 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftSkill: Behavioral Compression for Contextual Adaptation
Jun 18, 2026Agent skills are commonly deployed as natural-language Markdown files that encode answer policies, evidence-use habits, and task procedures. These files are readable and portable, but they are consumed indirectly: for each task instance, a frozen language model must translate a long textual artifact into generation-time behavior. This paper asks whether a natural-language skill can instead initialize a compact continuous context object, refined by a trainable soft delta while the base model remains frozen. We propose SoftSkill, a frozen-backbone method that tunes such soft skills with next-token prediction and deploys them as latent behavioral priors at inference time. In our main single-round setting, a length-32 SoftSkill prefix on Qwen3.5-4B improves over no-skill prompting by 8.3 points on SearchQA, 42.1 points on LiveMath, and 1.3 points on DocVQA. Relative to SkillOpt, SoftSkill improves accuracy by 5.2 points on SearchQA and 12.5 points on LiveMath, while replacing hundreds to thousands of Markdown skill tokens with a few virtual tokens. We further study agentic execution as a harder boundary case, where sparse trajectory imitation provides useful signal but does not yet robustly compress long-horizon procedural behavior. More broadly, the results suggest that some task skills are better treated not as additional Markdown to be reinterpreted at inference time, but as compact latent controls over how a frozen model enters the task.
UI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
May 28, 2026Recent advances in mobile GUI agents have shown strong potential for automating mobile tasks, but most effective systems still depend on large vision-language models for screenshot understanding and long-horizon planning. Small GUI agents that can be deployed directly on mobile devices are more attractive for practical use, offering lower inference cost and better protection of sensitive on-device information. However, due to limited model capacity, such lightweight agents remain unreliable when planning and executing GUI tasks end-to-end from screenshots alone. We propose Knowledge-Oriented Behavior Exploration (\textbf{UI-KOBE}), a framework that improves lightweight mobile GUI agents with reusable app-specific graph knowledge. UI-KOBE first autonomously explores a mobile application and constructs an app knowledge graph, where nodes represent distinct UI states and edges represent executable transitions. At runtime, a lightweight GUI agent uses the graph as external guidance: given a user task and the current screenshot, it identifies the current graph node and selects among self-loop actions, neighboring transitions, task completion, or fallback free actions associated with that node. By supporting runtime decisions with app-specific graph guidance, UI-KOBE reduces the burden of end-to-end GUI planning and helps lightweight models perform mobile GUI tasks more effectively, offering a practical step toward efficient, interpretable, and privacy-conscious on-device GUI agents.
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
Self-Distilled Trajectory-Aware Boltzmann Modeling: Bridging the Training-Inference Discrepancy in Diffusion Language Models
May 12, 2026Diffusion Language Models (DLMs) have recently emerged as a promising alternative to autoregressive language models, offering stronger global awareness and highly parallel generation. However, post-training DLMs with standard Negative Evidence Lower Bound (NELBO)-based supervised fine-tuning remains inefficient: training reconstructs randomly masked tokens in a single step, whereas inference follows a confidence-guided, multi-step easy-to-hard denoising trajectory. Recent trajectory-based self-distillation methods exploit such inference trajectories mainly for sampling-step compression and acceleration, often improving decoding efficiency without substantially enhancing the model's underlying capability, and may even degrade performance under full diffusion decoding. In this work, we ask whether self-distilled trajectories can be used not merely for faster inference, but for genuine knowledge acquisition. Although these trajectories lie on the pretrained DLM's own distributional manifold and thus offer a potentially lower optimization barrier, we find that naively fine-tuning on them with standard NELBO objectives yields only marginal gains. To address this limitation, we propose \textbf{T}rajectory-\textbf{A}ligned optimization via \textbf{Bo}ltzmann \textbf{M}odeling (\textbf{TABOM}), a self-distilled trajectory-based post-training framework that aligns training with the easy-to-hard structure of inference. TABOM models the inference unmasking preference as a Boltzmann distribution over predictive entropies and derives a tractable pairwise ranking objective to align the model's certainty ordering with the observed decoding trajectory. Empirically, TABOM achieves substantial gains in new domains, expands the effective knowledge boundary of DLMs, and significantly mitigates catastrophic forgetting compared with standard SFT.
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
Test-Time-Matching: Decouple Personality, Memory, and Linguistic Style in LLM-based Role-Playing Language Agent
Jul 23, 2025



The rapid advancement of large language models (LLMs) has enabled role-playing language agents to demonstrate significant potential in various applications. However, relying solely on prompts and contextual inputs often proves insufficient for achieving deep immersion in specific roles, particularly well-known fictional or public figures. On the other hand, fine-tuning-based approaches face limitations due to the challenges associated with data collection and the computational resources required for training, thereby restricting their broader applicability. To address these issues, we propose Test-Time-Matching (TTM), a training-free role-playing framework through test-time scaling and context engineering. TTM uses LLM agents to automatically decouple a character's features into personality, memory, and linguistic style. Our framework involves a structured, three-stage generation pipeline that utilizes these features for controlled role-playing. It achieves high-fidelity role-playing performance, also enables seamless combinations across diverse linguistic styles and even variations in personality and memory. We evaluate our framework through human assessment, and the results demonstrate that our method achieves the outstanding performance in generating expressive and stylistically consistent character dialogues.
FedHGN: A Federated Framework for Heterogeneous Graph Neural Networks
May 16, 2023



Heterogeneous graph neural networks (HGNNs) can learn from typed and relational graph data more effectively than conventional GNNs. With larger parameter spaces, HGNNs may require more training data, which is often scarce in real-world applications due to privacy regulations (e.g., GDPR). Federated graph learning (FGL) enables multiple clients to train a GNN collaboratively without sharing their local data. However, existing FGL methods mainly focus on homogeneous GNNs or knowledge graph embeddings; few have considered heterogeneous graphs and HGNNs. In federated heterogeneous graph learning, clients may have private graph schemas. Conventional FL/FGL methods attempting to define a global HGNN model would violate schema privacy. To address these challenges, we propose FedHGN, a novel and general FGL framework for HGNNs. FedHGN adopts schema-weight decoupling to enable schema-agnostic knowledge sharing and employs coefficients alignment to stabilize the training process and improve HGNN performance. With better privacy preservation, FedHGN consistently outperforms local training and conventional FL methods on three widely adopted heterogeneous graph datasets with varying client numbers. The code is available at https://github.com/cynricfu/FedHGN .
MECCH: Metapath Context Convolution-based Heterogeneous Graph Neural Networks
Nov 23, 2022Heterogeneous graph neural networks (HGNNs) were proposed for representation learning on structural data with multiple types of nodes and edges. Researchers have developed metapath-based HGNNs to deal with the over-smoothing problem of relation-based HGNNs. However, existing metapath-based models suffer from either information loss or high computation costs. To address these problems, we design a new Metapath Context Convolution-based Heterogeneous Graph Neural Network (MECCH). Specifically, MECCH applies three novel components after feature preprocessing to extract comprehensive information from the input graph efficiently: (1) metapath context construction, (2) metapath context encoder, and (3) convolutional metapath fusion. Experiments on five real-world heterogeneous graph datasets for node classification and link prediction show that MECCH achieves superior prediction accuracy compared with state-of-the-art baselines with improved computational efficiency.
Retrieving and ranking short medical questions with two stages neural matching model
Nov 16, 2020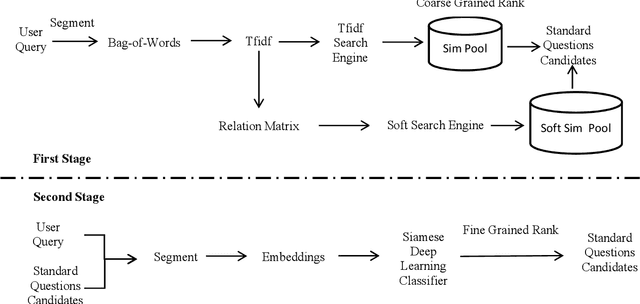
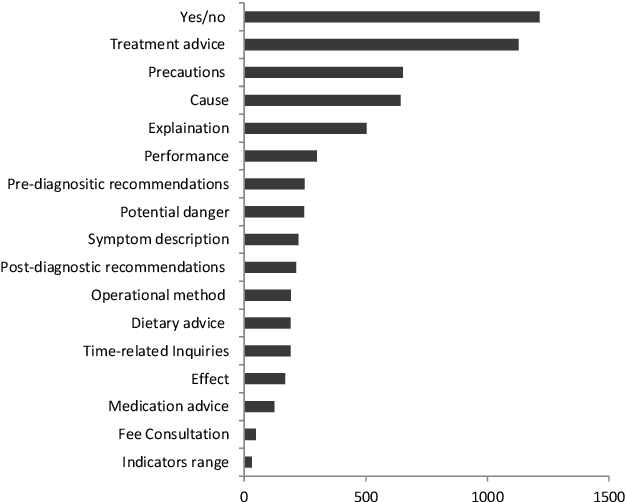
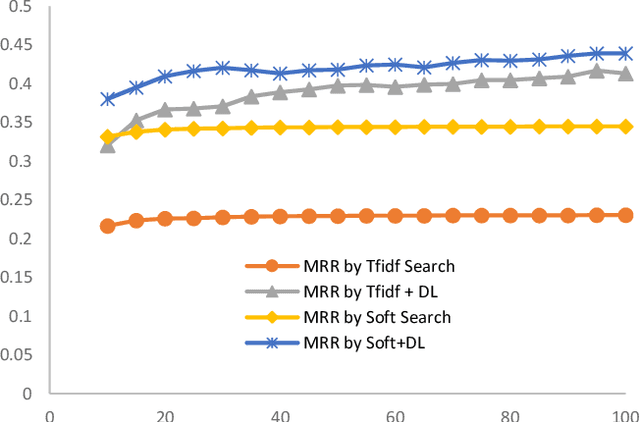
Internet hospital is a rising business thanks to recent advances in mobile web technology and high demand of health care services. Online medical services become increasingly popular and active. According to US data in 2018, 80 percent of internet users have asked health-related questions online. Numerous data is generated in unprecedented speed and scale. Those representative questions and answers in medical fields are valuable raw data sources for medical data mining. Automated machine interpretation on those sheer amount of data gives an opportunity to assist doctors to answer frequently asked medical-related questions from the perspective of information retrieval and machine learning approaches. In this work, we propose a novel two-stage framework for the semantic matching of query-level medical questions.