 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextModule: Improving Code Completion via Repository-level Contextual Information
Dec 11, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in code completion tasks, where they assist developers by predicting and generating new code in real-time. However, existing LLM-based code completion systems primarily rely on the immediate context of the file being edited, often missing valuable repository-level information, user behaviour and edit history that could improve suggestion accuracy. Additionally, challenges such as efficiently retrieving relevant code snippets from large repositories, incorporating user behavior, and balancing accuracy with low-latency requirements in production environments remain unresolved. In this paper, we propose ContextModule, a framework designed to enhance LLM-based code completion by retrieving and integrating three types of contextual information from the repository: user behavior-based code, similar code snippets, and critical symbol definitions. By capturing user interactions across files and leveraging repository-wide static analysis, ContextModule improves the relevance and precision of generated code. We implement performance optimizations, such as index caching, to ensure the system meets the latency constraints of real-world coding environments. Experimental results and industrial practise demonstrate that ContextModule significantly improves code completion accuracy and user acceptance rates.
An Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024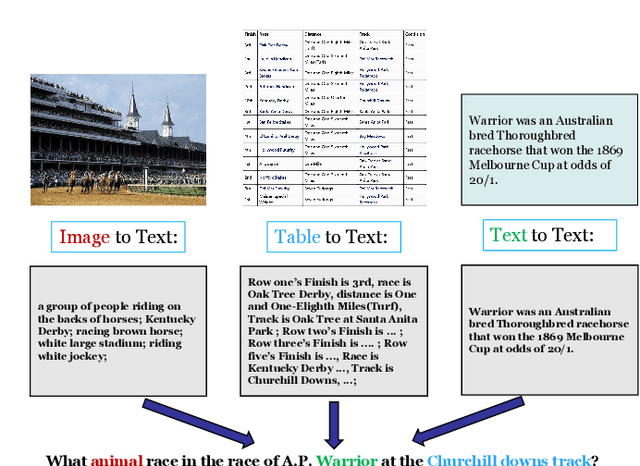



With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research
Medchain: Bridging the Gap Between LLM Agents and Clinical Practice through Interactive Sequential Benchmarking
Dec 02, 2024



Clinical decision making (CDM) is a complex, dynamic process crucial to healthcare delivery, yet it remains a significant challenge for artificial intelligence systems. While Large Language Model (LLM)-based agents have been tested on general medical knowledge using licensing exams and knowledge question-answering tasks, their performance in the CDM in real-world scenarios is limited due to the lack of comprehensive testing datasets that mirror actual medical practice. To address this gap, we present MedChain, a dataset of 12,163 clinical cases that covers five key stages of clinical workflow. MedChain distinguishes itself from existing benchmarks with three key features of real-world clinical practice: personalization, interactivity, and sequentiality. Further, to tackle real-world CDM challenges, we also propose MedChain-Agent, an AI system that integrates a feedback mechanism and a MCase-RAG module to learn from previous cases and adapt its responses. MedChain-Agent demonstrates remarkable adaptability in gathering information dynamically and handling sequential clinical tasks, significantly outperforming existing approaches. The relevant dataset and code will be released upon acceptance of this paper.
Large Language Models for Lossless Image Compression: Next-Pixel Prediction in Language Space is All You Need
Nov 19, 2024



We have recently witnessed that ``Intelligence" and `` Compression" are the two sides of the same coin, where the language large model (LLM) with unprecedented intelligence is a general-purpose lossless compressor for various data modalities. This attribute particularly appeals to the lossless image compression community, given the increasing need to compress high-resolution images in the current streaming media era. Consequently, a spontaneous envision emerges: Can the compression performance of the LLM elevate lossless image compression to new heights? However, our findings indicate that the naive application of LLM-based lossless image compressors suffers from a considerable performance gap compared with existing state-of-the-art (SOTA) codecs on common benchmark datasets. In light of this, we are dedicated to fulfilling the unprecedented intelligence (compression) capacity of the LLM for lossless image compression tasks, thereby bridging the gap between theoretical and practical compression performance. Specifically, we propose P$^{2}$-LLM, a next-pixel prediction-based LLM, which integrates various elaborated insights and methodologies, \textit{e.g.,} pixel-level priors, the in-context ability of LLM, and a pixel-level semantic preservation strategy, to enhance the understanding capacity of pixel sequences for better next-pixel predictions. Extensive experiments on benchmark datasets demonstrate that P$^{2}$-LLM can beat SOTA classical and learned codecs.
Best Practices for Distilling Large Language Models into BERT for Web Search Ranking
Nov 07, 2024Recent studies have highlighted the significant potential of Large Language Models (LLMs) as zero-shot relevance rankers. These methods predominantly utilize prompt learning to assess the relevance between queries and documents by generating a ranked list of potential documents. Despite their promise, the substantial costs associated with LLMs pose a significant challenge for their direct implementation in commercial search systems. To overcome this barrier and fully exploit the capabilities of LLMs for text ranking, we explore techniques to transfer the ranking expertise of LLMs to a more compact model similar to BERT, using a ranking loss to enable the deployment of less resource-intensive models. Specifically, we enhance the training of LLMs through Continued Pre-Training, taking the query as input and the clicked title and summary as output. We then proceed with supervised fine-tuning of the LLM using a rank loss, assigning the final token as a representative of the entire sentence. Given the inherent characteristics of autoregressive language models, only the final token </s> can encapsulate all preceding tokens. Additionally, we introduce a hybrid point-wise and margin MSE loss to transfer the ranking knowledge from LLMs to smaller models like BERT. This method creates a viable solution for environments with strict resource constraints. Both offline and online evaluations have confirmed the efficacy of our approach, and our model has been successfully integrated into a commercial web search engine as of February 2024.
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Nov 07, 2024



In this work, we address the cooperation problem among large language model (LLM) based embodied agents, where agents must cooperate to achieve a common goal. Previous methods often execute actions extemporaneously and incoherently, without long-term strategic and cooperative planning, leading to redundant steps, failures, and even serious repercussions in complex tasks like search-and-rescue missions where discussion and cooperative plan are crucial. To solve this issue, we propose Cooperative Plan Optimization (CaPo) to enhance the cooperation efficiency of LLM-based embodied agents. Inspired by human cooperation schemes, CaPo improves cooperation efficiency with two phases: 1) meta-plan generation, and 2) progress-adaptive meta-plan and execution. In the first phase, all agents analyze the task, discuss, and cooperatively create a meta-plan that decomposes the task into subtasks with detailed steps, ensuring a long-term strategic and coherent plan for efficient coordination. In the second phase, agents execute tasks according to the meta-plan and dynamically adjust it based on their latest progress (e.g., discovering a target object) through multi-turn discussions. This progress-based adaptation eliminates redundant actions, improving the overall cooperation efficiency of agents. Experimental results on the ThreeDworld Multi-Agent Transport and Communicative Watch-And-Help tasks demonstrate that CaPo achieves much higher task completion rate and efficiency compared with state-of-the-arts.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
The NPU-HWC System for the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge
Oct 31, 2024This paper presents the NPU-HWC system submitted to the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge 2024 (ICAGC). Our system consists of two modules: a speech generator for Track 1 and a background audio generator for Track 2. In Track 1, we employ Single-Codec to tokenize the speech into discrete tokens and use a language-model-based approach to achieve zero-shot speaking style cloning. The Single-Codec effectively decouples timbre and speaking style at the token level, reducing the acoustic modeling burden on the autoregressive language model. Additionally, we use DSPGAN to upsample 16 kHz mel-spectrograms to high-fidelity 48 kHz waveforms. In Track 2, we propose a background audio generator based on large language models (LLMs). This system produces scene-appropriate accompaniment descriptions, synthesizes background audio with Tango 2, and integrates it with the speech generated by our Track 1 system. Our submission achieves the second place and the first place in Track 1 and Track 2 respectively.
HASN: Hybrid Attention Separable Network for Efficient Image Super-resolution
Oct 13, 2024Recently, lightweight methods for single image super-resolution (SISR) have gained significant popularity and achieved impressive performance due to limited hardware resources. These methods demonstrate that adopting residual feature distillation is an effective way to enhance performance. However, we find that using residual connections after each block increases the model's storage and computational cost. Therefore, to simplify the network structure and learn higher-level features and relationships between features, we use depthwise separable convolutions, fully connected layers, and activation functions as the basic feature extraction modules. This significantly reduces computational load and the number of parameters while maintaining strong feature extraction capabilities. To further enhance model performance, we propose the Hybrid Attention Separable Block (HASB), which combines channel attention and spatial attention, thus making use of their complementary advantages. Additionally, we use depthwise separable convolutions instead of standard convolutions, significantly reducing the computational load and the number of parameters while maintaining strong feature extraction capabilities. During the training phase, we also adopt a warm-start retraining strategy to exploit the potential of the model further. Extensive experiments demonstrate the effectiveness of our approach. Our method achieves a smaller model size and reduced computational complexity without compromising performance. Code can be available at https://github.com/nathan66666/HASN.git
SGW-based Multi-Task Learning in Vision Tasks
Oct 03, 2024Multi-task-learning(MTL) is a multi-target optimization task. Neural networks try to realize each target using a shared interpretative space within MTL. However, as the scale of datasets expands and the complexity of tasks increases, knowledge sharing becomes increasingly challenging. In this paper, we first re-examine previous cross-attention MTL methods from the perspective of noise. We theoretically analyze this issue and identify it as a flaw in the cross-attention mechanism. To address this issue, we propose an information bottleneck knowledge extraction module (KEM). This module aims to reduce inter-task interference by constraining the flow of information, thereby reducing computational complexity. Furthermore, we have employed neural collapse to stabilize the knowledge-selection process. That is, before input to KEM, we projected the features into ETF space. This mapping makes our method more robust. We implemented and conducted comparative experiments with this method on multiple datasets. The results demonstrate that our approach significantly outperforms existing methods in multi-task learning.