 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Diffusion LLMs via Temporal-Spatial Parallel Decoding and Confidence Extrapolation
May 29, 2026Diffusion-based large language models (dLLMs) support parallel text generation via iterative denoising, yet inference remains latency-heavy because many steps are spent on redundant refinement and repeated remasking of tokens whose final values are already determined. Prior acceleration methods mainly depend on step-local confidence heuristics or fixed schedules, which are sensitive to prompt and task variation and ignore strong positional effects within a sequence. We cast diffusion decoding as a dynamic control problem and show that token-wise denoising trajectories provide the key signal for reliable control. We propose a trace-aware decoding framework with two components. First, Temporal-Spatial Parallel Decoding (TSPD) uses a lightweight temporalspatial controller that consumes per-token trajectory features, including confidence, entropy, and momentum, together with token position, to decide when a token has converged and can be safely fixed. Second, we introduce Confidence Extrapolation (CE), a training-free state-space module that forecasts future logit trends with uncertainty to support proactive decisions, including safe look-ahead and targeted stabilization when trajectories are oscillatory or underconfident. Together, TSPD and CE reduce unnecessary denoising iterations while preserving output quality, and they compose cleanly with system optimizations such as KV caching.
RVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation
Dec 08, 2025Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024



Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023



Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
PANACEA cough sound-based diagnosis of COVID-19 for the DiCOVA 2021 Challenge
Jun 07, 2021
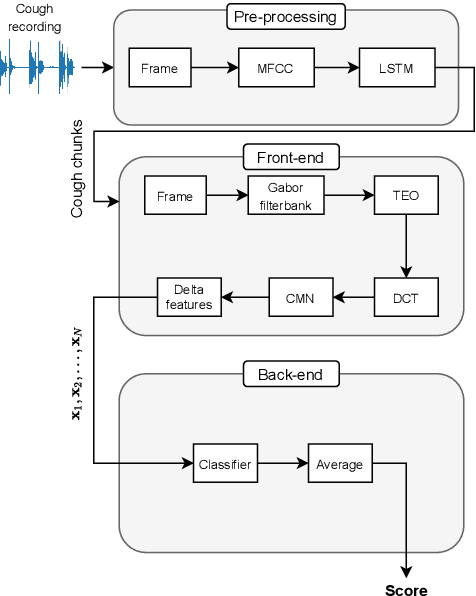
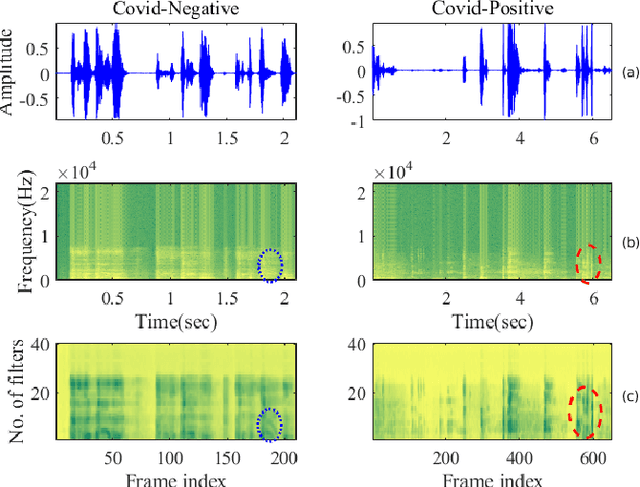
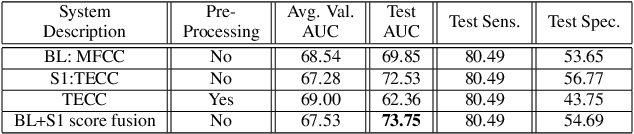
The COVID-19 pandemic has led to the saturation of public health services worldwide. In this scenario, the early diagnosis of SARS-Cov-2 infections can help to stop or slow the spread of the virus and to manage the demand upon health services. This is especially important when resources are also being stretched by heightened demand linked to other seasonal diseases, such as the flu. In this context, the organisers of the DiCOVA 2021 challenge have collected a database with the aim of diagnosing COVID-19 through the use of coughing audio samples. This work presents the details of the automatic system for COVID-19 detection from cough recordings presented by team PANACEA. This team consists of researchers from two European academic institutions and one company: EURECOM (France), University of Granada (Spain), and Biometric Vox S.L. (Spain). We developed several systems based on established signal processing and machine learning methods. Our best system employs a Teager energy operator cepstral coefficients (TECCs) based frontend and Light gradient boosting machine (LightGBM) backend. The AUC obtained by this system on the test set is 76.31% which corresponds to a 10% improvement over the official baseline.
Teacher-Critical Training Strategies for Image Captioning
Sep 30, 2020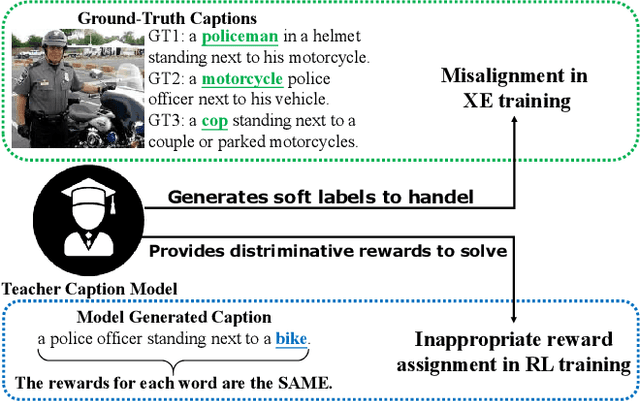
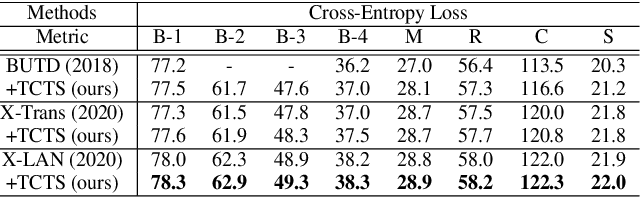
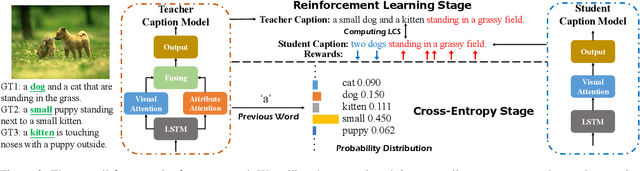
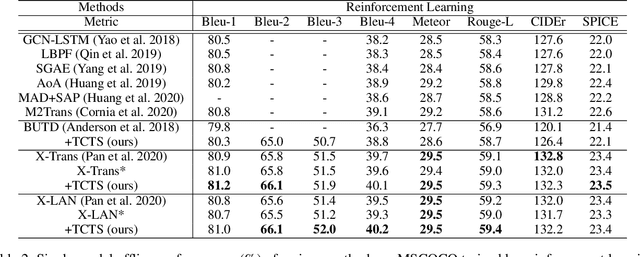
Existing image captioning models are usually trained by cross-entropy (XE) loss and reinforcement learning (RL), which set ground-truth words as hard targets and force the captioning model to learn from them. However, the widely adopted training strategies suffer from misalignment in XE training and inappropriate reward assignment in RL training. To tackle these problems, we introduce a teacher model that serves as a bridge between the ground-truth caption and the caption model by generating some easier-to-learn word proposals as soft targets. The teacher model is constructed by incorporating the ground-truth image attributes into the baseline caption model. To effectively learn from the teacher model, we propose Teacher-Critical Training Strategies (TCTS) for both XE and RL training to facilitate better learning processes for the caption model. Experimental evaluations of several widely adopted caption models on the benchmark MSCOCO dataset show the proposed TCTS comprehensively enhances most evaluation metrics, especially the Bleu and Rouge-L scores, in both training stages. TCTS is able to achieve to-date the best published single model Bleu-4 and Rouge-L performances of 40.2% and 59.4% on the MSCOCO Karpathy test split. Our codes and pre-trained models will be open-sourced.
Coalitional Games with Stochastic Characteristic Functions and Private Types
Oct 25, 2019
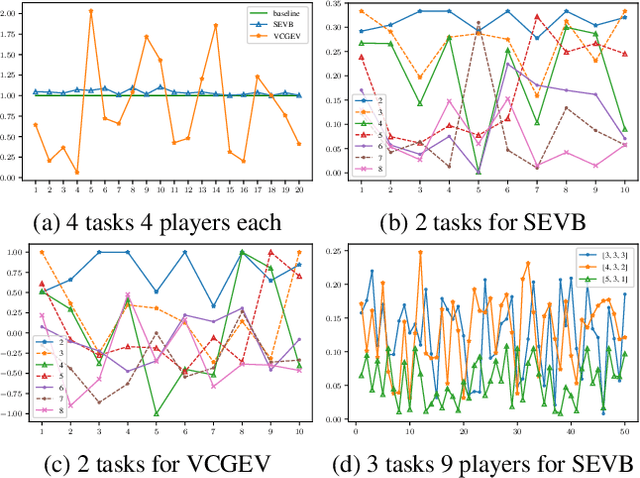
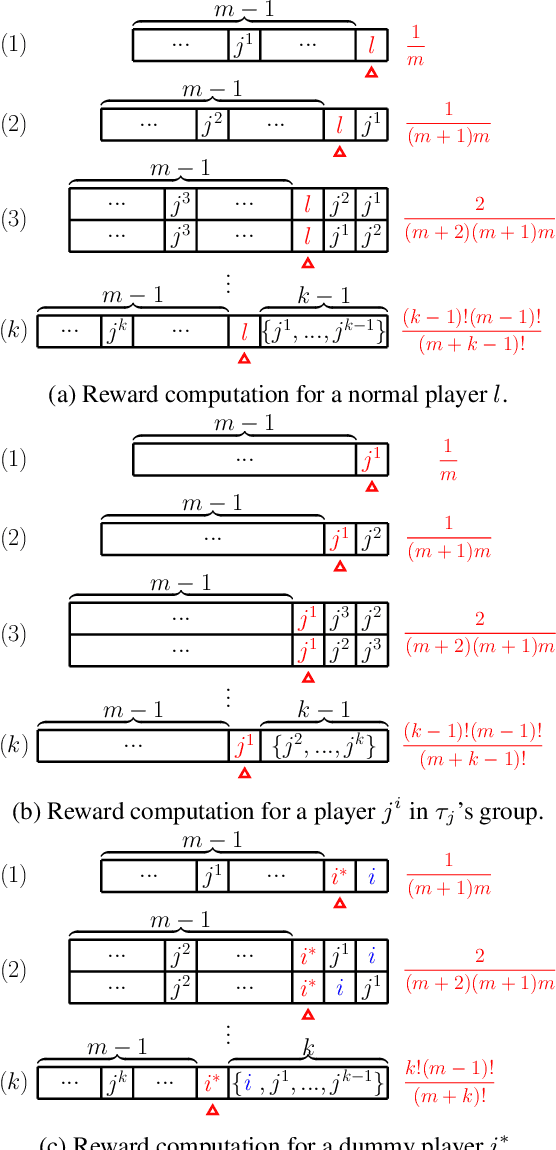
The research on coalitional games has focused on how to share the reward among a coalition such that players are incentivised to collaborate together. It assumes that the (deterministic or stochastic) characteristic function is known in advance. This paper studies a new setting (a task allocation problem) where the characteristic function is not known and it is controlled by some private information from the players. Hence, the challenge here is twofold: (i) incentivize players to reveal their private information truthfully, (ii) incentivize them to collaborate together. We show that existing reward distribution mechanisms or auctions cannot solve the challenge. Hence, we propose the very first mechanism for the problem from the perspective of both mechanism design and coalitional games.