 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJavisDiT: Joint Audio-Video Diffusion Transformer with Hierarchical Spatio-Temporal Prior Synchronization
Mar 30, 2025This paper introduces JavisDiT, a novel Joint Audio-Video Diffusion Transformer designed for synchronized audio-video generation (JAVG). Built upon the powerful Diffusion Transformer (DiT) architecture, JavisDiT is able to generate high-quality audio and video content simultaneously from open-ended user prompts. To ensure optimal synchronization, we introduce a fine-grained spatio-temporal alignment mechanism through a Hierarchical Spatial-Temporal Synchronized Prior (HiST-Sypo) Estimator. This module extracts both global and fine-grained spatio-temporal priors, guiding the synchronization between the visual and auditory components. Furthermore, we propose a new benchmark, JavisBench, consisting of 10,140 high-quality text-captioned sounding videos spanning diverse scenes and complex real-world scenarios. Further, we specifically devise a robust metric for evaluating the synchronization between generated audio-video pairs in real-world complex content. Experimental results demonstrate that JavisDiT significantly outperforms existing methods by ensuring both high-quality generation and precise synchronization, setting a new standard for JAVG tasks. Our code, model, and dataset will be made publicly available at https://javisdit.github.io/.
Educating LLMs like Human Students: Structure-aware Injection of Domain Knowledge
Jul 23, 2024



This paper presents a pioneering methodology, termed StructTuning, to efficiently transform foundation Large Language Models (LLMs) into domain specialists. It significantly minimizes the training corpus requirement to a mere 0.3% while achieving an impressive 50% of traditional knowledge injection performance. Our method is inspired by the educational processes for human students, particularly how structured domain knowledge from textbooks is absorbed and then applied to tackle real-world challenges through specific exercises. Based on this, we propose a novel two-stage knowledge injection strategy: Structure-aware Continual Pre-Training (SCPT) and Structure-aware Supervised Fine-Tuning (SSFT). In the SCPT phase, we organize the training data into an auto-generated taxonomy of domain knowledge, enabling LLMs to effectively memorize textual segments linked to specific expertise within the taxonomy's architecture. Subsequently, in the SSFT phase, we explicitly prompt models to reveal the underlying knowledge structure in their outputs, leveraging this structured domain insight to address practical problems adeptly. Our ultimate method has undergone extensive evaluations across model architectures and scales, using closed-book question-answering tasks on LongBench and MMedBench datasets. Remarkably, our method matches 50% of the improvement displayed by the state-of-the-art MMedLM2 on MMedBench, but with only 0.3% quantity of the training corpus. This breakthrough showcases the potential to scale up our StructTuning for stronger domain-specific LLMs. Code will be made public soon.
Category-Extensible Out-of-Distribution Detection via Hierarchical Context Descriptions
Jul 23, 2024The key to OOD detection has two aspects: generalized feature representation and precise category description. Recently, vision-language models such as CLIP provide significant advances in both two issues, but constructing precise category descriptions is still in its infancy due to the absence of unseen categories. This work introduces two hierarchical contexts, namely perceptual context and spurious context, to carefully describe the precise category boundary through automatic prompt tuning. Specifically, perceptual contexts perceive the inter-category difference (e.g., cats vs apples) for current classification tasks, while spurious contexts further identify spurious (similar but exactly not) OOD samples for every single category (e.g., cats vs panthers, apples vs peaches). The two contexts hierarchically construct the precise description for a certain category, which is, first roughly classifying a sample to the predicted category and then delicately identifying whether it is truly an ID sample or actually OOD. Moreover, the precise descriptions for those categories within the vision-language framework present a novel application: CATegory-EXtensible OOD detection (CATEX). One can efficiently extend the set of recognizable categories by simply merging the hierarchical contexts learned under different sub-task settings. And extensive experiments are conducted to demonstrate CATEX's effectiveness, robustness, and category-extensibility. For instance, CATEX consistently surpasses the rivals by a large margin with several protocols on the challenging ImageNet-1K dataset. In addition, we offer new insights on how to efficiently scale up the prompt engineering in vision-language models to recognize thousands of object categories, as well as how to incorporate large language models (like GPT-3) to boost zero-shot applications. Code will be made public soon.
Enhancing LLM's Cognition via Structurization
Jul 23, 2024



When reading long-form text, human cognition is complex and structurized. While large language models (LLMs) process input contexts through a causal and sequential perspective, this approach can potentially limit their ability to handle intricate and complex inputs effectively. To enhance LLM's cognition capability, this paper presents a novel concept of context structurization. Specifically, we transform the plain, unordered contextual sentences into well-ordered and hierarchically structurized elements. By doing so, LLMs can better grasp intricate and extended contexts through precise attention and information-seeking along the organized structures. Extensive evaluations are conducted across various model architectures and sizes (including several 7B- to 72B-size auto-regressive LLMs as well as BERT-like masking models) on a diverse set of NLP tasks (e.g., context-based question-answering, exhaustive hallucination evaluation, and passage-level dense retrieval). Empirical results show consistent and significant performance gains afforded by a single-round structurization. In particular, we boost a 72B-parameter open-source model to achieve comparable performance against GPT-3.5-Turbo as the hallucination evaluator. Besides, we show the feasibility of distilling advanced LLMs' language processing abilities to a smaller yet effective StruXGPT-7B to execute structurization, addressing the practicality of our approach. Code will be made public soon.
ESOD: Efficient Small Object Detection on High-Resolution Images
Jul 23, 2024



Enlarging input images is a straightforward and effective approach to promote small object detection. However, simple image enlargement is significantly expensive on both computations and GPU memory. In fact, small objects are usually sparsely distributed and locally clustered. Therefore, massive feature extraction computations are wasted on the non-target background area of images. Recent works have tried to pick out target-containing regions using an extra network and perform conventional object detection, but the newly introduced computation limits their final performance. In this paper, we propose to reuse the detector's backbone to conduct feature-level object-seeking and patch-slicing, which can avoid redundant feature extraction and reduce the computation cost. Incorporating a sparse detection head, we are able to detect small objects on high-resolution inputs (e.g., 1080P or larger) for superior performance. The resulting Efficient Small Object Detection (ESOD) approach is a generic framework, which can be applied to both CNN- and ViT-based detectors to save the computation and GPU memory costs. Extensive experiments demonstrate the efficacy and efficiency of our method. In particular, our method consistently surpasses the SOTA detectors by a large margin (e.g., 8% gains on AP) on the representative VisDrone, UAVDT, and TinyPerson datasets. Code will be made public soon.
Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution
Jul 23, 2024Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection approaches. Code will be made public soon.
Uncertainty-aware Unsupervised Multi-Object Tracking
Jul 28, 2023



Without manually annotated identities, unsupervised multi-object trackers are inferior to learning reliable feature embeddings. It causes the similarity-based inter-frame association stage also be error-prone, where an uncertainty problem arises. The frame-by-frame accumulated uncertainty prevents trackers from learning the consistent feature embedding against time variation. To avoid this uncertainty problem, recent self-supervised techniques are adopted, whereas they failed to capture temporal relations. The interframe uncertainty still exists. In fact, this paper argues that though the uncertainty problem is inevitable, it is possible to leverage the uncertainty itself to improve the learned consistency in turn. Specifically, an uncertainty-based metric is developed to verify and rectify the risky associations. The resulting accurate pseudo-tracklets boost learning the feature consistency. And accurate tracklets can incorporate temporal information into spatial transformation. This paper proposes a tracklet-guided augmentation strategy to simulate tracklets' motion, which adopts a hierarchical uncertainty-based sampling mechanism for hard sample mining. The ultimate unsupervised MOT framework, namely U2MOT, is proven effective on MOT-Challenges and VisDrone-MOT benchmark. U2MOT achieves a SOTA performance among the published supervised and unsupervised trackers.
Self-Learning Symmetric Multi-view Probabilistic Clustering
May 12, 2023



Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete multi-view clustering. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. Moreover, category information is required in most existing methods, which severely affects the clustering performance. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution from the aspect of consistency in single-view, cross-view and multi-view. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively, in which category information is not required. Extensive experiments on multiple benchmarks for incomplete and complete MVC show that SLS-MPC significantly outperforms previous state-of-the-art methods.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022



Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.
Spatial Likelihood Voting with Self-Knowledge Distillation for Weakly Supervised Object Detection
Apr 14, 2022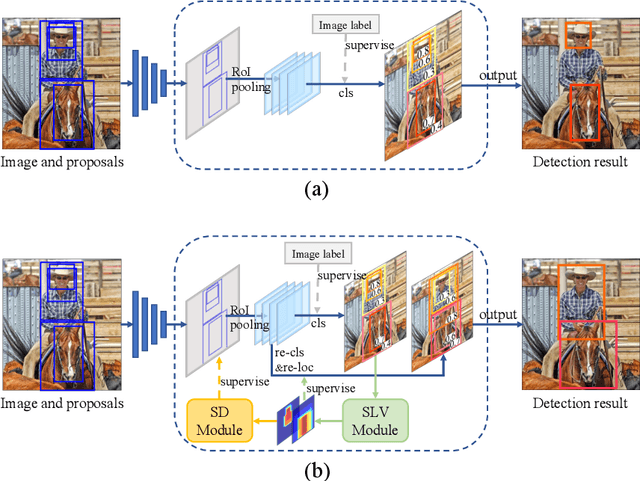
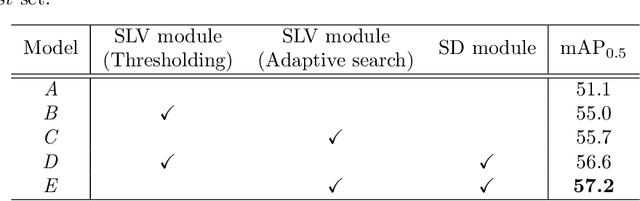
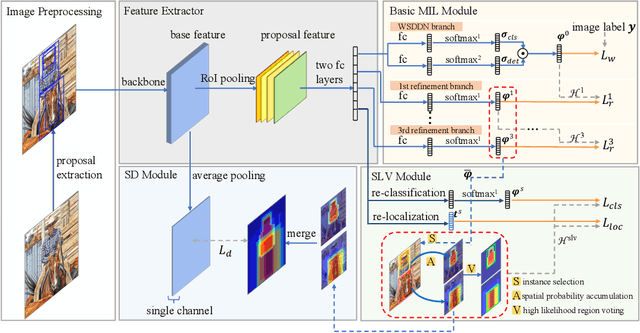

Weakly supervised object detection (WSOD), which is an effective way to train an object detection model using only image-level annotations, has attracted considerable attention from researchers. However, most of the existing methods, which are based on multiple instance learning (MIL), tend to localize instances to the discriminative parts of salient objects instead of the entire content of all objects. In this paper, we propose a WSOD framework called the Spatial Likelihood Voting with Self-knowledge Distillation Network (SLV-SD Net). In this framework, we introduce a spatial likelihood voting (SLV) module to converge region proposal localization without bounding box annotations. Specifically, in every iteration during training, all the region proposals in a given image act as voters voting for the likelihood of each category in the spatial dimensions. After dilating the alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, which are then used for the final classification and localization. Based on SLV, we further propose a self-knowledge distillation (SD) module to refine the feature representations of the given image. The likelihood maps generated by the SLV module are used to supervise the feature learning of the backbone network, encouraging the network to attend to wider and more diverse areas of the image. Extensive experiments on the PASCAL VOC 2007/2012 and MS-COCO datasets demonstrate the excellent performance of SLV-SD Net. In addition, SLV-SD Net produces new state-of-the-art results on these benchmarks.
* arXiv admin note: text overlap with arXiv:2006.12884