 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGen: Affect-Reinforced Generative Augmentation towards Vision-based Dynamic Emotion Perception
Apr 14, 2026Dynamic facial expression recognition in the wild remains challenging due to data scarcity and long-tail distributions, which hinder models from effectively learning the temporal dynamics of scarce emotions. To address these limitations, we propose ARGen, an Affect-Reinforced Generative Augmentation Framework that enables data-adaptive dynamic expression generation for robust emotion perception. ARGen operates in two stages: Affective Semantic Injection (ASI) and Adaptive Reinforcement Diffusion (ARD). The ASI stage establishes affective knowledge alignment through facial Action Units and employs a retrieval-augmented prompt generation strategy to synthesize consistent and fine-grained affective descriptions via large-scale visual-language models, thereby injecting interpretable emotional priors into the generation process. The ARD stage integrates text-conditioned image-to-video diffusion with reinforcement learning, introducing inter-frame conditional guidance and a multi-objective reward function to jointly optimize expression naturalness, facial integrity, and generative efficiency. Extensive experiments on both generation and recognition tasks verify that ARGen substantially enhances synthesis fidelity and improves recognition performance, establishing an interpretable and generalizable generative augmentation paradigm for vision-based affective computing.
EmoScene: A Dual-space Dataset for Controllable Affective Image Generation
Apr 01, 2026Text-to-image diffusion models have achieved high visual fidelity, yet precise control over scene semantics and fine-grained affective tone remains challenging. Human visual affect arises from the rapid integration of contextual meaning, including valence, arousal, and dominance, with perceptual cues such as color harmony, luminance contrast, texture variation, curvature, and spatial layout. However, current text-to-image models rarely represent affective and perceptual factors within a unified representation, which limits their ability to synthesize scenes with coherent and nuanced emotional intent. To address this gap, we construct EmoScene, a large-scale dual-space emotion dataset that jointly encodes affective dimensions and perceptual attributes, with contextual semantics provided as supporting annotations. EmoScene contains 1.2M images across more than three hundred real-world scene categories, each annotated with discrete emotion labels, continuous VAD values, perceptual descriptors and textual captions. Multi-space analyses reveal how discrete emotions occupy the VAD space and how affect systematically correlates with scene-level perceptual factors. To benchmark EmoScene, we provide a lightweight reference baseline that injects dual-space controls into a frozen diffusion backbone via shallow cross-attention modulation, serving as a reproducible probe of affect controllability enabled by dual-space supervision.
Hierarchical Visual Relocalization with Nearest View Synthesis from Feature Gaussian Splatting
Mar 31, 2026Visual relocalization is a fundamental task in the field of 3D computer vision, estimating a camera's pose when it revisits a previously known scene. While point-based hierarchical relocalization methods have shown strong scalability and efficiency, they are often limited by sparse image observations and weak feature matching. In this work, we propose SplatHLoc, a novel hierarchical visual relocalization framework that uses Feature Gaussian Splatting as the scene representation. To address the sparsity of database images, we propose an adaptive viewpoint retrieval method that synthesizes virtual candidates with viewpoints more closely aligned with the query, thereby improving the accuracy of initial pose estimation. For feature matching, we observe that Gaussian-rendered features and those extracted directly from images exhibit different strengths across the two-stage matching process: the former performs better in the coarse stage, while the latter proves more effective in the fine stage. Therefore, we introduce a hybrid feature matching strategy, enabling more accurate and efficient pose estimation. Extensive experiments on both indoor and outdoor datasets show that SplatHLoc enhances the robustness of visual relocalization, setting a new state-of-the-art.
Unifying Stable Optimization and Reference Regularization in RLHF
Feb 12, 2026Reinforcement Learning from Human Feedback (RLHF) has advanced alignment capabilities significantly but remains hindered by two core challenges: \textbf{reward hacking} and \textbf{stable optimization}. Current solutions independently address these issues through separate regularization strategies, specifically a KL-divergence penalty against a supervised fine-tuned model ($π_0$) to mitigate reward hacking, and policy ratio clipping towards the current policy ($π_t$) to promote stable alignment. However, the implicit trade-off arising from simultaneously regularizing towards both $π_0$ and $π_t$ remains under-explored. In this paper, we introduce a unified regularization approach that explicitly balances the objectives of preventing reward hacking and maintaining stable policy updates. Our simple yet principled alignment objective yields a weighted supervised fine-tuning loss with a superior trade-off, which demonstrably improves both alignment results and implementation complexity. Extensive experiments across diverse benchmarks validate that our method consistently outperforms RLHF and online preference learning methods, achieving enhanced alignment performance and stability.
SuperPlace: The Renaissance of Classical Feature Aggregation for Visual Place Recognition in the Era of Foundation Models
Jun 16, 2025Recent visual place recognition (VPR) approaches have leveraged foundation models (FM) and introduced novel aggregation techniques. However, these methods have failed to fully exploit key concepts of FM, such as the effective utilization of extensive training sets, and they have overlooked the potential of classical aggregation methods, such as GeM and NetVLAD. Building on these insights, we revive classical feature aggregation methods and develop more fundamental VPR models, collectively termed SuperPlace. First, we introduce a supervised label alignment method that enables training across various VPR datasets within a unified framework. Second, we propose G$^2$M, a compact feature aggregation method utilizing two GeMs, where one GeM learns the principal components of feature maps along the channel dimension and calibrates the output of the other. Third, we propose the secondary fine-tuning (FT$^2$) strategy for NetVLAD-Linear (NVL). NetVLAD first learns feature vectors in a high-dimensional space and then compresses them into a lower-dimensional space via a single linear layer. Extensive experiments highlight our contributions and demonstrate the superiority of SuperPlace. Specifically, G$^2$M achieves promising results with only one-tenth of the feature dimensions compared to recent methods. Moreover, NVL-FT$^2$ ranks first on the MSLS leaderboard.
Relative Contrastive Learning for Sequential Recommendation with Similarity-based Positive Pair Selection
Apr 27, 2025Contrastive Learning (CL) enhances the training of sequential recommendation (SR) models through informative self-supervision signals. Existing methods often rely on data augmentation strategies to create positive samples and promote representation invariance. Some strategies such as item reordering and item substitution may inadvertently alter user intent. Supervised Contrastive Learning (SCL) based methods find an alternative to augmentation-based CL methods by selecting same-target sequences (interaction sequences with the same target item) to form positive samples. However, SCL-based methods suffer from the scarcity of same-target sequences and consequently lack enough signals for contrastive learning. In this work, we propose to use similar sequences (with different target items) as additional positive samples and introduce a Relative Contrastive Learning (RCL) framework for sequential recommendation. RCL comprises a dual-tiered positive sample selection module and a relative contrastive learning module. The former module selects same-target sequences as strong positive samples and selects similar sequences as weak positive samples. The latter module employs a weighted relative contrastive loss, ensuring that each sequence is represented closer to its strong positive samples than its weak positive samples. We apply RCL on two mainstream deep learning-based SR models, and our empirical results reveal that RCL can achieve 4.88% improvement averagely than the state-of-the-art SR methods on five public datasets and one private dataset.
Direct Advantage Regression: Aligning LLMs with Online AI Reward
Apr 19, 2025Online AI Feedback (OAIF) presents a promising alternative to Reinforcement Learning from Human Feedback (RLHF) by utilizing online AI preference in aligning language models (LLMs). However, the straightforward replacement of humans with AI deprives LLMs from learning more fine-grained AI supervision beyond binary signals. In this paper, we propose Direct Advantage Regression (DAR), a simple alignment algorithm using online AI reward to optimize policy improvement through weighted supervised fine-tuning. As an RL-free approach, DAR maintains theoretical consistency with online RLHF pipelines while significantly reducing implementation complexity and improving learning efficiency. Our empirical results underscore that AI reward is a better form of AI supervision consistently achieving higher human-AI agreement as opposed to AI preference. Additionally, evaluations using GPT-4-Turbo and MT-bench show that DAR outperforms both OAIF and online RLHF baselines.
DeFine: A Decomposed and Fine-Grained Annotated Dataset for Long-form Article Generation
Mar 10, 2025



Long-form article generation (LFAG) presents challenges such as maintaining logical consistency, comprehensive topic coverage, and narrative coherence across extended articles. Existing datasets often lack both the hierarchical structure and fine-grained annotation needed to effectively decompose tasks, resulting in shallow, disorganized article generation. To address these limitations, we introduce DeFine, a Decomposed and Fine-grained annotated dataset for long-form article generation. DeFine is characterized by its hierarchical decomposition strategy and the integration of domain-specific knowledge with multi-level annotations, ensuring granular control and enhanced depth in article generation. To construct the dataset, a multi-agent collaborative pipeline is proposed, which systematically segments the generation process into four parts: Data Miner, Cite Retreiver, Q&A Annotator and Data Cleaner. To validate the effectiveness of DeFine, we designed and tested three LFAG baselines: the web retrieval, the local retrieval, and the grounded reference. We fine-tuned the Qwen2-7b-Instruct model using the DeFine training dataset. The experimental results showed significant improvements in text quality, specifically in topic coverage, depth of information, and content fidelity. Our dataset publicly available to facilitate future research.
An Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024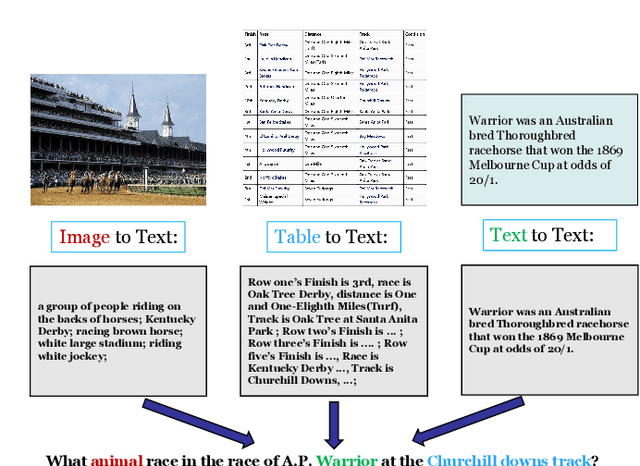



With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research
PISR: Polarimetric Neural Implicit Surface Reconstruction for Textureless and Specular Objects
Sep 22, 2024



Neural implicit surface reconstruction has achieved remarkable progress recently. Despite resorting to complex radiance modeling, state-of-the-art methods still struggle with textureless and specular surfaces. Different from RGB images, polarization images can provide direct constraints on the azimuth angles of the surface normals. In this paper, we present PISR, a novel method that utilizes a geometrically accurate polarimetric loss to refine shape independently of appearance. In addition, PISR smooths surface normals in image space to eliminate severe shape distortions and leverages the hash-grid-based neural signed distance function to accelerate the reconstruction. Experimental results demonstrate that PISR achieves higher accuracy and robustness, with an L1 Chamfer distance of 0.5 mm and an F-score of 99.5% at 1 mm, while converging 4~30 times faster than previous polarimetric surface reconstruction methods.