 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecRLBench: A Benchmark for Generalization in Specification-Guided Reinforcement Learning
Apr 27, 2026Specification-guided reinforcement learning (RL) provides a principled framework for encoding complex, temporally extended tasks using formal specifications such as linear temporal logic (LTL). While recent methods have shown promising results, their ability to generalize across unseen specifications and diverse environments remains insufficiently understood. In this work, we introduce SpecRLBench, a benchmark designed to evaluate the generalization capabilities of LTL-based specification-guided RL methods. The benchmark spans multiple difficulty levels across navigation and manipulation domains, incorporating both static and dynamic environments, diverse robot dynamics, and varied observation modalities. Through extensive empirical evaluation, we characterize the strengths and limitations of existing approaches and reveal the challenges that emerge as specification and environment complexity increase. SpecRLBench provides a structured platform for systematic comparison and supports the development of more generalizable specification-guided RL methods. Code is available at https://github.com/BU-DEPEND-Lab/SpecRLBench.
Enhancing Fine-Grained Spatial Grounding in 3D CT Report Generation via Discriminative Guidance
Apr 12, 2026Vision--language models (VLMs) for radiology report generation (RRG) can produce long-form chest CT reports from volumetric scans and show strong potential to improve radiology workflow efficiency and consistency. However, existing methods face two key limitations: (i) training supervision is often coarse, aligning a whole CT volume with a full free-text report without explicit alignment for fine-grained attributes or pathology locations; and (ii) evaluation is typically holistic (lexical overlap, entity matching, or LLM-as-a-judge scores) and not diagnostic for spatial grounding. We propose \emph{Discriminative Cue-Prompting with Prompt Dropout (DCP-PD)}, a plug-and-play framework that distills fine-grained cues from free-text reports and uses them to guide report generation while mitigating shortcut reliance via prompt dropout. DCP-PD achieves state-of-the-art performance on CT-RATE, improving macro F1 from $=0.501$ to $0.603$ (20% relative), and substantially boosts out-of-distribution performance on Rad-ChestCT from F1 $=0.266$ to $0.503$ (89% relative). Finally, we introduce a hierarchical, location-aware question-set protocol (presence $\rightarrow$ laterality $\rightarrow$ lobe) to directly assess pathology-location grounding, showing that fine-grained spatial localization remains challenging even for models that score highly on current benchmarks.
Multi-Robot Multi-Queue Control via Exhaustive Assignment Actor-Critic Learning
Apr 04, 2026We study online task allocation for multi-robot, multi-queue systems with asymmetric stochastic arrivals and switching delays. We formulate the problem in discrete time: each location can host at most one robot per slot, servicing a task consumes one slot, switching between locations incurs a one-slot travel delay, and arrivals at locations are independent Bernoulli processes with heterogeneous rates. Building on our previous structural result that optimal policies are of exhaustive type, we formulate a discounted-cost Markov decision process and develop an exhaustive-assignment actor-critic policy architecture that enforces exhaustive service by construction and learns only the next-queue allocation for idle robots. Unlike the exhaustive-serve-longest (ESL) queue rule, whose optimality is known only under symmetry, the proposed policy adapts to asymmetry in arrival rates. Across different server-location ratios, loads, and asymmetric arrival profiles, the proposed policy consistently achieves lower discounted holding cost and smaller mean queue length than the ESL baseline, while remaining near-optimal on instances where an optimal benchmark is available. These results show that structure-aware actor-critic methods provide an effective approach for real-time multi-robot scheduling.
VLM-UQBench: A Benchmark for Modality-Specific and Cross-Modality Uncertainties in Vision Language Models
Feb 09, 2026Uncertainty quantification (UQ) is vital for ensuring that vision-language models (VLMs) behave safely and reliably. A central challenge is to localize uncertainty to its source, determining whether it arises from the image, the text, or misalignment between the two. We introduce VLM-UQBench, a benchmark for modality-specific and cross-modal data uncertainty in VLMs, It consists of 600 real-world samples drawn from the VizWiz dataset, curated into clean, image-, text-, and cross-modal uncertainty subsets, and a scalable perturbation pipeline with 8 visual, 5 textual, and 3 cross-modal perturbations. We further propose two simple metrics that quantify the sensitivity of UQ scores to these perturbations and their correlation with hallucinations, and use them to evaluate a range of UQ methods across four VLMs and three datasets. Empirically, we find that: (i) existing UQ methods exhibit strong modality-specific specialization and substantial dependence on the underlying VLM, (ii) modality-specific uncertainty frequently co-occurs with hallucinations while current UQ scores provide only weak and inconsistent risk signals, and (iii) although UQ methods can rival reasoning-based chain-of-thought baselines on overt, group-level ambiguity, they largely fail to detect the subtle, instance-level ambiguity introduced by our perturbation pipeline. These results highlight a significant gap between current UQ practices and the fine-grained, modality-aware uncertainty required for reliable VLM deployment.
Names Don't Matter: Symbol-Invariant Transformer for Open-Vocabulary Learning
Jan 30, 2026Current neural architectures lack a principled way to handle interchangeable tokens, i.e., symbols that are semantically equivalent yet distinguishable, such as bound variables. As a result, models trained on fixed vocabularies often struggle to generalize to unseen symbols, even when the underlying semantics remain unchanged. We propose a novel Transformer-based mechanism that is provably invariant to the renaming of interchangeable tokens. Our approach employs parallel embedding streams to isolate the contribution of each interchangeable token in the input, combined with an aggregated attention mechanism that enables structured information sharing across streams. Experimental results confirm the theoretical guarantees of our method and demonstrate substantial performance gains on open-vocabulary tasks that require generalization to novel symbols.
Quantifying the advantage of vector over scalar magnetic sensor networks for undersea surveillance
Dec 30, 2025Magnetic monitoring of maritime environments is an important problem for monitoring and optimising shipping, as well as national security. New developments in compact, fibre-coupled quantum magnetometers have led to the opportunity to critically evaluate how best to create such a sensor network. Here we explore various magnetic sensor network architectures for target identification. Our modelling compares networks of scalar vs vector magnetometers. We implement an unscented Kalman filter approach to perform target tracking, and we find that vector networks provide a significant improvement in target tracking, specifically tracking accuracy and resilience compared with scalar networks.
Anomaly Detection and Generation with Diffusion Models: A Survey
Jun 11, 2025



Anomaly detection (AD) plays a pivotal role across diverse domains, including cybersecurity, finance, healthcare, and industrial manufacturing, by identifying unexpected patterns that deviate from established norms in real-world data. Recent advancements in deep learning, specifically diffusion models (DMs), have sparked significant interest due to their ability to learn complex data distributions and generate high-fidelity samples, offering a robust framework for unsupervised AD. In this survey, we comprehensively review anomaly detection and generation with diffusion models (ADGDM), presenting a tutorial-style analysis of the theoretical foundations and practical implementations and spanning images, videos, time series, tabular, and multimodal data. Crucially, unlike existing surveys that often treat anomaly detection and generation as separate problems, we highlight their inherent synergistic relationship. We reveal how DMs enable a reinforcing cycle where generation techniques directly address the fundamental challenge of anomaly data scarcity, while detection methods provide critical feedback to improve generation fidelity and relevance, advancing both capabilities beyond their individual potential. A detailed taxonomy categorizes ADGDM methods based on anomaly scoring mechanisms, conditioning strategies, and architectural designs, analyzing their strengths and limitations. We final discuss key challenges including scalability and computational efficiency, and outline promising future directions such as efficient architectures, conditioning strategies, and integration with foundation models (e.g., visual-language models and large language models). By synthesizing recent advances and outlining open research questions, this survey aims to guide researchers and practitioners in leveraging DMs for innovative AD solutions across diverse applications.
ContextModule: Improving Code Completion via Repository-level Contextual Information
Dec 11, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in code completion tasks, where they assist developers by predicting and generating new code in real-time. However, existing LLM-based code completion systems primarily rely on the immediate context of the file being edited, often missing valuable repository-level information, user behaviour and edit history that could improve suggestion accuracy. Additionally, challenges such as efficiently retrieving relevant code snippets from large repositories, incorporating user behavior, and balancing accuracy with low-latency requirements in production environments remain unresolved. In this paper, we propose ContextModule, a framework designed to enhance LLM-based code completion by retrieving and integrating three types of contextual information from the repository: user behavior-based code, similar code snippets, and critical symbol definitions. By capturing user interactions across files and leveraging repository-wide static analysis, ContextModule improves the relevance and precision of generated code. We implement performance optimizations, such as index caching, to ensure the system meets the latency constraints of real-world coding environments. Experimental results and industrial practise demonstrate that ContextModule significantly improves code completion accuracy and user acceptance rates.
Semantic Consistency-Based Uncertainty Quantification for Factuality in Radiology Report Generation
Dec 05, 2024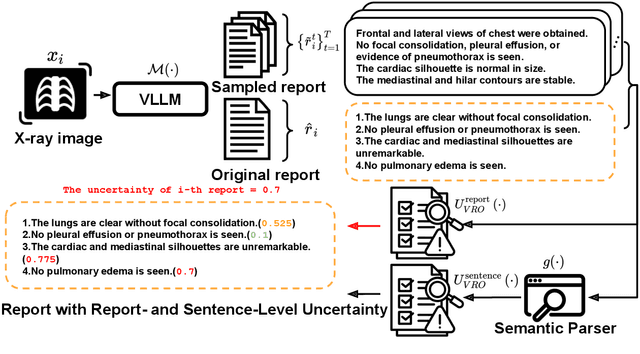
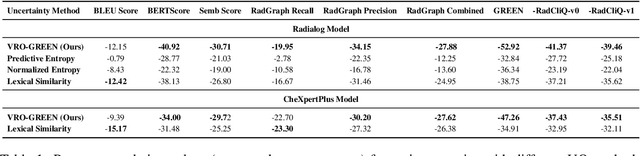

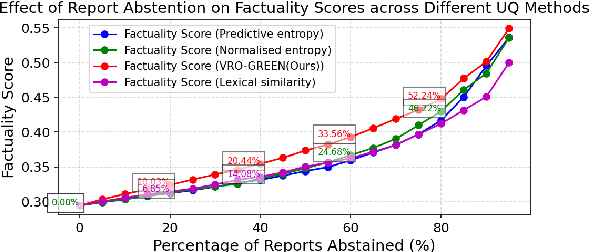
Radiology report generation (RRG) has shown great potential in assisting radiologists by automating the labor-intensive task of report writing. While recent advancements have improved the quality and coherence of generated reports, ensuring their factual correctness remains a critical challenge. Although generative medical Vision Large Language Models (VLLMs) have been proposed to address this issue, these models are prone to hallucinations and can produce inaccurate diagnostic information. To address these concerns, we introduce a novel Semantic Consistency-Based Uncertainty Quantification framework that provides both report-level and sentence-level uncertainties. Unlike existing approaches, our method does not require modifications to the underlying model or access to its inner state, such as output token logits, thus serving as a plug-and-play module that can be seamlessly integrated with state-of-the-art models. Extensive experiments demonstrate the efficacy of our method in detecting hallucinations and enhancing the factual accuracy of automatically generated radiology reports. By abstaining from high-uncertainty reports, our approach improves factuality scores by $10$%, achieved by rejecting $20$% of reports using the Radialog model on the MIMIC-CXR dataset. Furthermore, sentence-level uncertainty flags the lowest-precision sentence in each report with an $82.9$% success rate.
Rethinking Inverse Reinforcement Learning: from Data Alignment to Task Alignment
Oct 31, 2024



Many imitation learning (IL) algorithms use inverse reinforcement learning (IRL) to infer a reward function that aligns with the demonstration. However, the inferred reward functions often fail to capture the underlying task objectives. In this paper, we propose a novel framework for IRL-based IL that prioritizes task alignment over conventional data alignment. Our framework is a semi-supervised approach that leverages expert demonstrations as weak supervision to derive a set of candidate reward functions that align with the task rather than only with the data. It then adopts an adversarial mechanism to train a policy with this set of reward functions to gain a collective validation of the policy's ability to accomplish the task. We provide theoretical insights into this framework's ability to mitigate task-reward misalignment and present a practical implementation. Our experimental results show that our framework outperforms conventional IL baselines in complex and transfer learning scenarios.