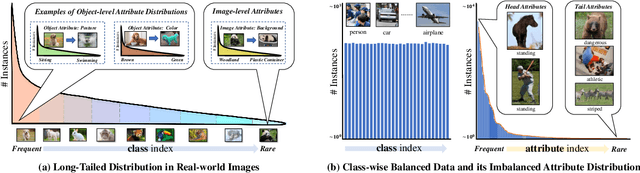
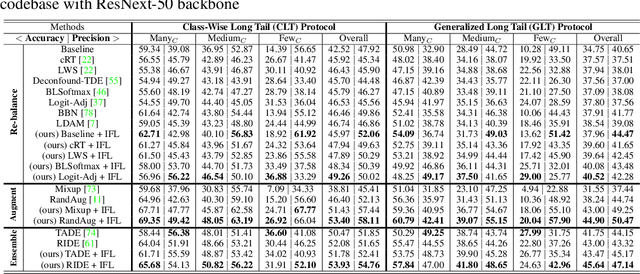
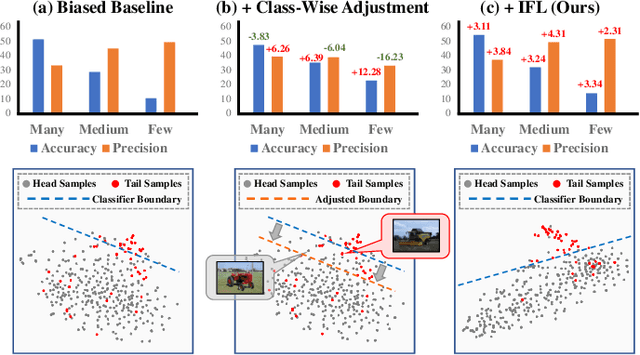
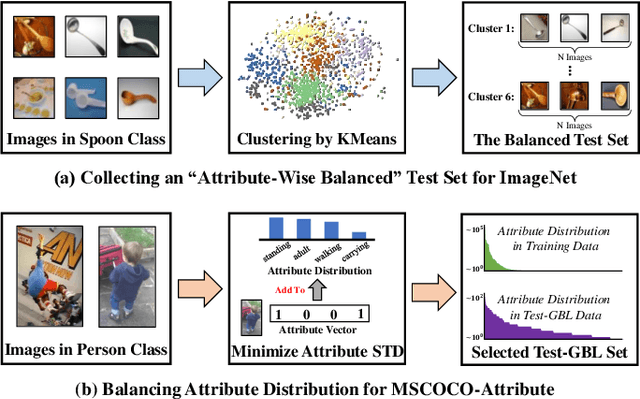
Existing long-tailed classification (LT) methods only focus on tackling the class-wise imbalance that head classes have more samples than tail classes, but overlook the attribute-wise imbalance. In fact, even if the class is balanced, samples within each class may still be long-tailed due to the varying attributes. Note that the latter is fundamentally more ubiquitous and challenging than the former because attributes are not just implicit for most datasets, but also combinatorially complex, thus prohibitively expensive to be balanced. Therefore, we introduce a novel research problem: Generalized Long-Tailed classification (GLT), to jointly consider both kinds of imbalances. By "generalized", we mean that a GLT method should naturally solve the traditional LT, but not vice versa. Not surprisingly, we find that most class-wise LT methods degenerate in our proposed two benchmarks: ImageNet-GLT and MSCOCO-GLT. We argue that it is because they over-emphasize the adjustment of class distribution while neglecting to learn attribute-invariant features. To this end, we propose an Invariant Feature Learning (IFL) method as the first strong baseline for GLT. IFL first discovers environments with divergent intra-class distributions from the imperfect predictions and then learns invariant features across them. Promisingly, as an improved feature backbone, IFL boosts all the LT line-up: one/two-stage re-balance, augmentation, and ensemble. Codes and benchmarks are available on Github: https://github.com/KaihuaTang/Generalized-Long-Tailed-Benchmarks.pytorch
Spatial Likelihood Voting with Self-Knowledge Distillation for Weakly Supervised Object Detection
Apr 14, 2022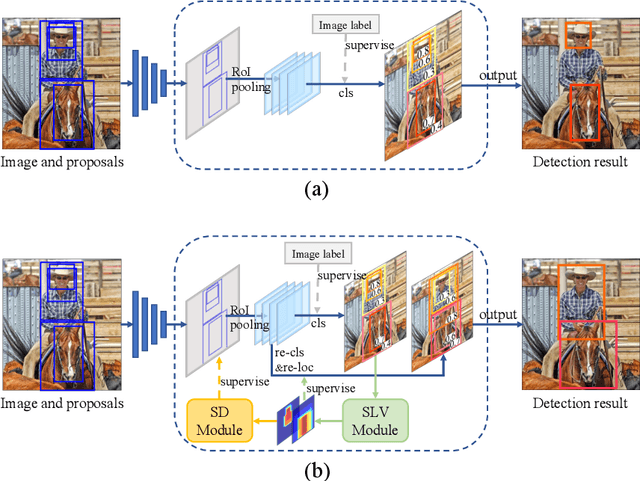
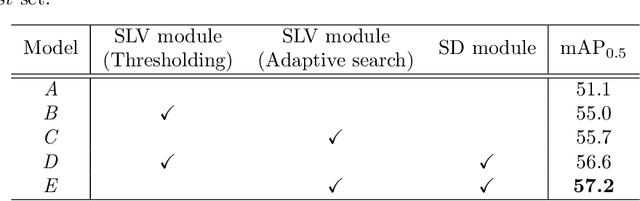
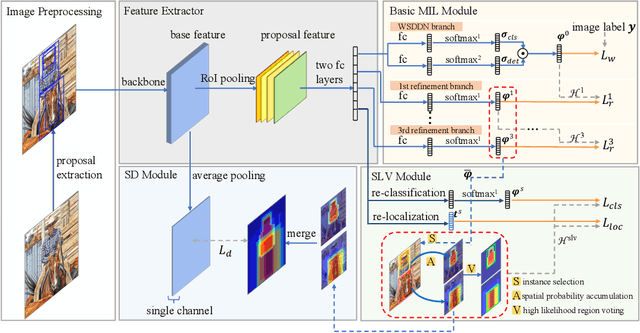

Weakly supervised object detection (WSOD), which is an effective way to train an object detection model using only image-level annotations, has attracted considerable attention from researchers. However, most of the existing methods, which are based on multiple instance learning (MIL), tend to localize instances to the discriminative parts of salient objects instead of the entire content of all objects. In this paper, we propose a WSOD framework called the Spatial Likelihood Voting with Self-knowledge Distillation Network (SLV-SD Net). In this framework, we introduce a spatial likelihood voting (SLV) module to converge region proposal localization without bounding box annotations. Specifically, in every iteration during training, all the region proposals in a given image act as voters voting for the likelihood of each category in the spatial dimensions. After dilating the alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, which are then used for the final classification and localization. Based on SLV, we further propose a self-knowledge distillation (SD) module to refine the feature representations of the given image. The likelihood maps generated by the SLV module are used to supervise the feature learning of the backbone network, encouraging the network to attend to wider and more diverse areas of the image. Extensive experiments on the PASCAL VOC 2007/2012 and MS-COCO datasets demonstrate the excellent performance of SLV-SD Net. In addition, SLV-SD Net produces new state-of-the-art results on these benchmarks.
* arXiv admin note: text overlap with arXiv:2006.12884
Dynamic Supervisor for Cross-dataset Object Detection
Apr 01, 2022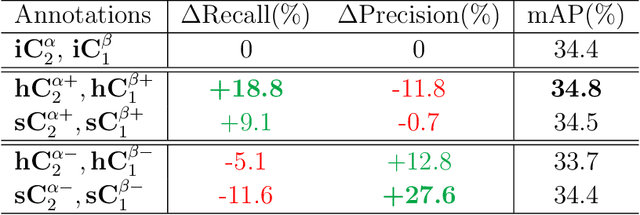
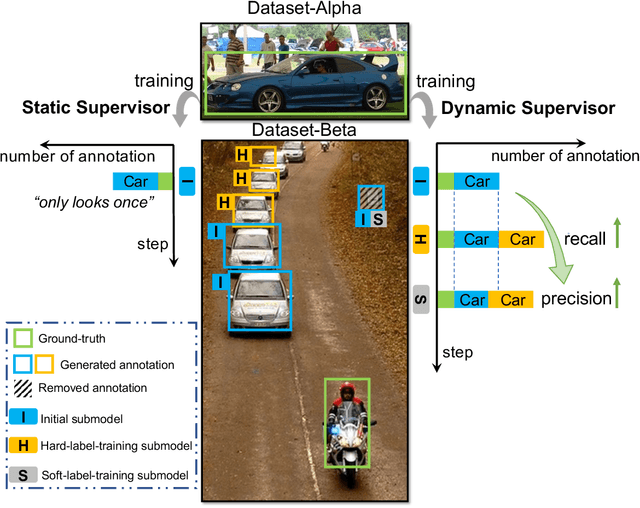

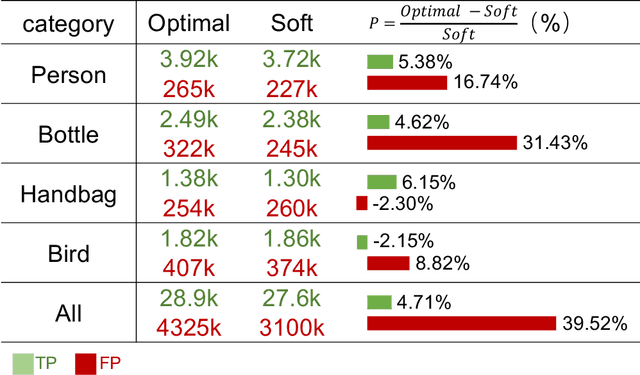
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.