 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Dec 13, 2020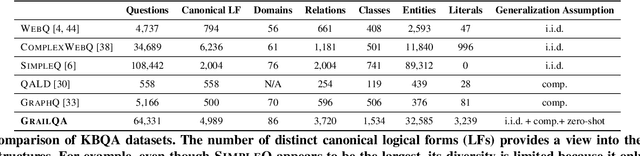
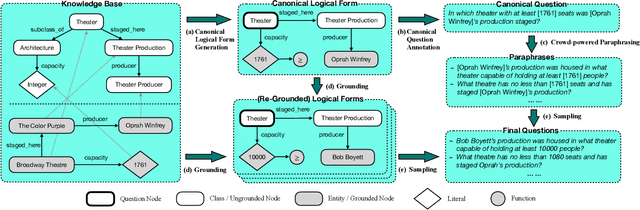

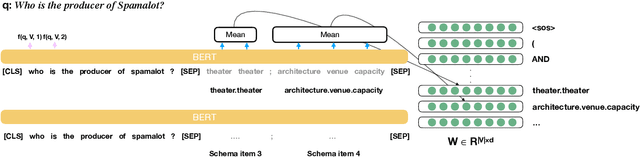
Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.
SynSetExpan: An Iterative Framework for Joint Entity Set Expansion and Synonym Discovery
Sep 29, 2020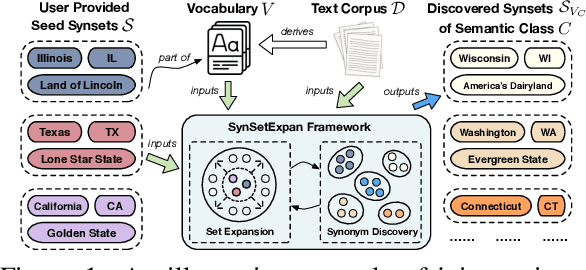
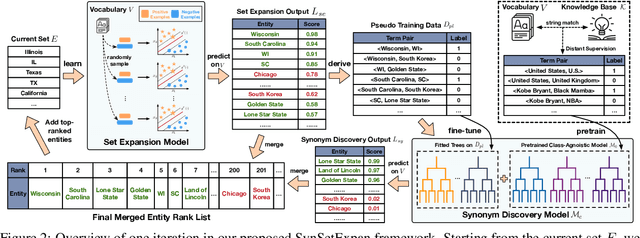
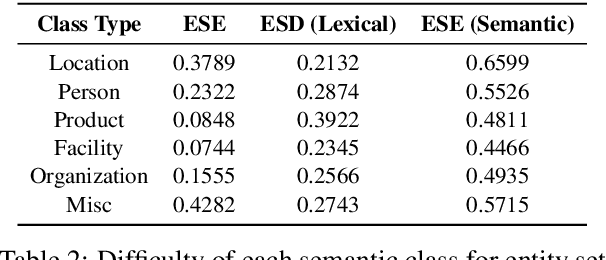
Entity set expansion and synonym discovery are two critical NLP tasks. Previous studies accomplish them separately, without exploring their interdependencies. In this work, we hypothesize that these two tasks are tightly coupled because two synonymous entities tend to have similar likelihoods of belonging to various semantic classes. This motivates us to design SynSetExpan, a novel framework that enables two tasks to mutually enhance each other. SynSetExpan uses a synonym discovery model to include popular entities' infrequent synonyms into the set, which boosts the set expansion recall. Meanwhile, the set expansion model, being able to determine whether an entity belongs to a semantic class, can generate pseudo training data to fine-tune the synonym discovery model towards better accuracy. To facilitate the research on studying the interplays of these two tasks, we create the first large-scale Synonym-Enhanced Set Expansion (SE2) dataset via crowdsourcing. Extensive experiments on the SE2 dataset and previous benchmarks demonstrate the effectiveness of SynSetExpan for both entity set expansion and synonym discovery tasks.
Mining Entity Synonyms with Efficient Neural Set Generation
Nov 16, 2018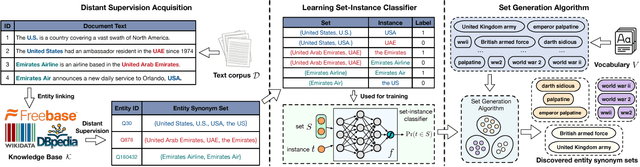
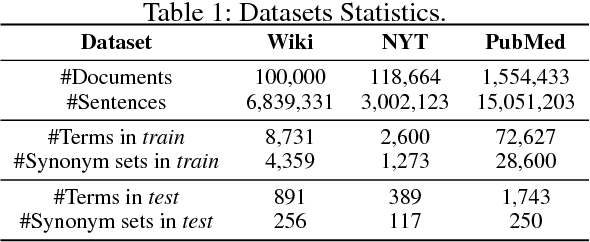
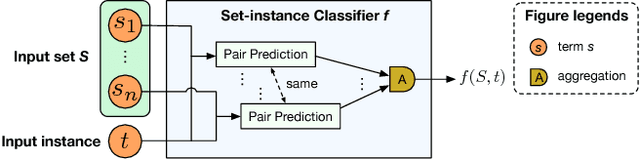

Mining entity synonym sets (i.e., sets of terms referring to the same entity) is an important task for many entity-leveraging applications. Previous work either rank terms based on their similarity to a given query term, or treats the problem as a two-phase task (i.e., detecting synonymy pairs, followed by organizing these pairs into synonym sets). However, these approaches fail to model the holistic semantics of a set and suffer from the error propagation issue. Here we propose a new framework, named SynSetMine, that efficiently generates entity synonym sets from a given vocabulary, using example sets from external knowledge bases as distant supervision. SynSetMine consists of two novel modules: (1) a set-instance classifier that jointly learns how to represent a permutation invariant synonym set and whether to include a new instance (i.e., a term) into the set, and (2) a set generation algorithm that enumerates the vocabulary only once and applies the learned set-instance classifier to detect all entity synonym sets in it. Experiments on three real datasets from different domains demonstrate both effectiveness and efficiency of SynSetMine for mining entity synonym sets.