 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Text Classification with Dual Contrastive Consistency
Sep 29, 2022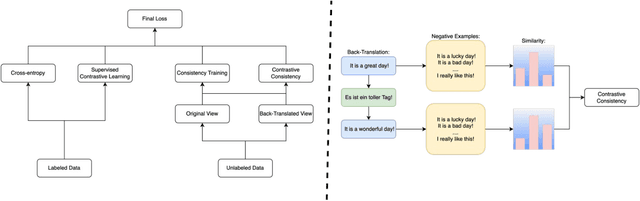
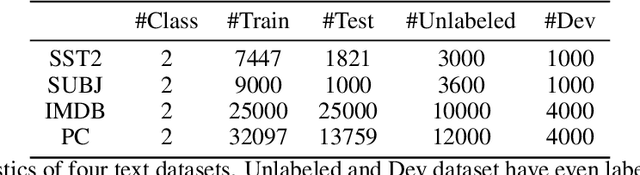
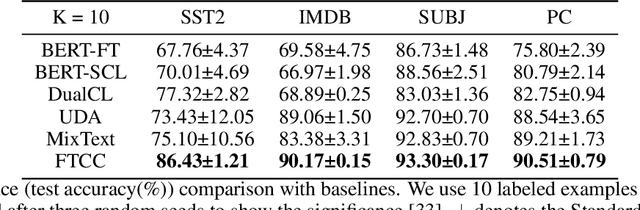

In this paper, we explore how to utilize pre-trained language model to perform few-shot text classification where only a few annotated examples are given for each class. Since using traditional cross-entropy loss to fine-tune language model under this scenario causes serious overfitting and leads to sub-optimal generalization of model, we adopt supervised contrastive learning on few labeled data and consistency-regularization on vast unlabeled data. Moreover, we propose a novel contrastive consistency to further boost model performance and refine sentence representation. After conducting extensive experiments on four datasets, we demonstrate that our model (FTCC) can outperform state-of-the-art methods and has better robustness.
TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Sep 15, 2022
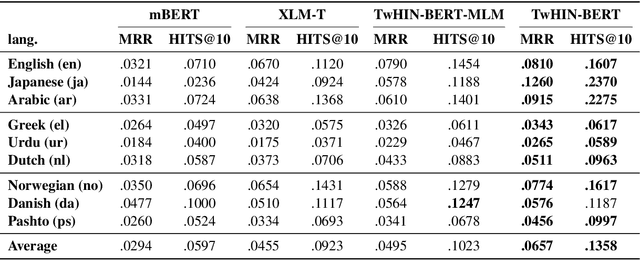
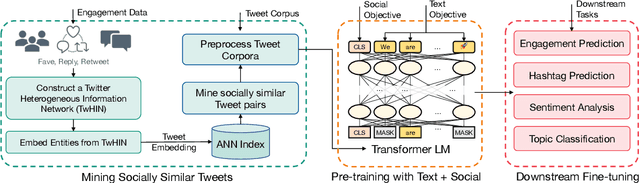
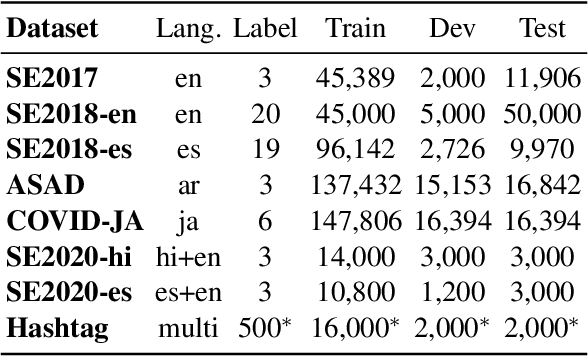
We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.
MentorGNN: Deriving Curriculum for Pre-Training GNNs
Aug 21, 2022
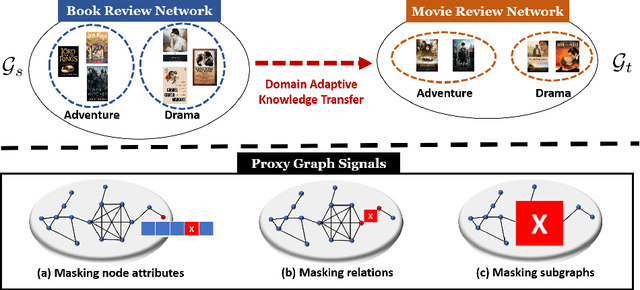
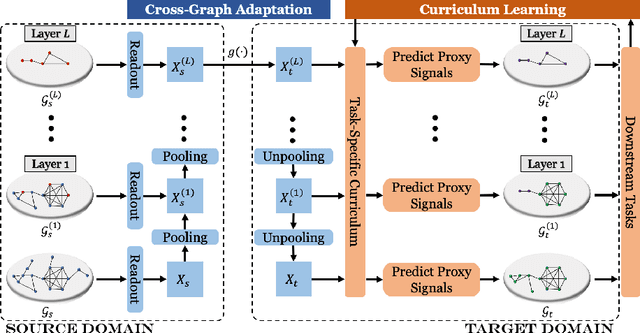
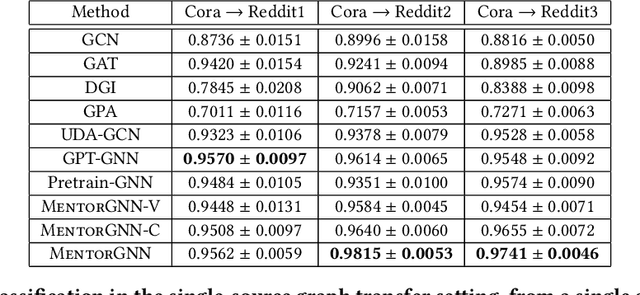
Graph pre-training strategies have been attracting a surge of attention in the graph mining community, due to their flexibility in parameterizing graph neural networks (GNNs) without any label information. The key idea lies in encoding valuable information into the backbone GNNs, by predicting the masked graph signals extracted from the input graphs. In order to balance the importance of diverse graph signals (e.g., nodes, edges, subgraphs), the existing approaches are mostly hand-engineered by introducing hyperparameters to re-weight the importance of graph signals. However, human interventions with sub-optimal hyperparameters often inject additional bias and deteriorate the generalization performance in the downstream applications. This paper addresses these limitations from a new perspective, i.e., deriving curriculum for pre-training GNNs. We propose an end-to-end model named MentorGNN that aims to supervise the pre-training process of GNNs across graphs with diverse structures and disparate feature spaces. To comprehend heterogeneous graph signals at different granularities, we propose a curriculum learning paradigm that automatically re-weighs graph signals in order to ensure a good generalization in the target domain. Moreover, we shed new light on the problem of domain adaption on relational data (i.e., graphs) by deriving a natural and interpretable upper bound on the generalization error of the pre-trained GNNs. Extensive experiments on a wealth of real graphs validate and verify the performance of MentorGNN.
Few-Shot Fine-Grained Entity Typing with Automatic Label Interpretation and Instance Generation
Jun 28, 2022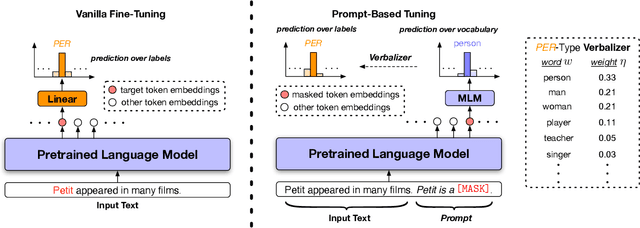
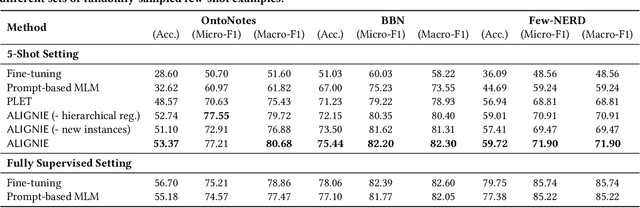
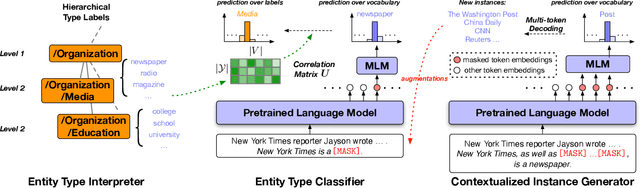
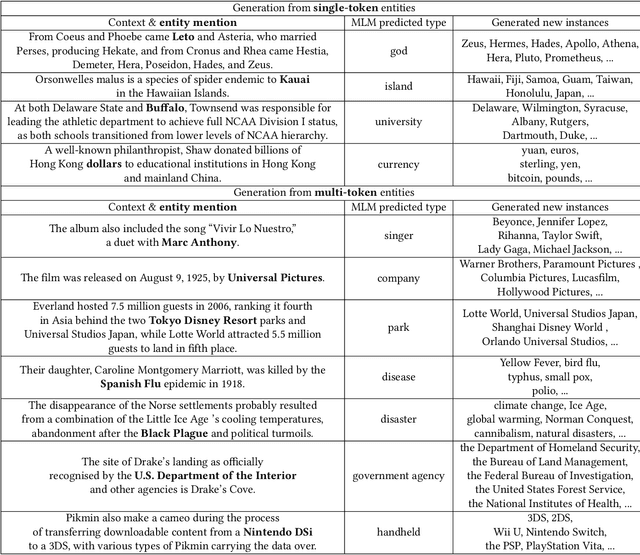
We study the problem of few-shot Fine-grained Entity Typing (FET), where only a few annotated entity mentions with contexts are given for each entity type. Recently, prompt-based tuning has demonstrated superior performance to standard fine-tuning in few-shot scenarios by formulating the entity type classification task as a ''fill-in-the-blank'' problem. This allows effective utilization of the strong language modeling capability of Pre-trained Language Models (PLMs). Despite the success of current prompt-based tuning approaches, two major challenges remain: (1) the verbalizer in prompts is either manually designed or constructed from external knowledge bases, without considering the target corpus and label hierarchy information, and (2) current approaches mainly utilize the representation power of PLMs, but have not explored their generation power acquired through extensive general-domain pre-training. In this work, we propose a novel framework for few-shot FET consisting of two modules: (1) an entity type label interpretation module automatically learns to relate type labels to the vocabulary by jointly leveraging few-shot instances and the label hierarchy, and (2) a type-based contextualized instance generator produces new instances based on given instances to enlarge the training set for better generalization. On three benchmark datasets, our model outperforms existing methods by significant margins. Code can be found at https://github.com/teapot123/Fine-Grained-Entity-Typing.
TeKo: Text-Rich Graph Neural Networks with External Knowledge
Jun 15, 2022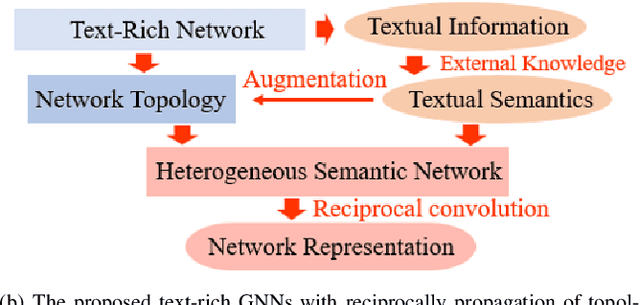
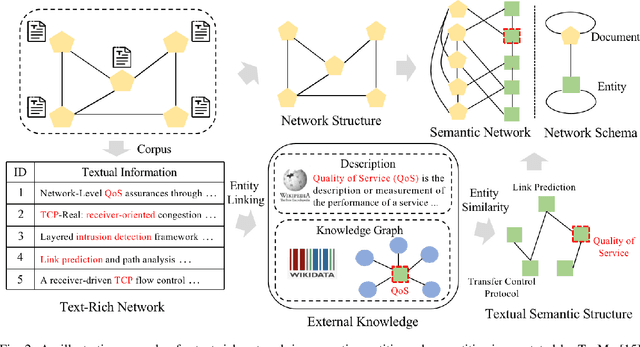
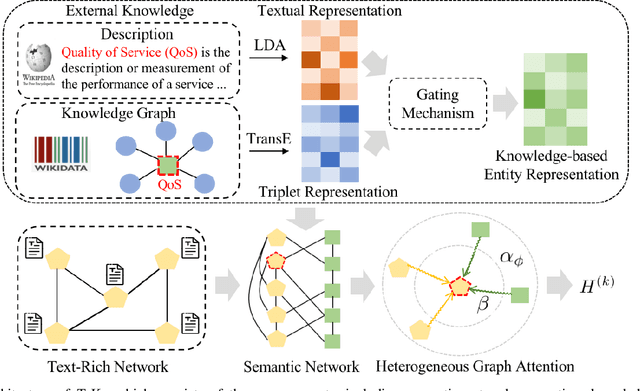

Graph Neural Networks (GNNs) have gained great popularity in tackling various analytical tasks on graph-structured data (i.e., networks). Typical GNNs and their variants follow a message-passing manner that obtains network representations by the feature propagation process along network topology, which however ignore the rich textual semantics (e.g., local word-sequence) that exist in many real-world networks. Existing methods for text-rich networks integrate textual semantics by mainly utilizing internal information such as topics or phrases/words, which often suffer from an inability to comprehensively mine the text semantics, limiting the reciprocal guidance between network structure and text semantics. To address these problems, we propose a novel text-rich graph neural network with external knowledge (TeKo), in order to take full advantage of both structural and textual information within text-rich networks. Specifically, we first present a flexible heterogeneous semantic network that incorporates high-quality entities and interactions among documents and entities. We then introduce two types of external knowledge, that is, structured triplets and unstructured entity description, to gain a deeper insight into textual semantics. We further design a reciprocal convolutional mechanism for the constructed heterogeneous semantic network, enabling network structure and textual semantics to collaboratively enhance each other and learn high-level network representations. Extensive experimental results on four public text-rich networks as well as a large-scale e-commerce searching dataset illustrate the superior performance of TeKo over state-of-the-art baselines.
Unsupervised Key Event Detection from Massive Text Corpora
Jun 08, 2022
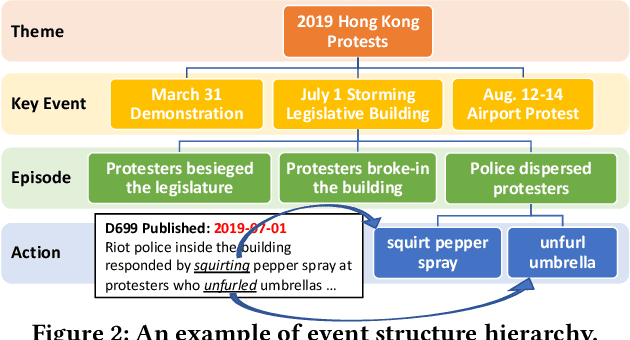
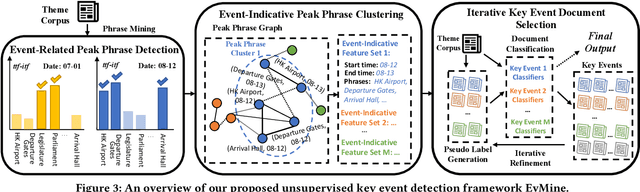
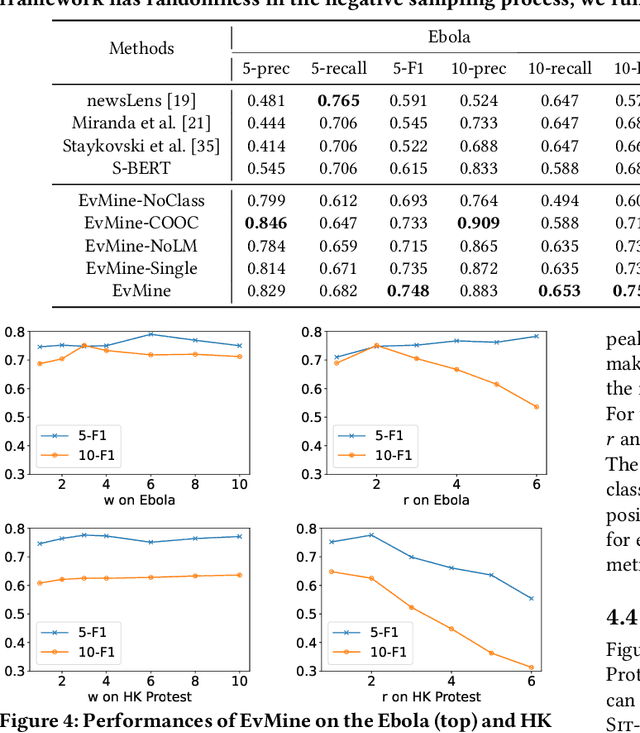
Automated event detection from news corpora is a crucial task towards mining fast-evolving structured knowledge. As real-world events have different granularities, from the top-level themes to key events and then to event mentions corresponding to concrete actions, there are generally two lines of research: (1) theme detection identifies from a news corpus major themes (e.g., "2019 Hong Kong Protests" vs. "2020 U.S. Presidential Election") that have very distinct semantics; and (2) action extraction extracts from one document mention-level actions (e.g., "the police hit the left arm of the protester") that are too fine-grained for comprehending the event. In this paper, we propose a new task, key event detection at the intermediate level, aiming to detect from a news corpus key events (e.g., "HK Airport Protest on Aug. 12-14"), each happening at a particular time/location and focusing on the same topic. This task can bridge event understanding and structuring and is inherently challenging because of the thematic and temporal closeness of key events and the scarcity of labeled data due to the fast-evolving nature of news articles. To address these challenges, we develop an unsupervised key event detection framework, EvMine, that (1) extracts temporally frequent peak phrases using a novel ttf-itf score, (2) merges peak phrases into event-indicative feature sets by detecting communities from our designed peak phrase graph that captures document co-occurrences, semantic similarities, and temporal closeness signals, and (3) iteratively retrieves documents related to each key event by training a classifier with automatically generated pseudo labels from the event-indicative feature sets and refining the detected key events using the retrieved documents. Extensive experiments and case studies show EvMine outperforms all the baseline methods and its ablations on two real-world news corpora.
Schema-Guided Event Graph Completion
Jun 06, 2022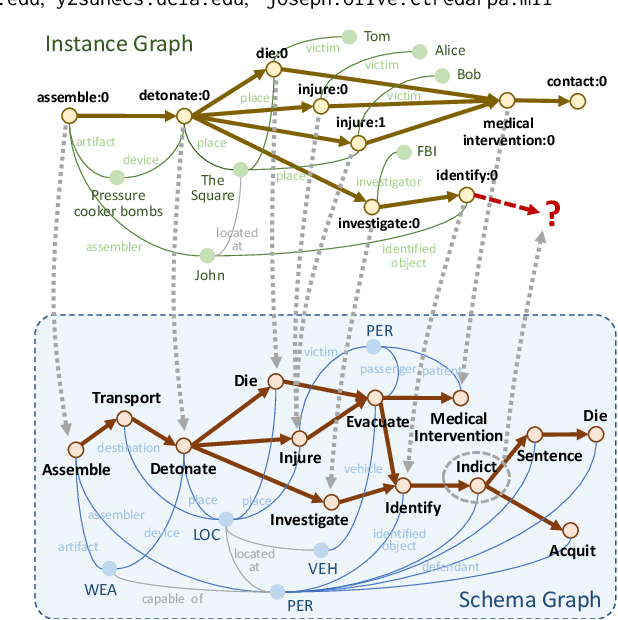

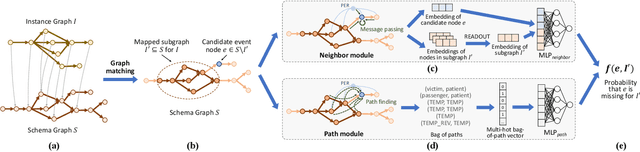
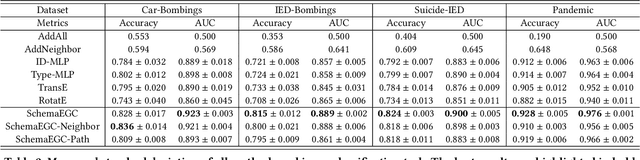
We tackle a new task, event graph completion, which aims to predict missing event nodes for event graphs. Existing link prediction or graph completion methods have difficulty dealing with event graphs because they are usually designed for a single large graph such as a social network or a knowledge graph, rather than multiple small dynamic event graphs. Moreover, they can only predict missing edges rather than missing nodes. In this work, we propose to utilize event schema, a template that describes the stereotypical structure of event graphs, to address the above issues. Our schema-guided event graph completion approach first maps an instance event graph to a subgraph of the schema graph by a heuristic subgraph matching algorithm. Then it predicts whether a candidate event node in the schema graph should be added to the instantiated schema subgraph by characterizing two types of local topology of the schema graph: neighbors of the candidate node and the subgraph, and paths that connect the candidate node and the subgraph. These two modules are later combined together for the final prediction. We also propose a self-supervised strategy to construct training samples, as well as an inference algorithm that is specifically designed to complete event graphs. Extensive experimental results on four datasets demonstrate that our proposed method achieves state-of-the-art performance, with 4.3% to 19.4% absolute F1 gains over the best baseline method on the four datasets.
All Birds with One Stone: Multi-task Text Classification for Efficient Inference with One Forward Pass
May 22, 2022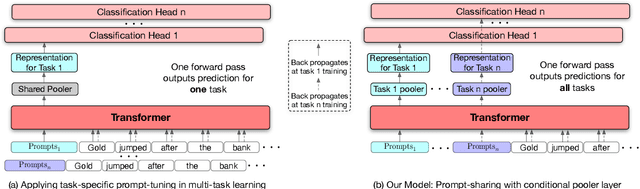
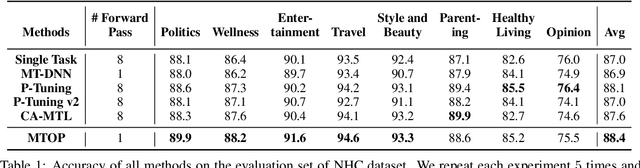
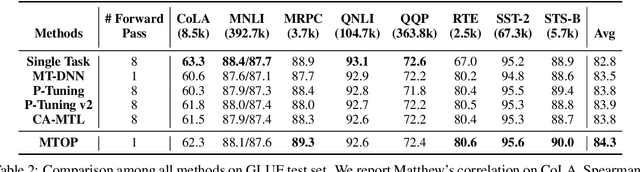
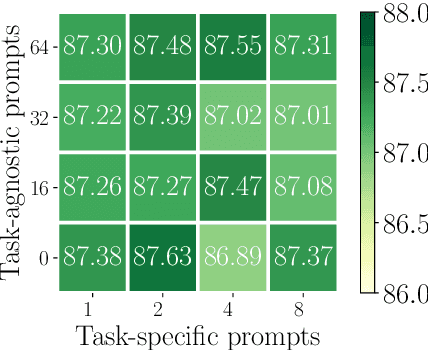
Multi-Task Learning (MTL) models have shown their robustness, effectiveness, and efficiency for transferring learned knowledge across tasks. In real industrial applications such as web content classification, multiple classification tasks are predicted from the same input text such as a web article. However, at the serving time, the existing multitask transformer models such as prompt or adaptor based approaches need to conduct N forward passes for N tasks with O(N) computation cost. To tackle this problem, we propose a scalable method that can achieve stronger performance with close to O(1) computation cost via only one forward pass. To illustrate real application usage, we release a multitask dataset on news topic and style classification. Our experiments show that our proposed method outperforms strong baselines on both the GLUE benchmark and our news dataset. Our code and dataset are publicly available at https://bit.ly/mtop-code.
Heterformer: A Transformer Architecture for Node Representation Learning on Heterogeneous Text-Rich Networks
May 20, 2022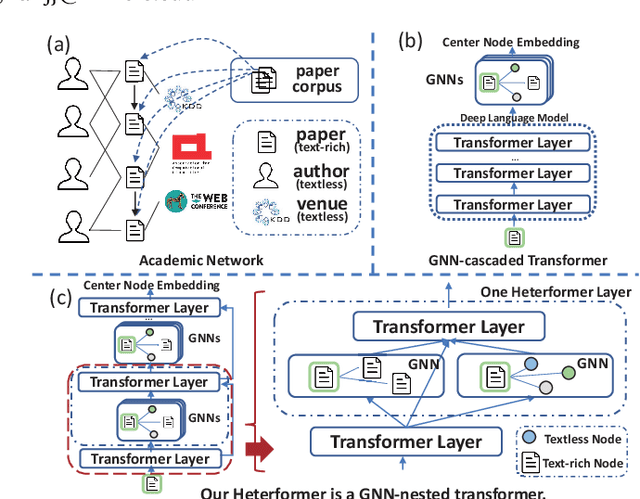
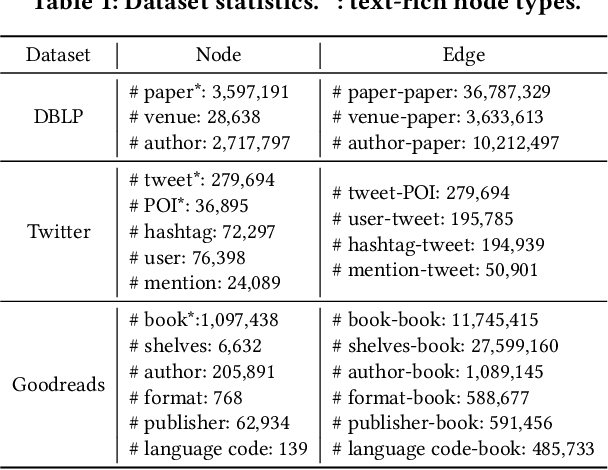

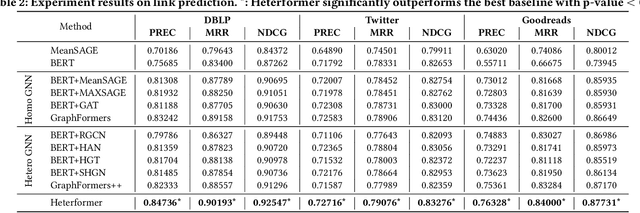
We study node representation learning on heterogeneous text-rich networks, where nodes and edges are multi-typed and some types of nodes are associated with text information. Although recent studies on graph neural networks (GNNs) and pretrained language models (PLMs) have demonstrated their power in encoding network and text signals, respectively, less focus has been given to delicately coupling these two types of models on heterogeneous text-rich networks. Specifically, existing GNNs rarely model text in each node in a contextualized way; existing PLMs can hardly be applied to characterize graph structures due to their sequence architecture. In this paper, we propose Heterformer, a Heterogeneous GNN-nested transformer that blends GNNs and PLMs into a unified model. Different from previous "cascaded architectures" that directly add GNN layers upon a PLM, our Heterformer alternately stacks two modules - a graph-attention-based neighbor aggregation module and a transformer-based text and neighbor joint encoding module - to facilitate thorough mutual enhancement between network and text signals. Meanwhile, Heterformer is capable of characterizing network heterogeneity and nodes without text information. Comprehensive experiments on three large-scale datasets from different domains demonstrate the superiority of Heterformer over state-of-the-art baselines in link prediction, transductive/inductive node classification, node clustering, and semantics-based retrieval.
CiteSum: Citation Text-guided Scientific Extreme Summarization and Low-resource Domain Adaptation
May 12, 2022

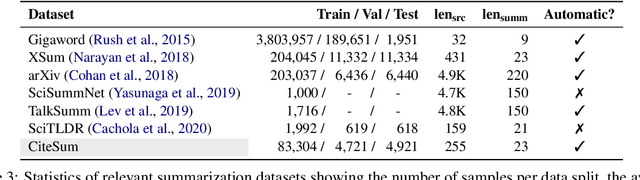
Scientific extreme summarization (TLDR) aims to form ultra-short summaries of scientific papers. Previous efforts on curating scientific TLDR datasets failed to scale up due to the heavy human annotation and domain expertise required. In this paper, we propose a simple yet effective approach to automatically extracting TLDR summaries for scientific papers from their citation texts. Based on the proposed approach, we create a new benchmark CiteSum without human annotation, which is around 30 times larger than the previous human-curated dataset SciTLDR. We conduct a comprehensive analysis of CiteSum, examining its data characteristics and establishing strong baselines. We further demonstrate the usefulness of CiteSum by adapting models pre-trained on CiteSum (named CITES) to new tasks and domains with limited supervision. For scientific extreme summarization, CITES outperforms most fully-supervised methods on SciTLDR without any fine-tuning and obtains state-of-the-art results with only 128 examples. For news extreme summarization, CITES achieves significant gains on XSum over its base model (not pre-trained on CiteSum), e.g., +7.2 ROUGE-1 zero-shot performance and state-of-the-art few-shot performance. For news headline generation, CITES performs the best among unsupervised and zero-shot methods on Gigaword.