 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Apr 13, 2026Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
TIPS: Text-Image Pretraining with Spatial Awareness
Oct 21, 2024



While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
May 28, 2024



Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
Mitigating Dialogue Hallucination for Large Multi-modal Models via Adversarial Instruction Tuning
Mar 15, 2024



Mitigating hallucinations of Large Multi-modal Models(LMMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LMMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues generated by our novel Adversarial Question Generator, which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LMMs. On our benchmark, the zero-shot performance of state-of-the-art LMMs dropped significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning that robustly fine-tunes LMMs on augmented multi-modal instruction-following datasets with hallucinatory dialogues. Extensive experiments show that our proposed approach successfully reduces dialogue hallucination while maintaining or even improving performance.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023



The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023



Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection
Mar 16, 2023



Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Explicit Image Caption Editing
Jul 20, 2022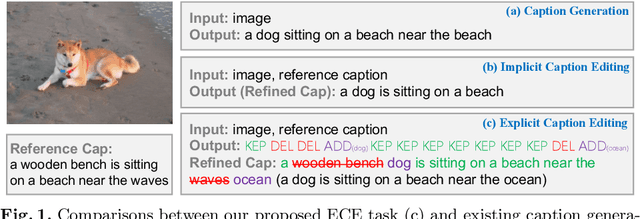
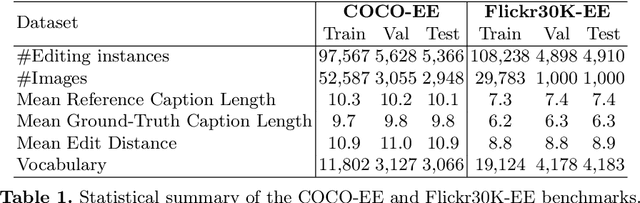

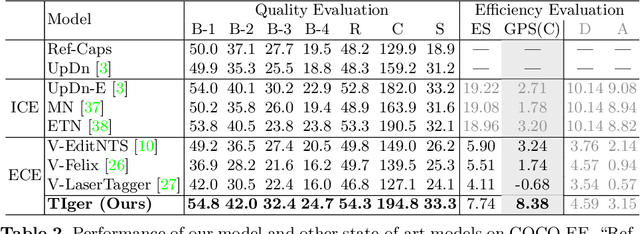
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption. However, all existing caption editing works are implicit models, ie, they directly produce the refined captions without explicit connections to the reference captions. In this paper, we introduce a new task: Explicit Caption Editing (ECE). ECE models explicitly generate a sequence of edit operations, and this edit operation sequence can translate the reference caption into a refined one. Compared to the implicit editing, ECE has multiple advantages: 1) Explainable: it can trace the whole editing path. 2) Editing Efficient: it only needs to modify a few words. 3) Human-like: it resembles the way that humans perform caption editing, and tries to keep original sentence structures. To solve this new task, we propose the first ECE model: TIger. TIger is a non-autoregressive transformer-based model, consisting of three modules: Tagger_del, Tagger_add, and Inserter. Specifically, Tagger_del decides whether each word should be preserved or not, Tagger_add decides where to add new words, and Inserter predicts the specific word for adding. To further facilitate ECE research, we propose two new ECE benchmarks by re-organizing two existing datasets, dubbed COCO-EE and Flickr30K-EE, respectively. Extensive ablations on both two benchmarks have demonstrated the effectiveness of TIger.
Multimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting
Apr 16, 2022
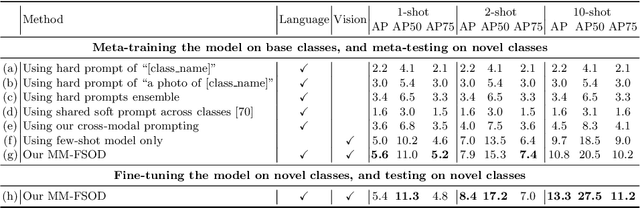
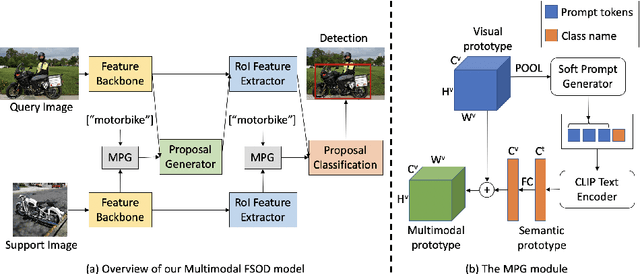
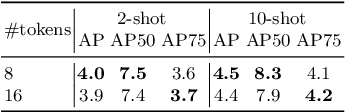
We study multimodal few-shot object detection (FSOD) in this paper, using both few-shot visual examples and class semantic information for detection. Most of previous works focus on either few-shot or zero-shot object detection, ignoring the complementarity of visual and semantic information. We first show that meta-learning and prompt-based learning, the most commonly-used methods for few-shot learning and zero-shot transferring from pre-trained vision-language models to downstream tasks, are conceptually similar. They both reformulate the objective of downstream tasks the same as the pre-training tasks, and mostly without tuning the parameters of pre-trained models. Based on this observation, we propose to combine meta-learning with prompt-based learning for multimodal FSOD without fine-tuning, by learning transferable class-agnostic multimodal FSOD models over many-shot base classes. Specifically, to better exploit the pre-trained vision-language models, the meta-learning based cross-modal prompting is proposed to generate soft prompts and further used to extract the semantic prototype, conditioned on the few-shot visual examples. Then, the extracted semantic prototype and few-shot visual prototype are fused to generate the multimodal prototype for detection. Our models can efficiently fuse the visual and semantic information at both token-level and feature-level. We comprehensively evaluate the proposed multimodal FSOD models on multiple few-shot object detection benchmarks, achieving promising results.