 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
Aug 14, 2025



Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given the LLM's diminished reasoning over extended context and high computational cost, retrieval-based approaches remain a pivotal role in practice. However, traditional RAG methods can fall short due to their stateless, single-step retrieval process, which often overlooks the dynamic nature of capturing interconnected relations within long-range context. In this work, we propose ComoRAG, holding the principle that narrative reasoning is not a one-shot process, but a dynamic, evolving interplay between new evidence acquisition and past knowledge consolidation, analogous to human cognition when reasoning with memory-related signals in the brain. Specifically, when encountering a reasoning impasse, ComoRAG undergoes iterative reasoning cycles while interacting with a dynamic memory workspace. In each cycle, it generates probing queries to devise new exploratory paths, then integrates the retrieved evidence of new aspects into a global memory pool, thereby supporting the emergence of a coherent context for the query resolution. Across four challenging long-context narrative benchmarks (200K+ tokens), ComoRAG outperforms strong RAG baselines with consistent relative gains up to 11% compared to the strongest baseline. Further analysis reveals that ComoRAG is particularly advantageous for complex queries requiring global comprehension, offering a principled, cognitively motivated paradigm for retrieval-based long context comprehension towards stateful reasoning. Our code is publicly released at https://github.com/EternityJune25/ComoRAG
IGL-Nav: Incremental 3D Gaussian Localization for Image-goal Navigation
Aug 01, 2025



Visual navigation with an image as goal is a fundamental and challenging problem. Conventional methods either rely on end-to-end RL learning or modular-based policy with topological graph or BEV map as memory, which cannot fully model the geometric relationship between the explored 3D environment and the goal image. In order to efficiently and accurately localize the goal image in 3D space, we build our navigation system upon the renderable 3D gaussian (3DGS) representation. However, due to the computational intensity of 3DGS optimization and the large search space of 6-DoF camera pose, directly leveraging 3DGS for image localization during agent exploration process is prohibitively inefficient. To this end, we propose IGL-Nav, an Incremental 3D Gaussian Localization framework for efficient and 3D-aware image-goal navigation. Specifically, we incrementally update the scene representation as new images arrive with feed-forward monocular prediction. Then we coarsely localize the goal by leveraging the geometric information for discrete space matching, which can be equivalent to efficient 3D convolution. When the agent is close to the goal, we finally solve the fine target pose with optimization via differentiable rendering. The proposed IGL-Nav outperforms existing state-of-the-art methods by a large margin across diverse experimental configurations. It can also handle the more challenging free-view image-goal setting and be deployed on real-world robotic platform using a cellphone to capture goal image at arbitrary pose. Project page: https://gwxuan.github.io/IGL-Nav/.
LCS: An AI-based Low-Complexity Scaler for Power-Efficient Super-Resolution of Game Content
Jul 30, 2025



The increasing complexity of content rendering in modern games has led to a problematic growth in the workload of the GPU. In this paper, we propose an AI-based low-complexity scaler (LCS) inspired by state-of-the-art efficient super-resolution (ESR) models which could offload the workload on the GPU to a low-power device such as a neural processing unit (NPU). The LCS is trained on GameIR image pairs natively rendered at low and high resolution. We utilize adversarial training to encourage reconstruction of perceptually important details, and apply reparameterization and quantization techniques to reduce model complexity and size. In our comparative analysis we evaluate the LCS alongside the publicly available AMD hardware-based Edge Adaptive Scaling Function (EASF) and AMD FidelityFX Super Resolution 1 (FSR1) on five different metrics, and find that the LCS achieves better perceptual quality, demonstrating the potential of ESR models for upscaling on resource-constrained devices.
Eyepiece-free pupil-optimized holographic near-eye displays
Jul 30, 2025Computer-generated holography (CGH) represents a transformative visualization approach for next-generation immersive virtual and augmented reality (VR/AR) displays, enabling precise wavefront modulation and naturally providing comprehensive physiological depth cues without the need for bulky optical assemblies. Despite significant advancements in computational algorithms enhancing image quality and achieving real-time generation, practical implementations of holographic near-eye displays (NEDs) continue to face substantial challenges arising from finite and dynamically varying pupil apertures, which degrade image quality and compromise user experience. In this study, we introduce an eyepiece-free pupil-optimized holographic NED. Our proposed method employs a customized spherical phase modulation strategy to generate multiple viewpoints within the pupil, entirely eliminating the dependence on conventional optical eyepieces. Through the joint optimization of amplitude and phase distributions across these viewpoints, the method markedly mitigates image degradation due to finite pupil sampling and resolves inapparent depth cues induced by the spherical phase. The demonstrated method signifies a substantial advancement toward the realization of compact, lightweight, and flexible holographic NED systems, fulfilling stringent requirements for future VR/AR display technologies.
Protein-SE(3): Benchmarking SE(3)-based Generative Models for Protein Structure Design
Jul 27, 2025SE(3)-based generative models have shown great promise in protein geometry modeling and effective structure design. However, the field currently lacks a modularized benchmark to enable comprehensive investigation and fair comparison of different methods. In this paper, we propose Protein-SE(3), a new benchmark based on a unified training framework, which comprises protein scaffolding tasks, integrated generative models, high-level mathematical abstraction, and diverse evaluation metrics. Recent advanced generative models designed for protein scaffolding, from multiple perspectives like DDPM (Genie1 and Genie2), Score Matching (FrameDiff and RfDiffusion) and Flow Matching (FoldFlow and FrameFlow) are integrated into our framework. All integrated methods are fairly investigated with the same training dataset and evaluation metrics. Furthermore, we provide a high-level abstraction of the mathematical foundations behind the generative models, enabling fast prototyping of future algorithms without reliance on explicit protein structures. Accordingly, we release the first comprehensive benchmark built upon unified training framework for SE(3)-based protein structure design, which is publicly accessible at https://github.com/BruthYU/protein-se3.
Streaming 4D Visual Geometry Transformer
Jul 15, 2025



Perceiving and reconstructing 4D spatial-temporal geometry from videos is a fundamental yet challenging computer vision task. To facilitate interactive and real-time applications, we propose a streaming 4D visual geometry transformer that shares a similar philosophy with autoregressive large language models. We explore a simple and efficient design and employ a causal transformer architecture to process the input sequence in an online manner. We use temporal causal attention and cache the historical keys and values as implicit memory to enable efficient streaming long-term 4D reconstruction. This design can handle real-time 4D reconstruction by incrementally integrating historical information while maintaining high-quality spatial consistency. For efficient training, we propose to distill knowledge from the dense bidirectional visual geometry grounded transformer (VGGT) to our causal model. For inference, our model supports the migration of optimized efficient attention operator (e.g., FlashAttention) from the field of large language models. Extensive experiments on various 4D geometry perception benchmarks demonstrate that our model increases the inference speed in online scenarios while maintaining competitive performance, paving the way for scalable and interactive 4D vision systems. Code is available at: https://github.com/wzzheng/StreamVGGT.
Point3R: Streaming 3D Reconstruction with Explicit Spatial Pointer Memory
Jul 03, 2025Dense 3D scene reconstruction from an ordered sequence or unordered image collections is a critical step when bringing research in computer vision into practical scenarios. Following the paradigm introduced by DUSt3R, which unifies an image pair densely into a shared coordinate system, subsequent methods maintain an implicit memory to achieve dense 3D reconstruction from more images. However, such implicit memory is limited in capacity and may suffer from information loss of earlier frames. We propose Point3R, an online framework targeting dense streaming 3D reconstruction. To be specific, we maintain an explicit spatial pointer memory directly associated with the 3D structure of the current scene. Each pointer in this memory is assigned a specific 3D position and aggregates scene information nearby in the global coordinate system into a changing spatial feature. Information extracted from the latest frame interacts explicitly with this pointer memory, enabling dense integration of the current observation into the global coordinate system. We design a 3D hierarchical position embedding to promote this interaction and design a simple yet effective fusion mechanism to ensure that our pointer memory is uniform and efficient. Our method achieves competitive or state-of-the-art performance on various tasks with low training costs. Code is available at: https://github.com/YkiWu/Point3R.
LaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
Jul 03, 2025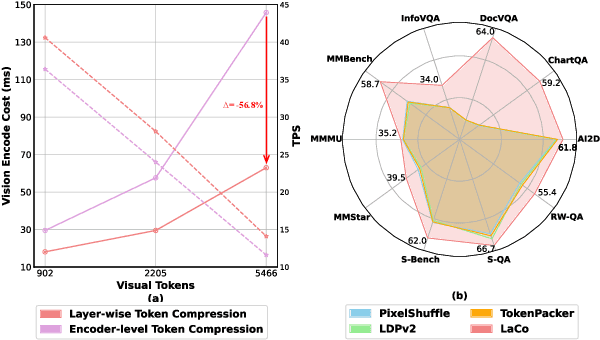
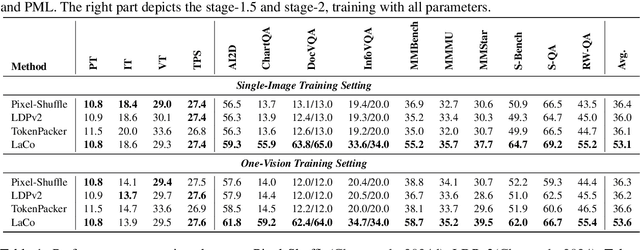
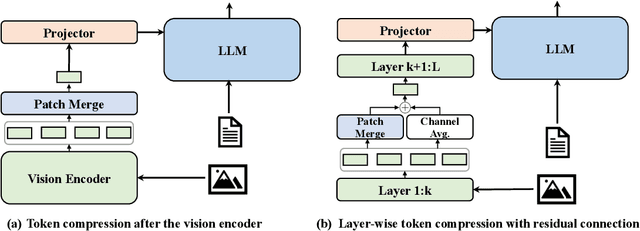

Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.
GenWorld: Towards Detecting AI-generated Real-world Simulation Videos
Jun 12, 2025The flourishing of video generation technologies has endangered the credibility of real-world information and intensified the demand for AI-generated video detectors. Despite some progress, the lack of high-quality real-world datasets hinders the development of trustworthy detectors. In this paper, we propose GenWorld, a large-scale, high-quality, and real-world simulation dataset for AI-generated video detection. GenWorld features the following characteristics: (1) Real-world Simulation: GenWorld focuses on videos that replicate real-world scenarios, which have a significant impact due to their realism and potential influence; (2) High Quality: GenWorld employs multiple state-of-the-art video generation models to provide realistic and high-quality forged videos; (3) Cross-prompt Diversity: GenWorld includes videos generated from diverse generators and various prompt modalities (e.g., text, image, video), offering the potential to learn more generalizable forensic features. We analyze existing methods and find they fail to detect high-quality videos generated by world models (i.e., Cosmos), revealing potential drawbacks of ignoring real-world clues. To address this, we propose a simple yet effective model, SpannDetector, to leverage multi-view consistency as a strong criterion for real-world AI-generated video detection. Experiments show that our method achieves superior results, highlighting a promising direction for explainable AI-generated video detection based on physical plausibility. We believe that GenWorld will advance the field of AI-generated video detection. Project Page: https://chen-wl20.github.io/GenWorld
SpectralAR: Spectral Autoregressive Visual Generation
Jun 12, 2025Autoregressive visual generation has garnered increasing attention due to its scalability and compatibility with other modalities compared with diffusion models. Most existing methods construct visual sequences as spatial patches for autoregressive generation. However, image patches are inherently parallel, contradicting the causal nature of autoregressive modeling. To address this, we propose a Spectral AutoRegressive (SpectralAR) visual generation framework, which realizes causality for visual sequences from the spectral perspective. Specifically, we first transform an image into ordered spectral tokens with Nested Spectral Tokenization, representing lower to higher frequency components. We then perform autoregressive generation in a coarse-to-fine manner with the sequences of spectral tokens. By considering different levels of detail in images, our SpectralAR achieves both sequence causality and token efficiency without bells and whistles. We conduct extensive experiments on ImageNet-1K for image reconstruction and autoregressive generation, and SpectralAR achieves 3.02 gFID with only 64 tokens and 310M parameters. Project page: https://huang-yh.github.io/spectralar/.