 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025



To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
An Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024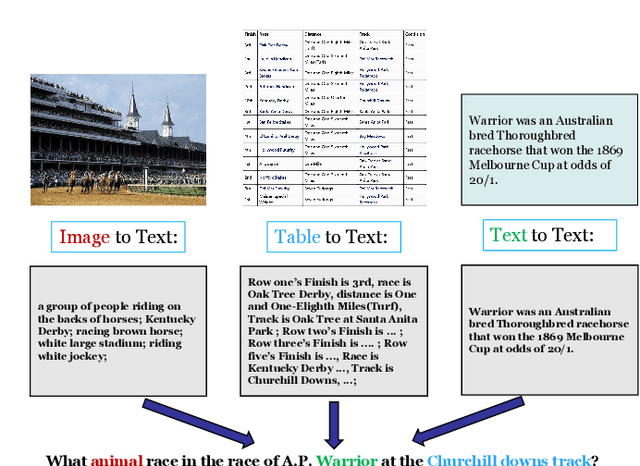



With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research