 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-imperceptible Neural Linguistic Steganography via Self-Adjusting Arithmetic Coding
Paper and Code
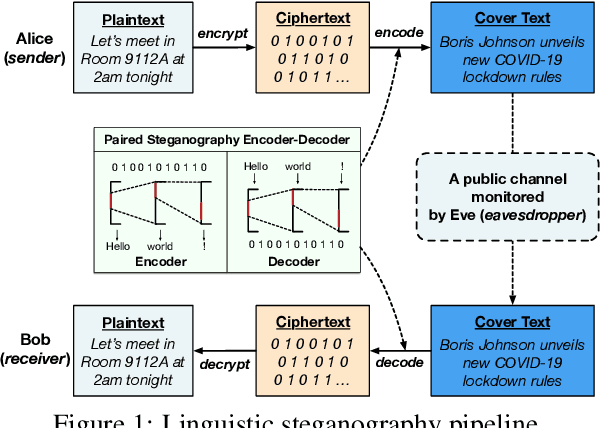
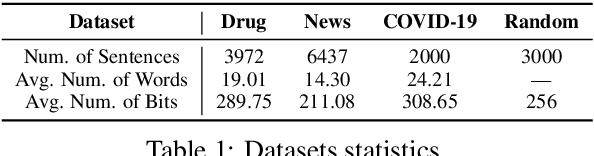
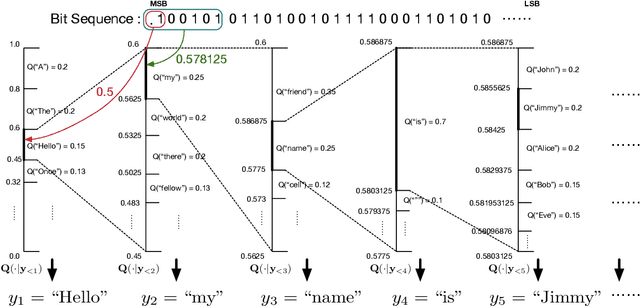
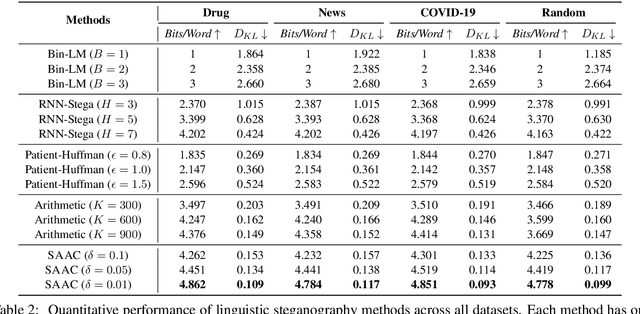
Linguistic steganography studies how to hide secret messages in natural language cover texts. Traditional methods aim to transform a secret message into an innocent text via lexical substitution or syntactical modification. Recently, advances in neural language models (LMs) enable us to directly generate cover text conditioned on the secret message. In this study, we present a new linguistic steganography method which encodes secret messages using self-adjusting arithmetic coding based on a neural language model. We formally analyze the statistical imperceptibility of this method and empirically show it outperforms the previous state-of-the-art methods on four datasets by 15.3% and 38.9% in terms of bits/word and KL metrics, respectively. Finally, human evaluations show that 51% of generated cover texts can indeed fool eavesdroppers.