 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025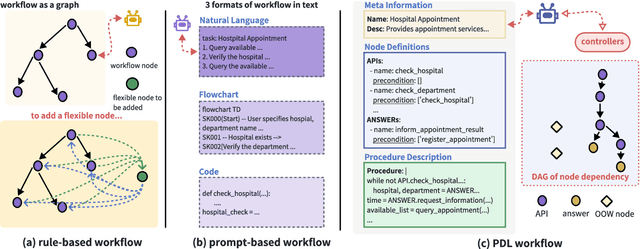

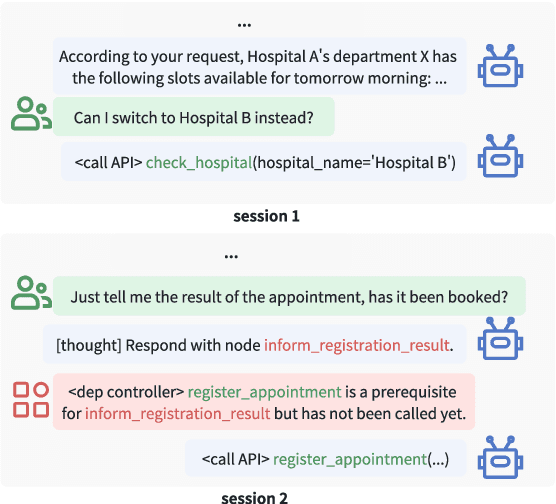
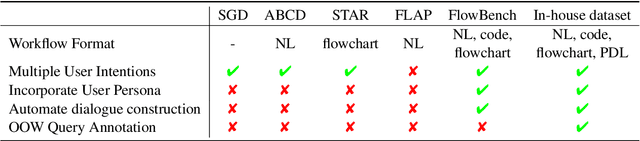
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
Uncertainty-Aware Graph Structure Learning
Feb 19, 2025



Graph Neural Networks (GNNs) have become a prominent approach for learning from graph-structured data. However, their effectiveness can be significantly compromised when the graph structure is suboptimal. To address this issue, Graph Structure Learning (GSL) has emerged as a promising technique that refines node connections adaptively. Nevertheless, we identify two key limitations in existing GSL methods: 1) Most methods primarily focus on node similarity to construct relationships, while overlooking the quality of node information. Blindly connecting low-quality nodes and aggregating their ambiguous information can degrade the performance of other nodes. 2) The constructed graph structures are often constrained to be symmetric, which may limit the model's flexibility and effectiveness. To overcome these limitations, we propose an Uncertainty-aware Graph Structure Learning (UnGSL) strategy. UnGSL estimates the uncertainty of node information and utilizes it to adjust the strength of directional connections, where the influence of nodes with high uncertainty is adaptively reduced. Importantly, UnGSL serves as a plug-in module that can be seamlessly integrated into existing GSL methods with minimal additional computational cost. In our experiments, we implement UnGSL into six representative GSL methods, demonstrating consistent performance improvements.
Learning Counterfactual Outcomes Under Rank Preservation
Feb 10, 2025Counterfactual inference aims to estimate the counterfactual outcome at the individual level given knowledge of an observed treatment and the factual outcome, with broad applications in fields such as epidemiology, econometrics, and management science. Previous methods rely on a known structural causal model (SCM) or assume the homogeneity of the exogenous variable and strict monotonicity between the outcome and exogenous variable. In this paper, we propose a principled approach for identifying and estimating the counterfactual outcome. We first introduce a simple and intuitive rank preservation assumption to identify the counterfactual outcome without relying on a known structural causal model. Building on this, we propose a novel ideal loss for theoretically unbiased learning of the counterfactual outcome and further develop a kernel-based estimator for its empirical estimation. Our theoretical analysis shows that the rank preservation assumption is not stronger than the homogeneity and strict monotonicity assumptions, and shows that the proposed ideal loss is convex, and the proposed estimator is unbiased. Extensive semi-synthetic and real-world experiments are conducted to demonstrate the effectiveness of the proposed method.
DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Feb 06, 2025



Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer
Jan 13, 2025Securing long-term success is the ultimate aim of recommender systems, demanding strategies capable of foreseeing and shaping the impact of decisions on future user satisfaction. Current recommendation strategies grapple with two significant hurdles. Firstly, the future impacts of recommendation decisions remain obscured, rendering it impractical to evaluate them through direct optimization of immediate metrics. Secondly, conflicts often emerge between multiple objectives, like enhancing accuracy versus exploring diverse recommendations. Existing strategies, trapped in a "training, evaluation, and retraining" loop, grow more labor-intensive as objectives evolve. To address these challenges, we introduce a future-conditioned strategy for multi-objective controllable recommendations, allowing for the direct specification of future objectives and empowering the model to generate item sequences that align with these goals autoregressively. We present the Multi-Objective Controllable Decision Transformer (MocDT), an offline Reinforcement Learning (RL) model capable of autonomously learning the mapping from multiple objectives to item sequences, leveraging extensive offline data. Consequently, it can produce recommendations tailored to any specified objectives during the inference stage. Our empirical findings emphasize the controllable recommendation strategy's ability to produce item sequences according to different objectives while maintaining performance that is competitive with current recommendation strategies across various objectives.
Position-aware Graph Transformer for Recommendation
Dec 25, 2024Collaborative recommendation fundamentally involves learning high-quality user and item representations from interaction data. Recently, graph convolution networks (GCNs) have advanced the field by utilizing high-order connectivity patterns in interaction graphs, as evidenced by state-of-the-art methods like PinSage and LightGCN. However, one key limitation has not been well addressed in existing solutions: capturing long-range collaborative filtering signals, which are crucial for modeling user preference. In this work, we propose a new graph transformer (GT) framework -- \textit{Position-aware Graph Transformer for Recommendation} (PGTR), which combines the global modeling capability of Transformer blocks with the local neighborhood feature extraction of GCNs. The key insight is to explicitly incorporate node position and structure information from the user-item interaction graph into GT architecture via several purpose-designed positional encodings. The long-range collaborative signals from the Transformer block are then combined linearly with the local neighborhood features from the GCN backbone to enhance node embeddings for final recommendations. Empirical studies demonstrate the effectiveness of the proposed PGTR method when implemented on various GCN-based backbones across four real-world datasets, and the robustness against interaction sparsity as well as noise.
Universal Inceptive GNNs by Eliminating the Smoothness-generalization Dilemma
Dec 13, 2024



Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains, such as transaction and social net-works. However, their application is often hindered by the varyinghomophily levels across different orders of neighboring nodes, ne-cessitating separate model designs for homophilic and heterophilicgraphs. In this paper, we aim to develop a unified framework ca-pable of handling neighborhoods of various orders and homophilylevels. Through theoretical exploration, we identify a previouslyoverlooked architectural aspect in multi-hop learning: the cascadedependency, which leads to asmoothness-generalization dilemma.This dilemma significantly affects the learning process, especiallyin the context of high-order neighborhoods and heterophilic graphs.To resolve this issue, we propose an Inceptive Graph Neural Net-work (IGNN), a universal message-passing framework that replacesthe cascade dependency with an inceptive architecture. IGNN pro-vides independent representations for each hop, allowing personal-ized generalization capabilities, and captures neighborhood-wiserelationships to select appropriate receptive fields. Extensive ex-periments show that our IGNN outperforms 23 baseline methods,demonstrating superior performance on both homophilic and het-erophilic graphs, while also scaling efficiently to large graphs.
The Rise and Down of Babel Tower: Investigating the Evolution Process of Multilingual Code Large Language Model
Dec 10, 2024



Large language models (LLMs) have shown significant multilingual capabilities. However, the mechanisms underlying the development of these capabilities during pre-training are not well understood. In this paper, we use code LLMs as an experimental platform to explore the evolution of multilingual capabilities in LLMs during the pre-training process. Based on our observations, we propose the Babel Tower Hypothesis, which describes the entire process of LLMs acquiring new language capabilities. During the learning process, multiple languages initially share a single knowledge system dominated by the primary language and gradually develop language-specific knowledge systems. We then validate the above hypothesis by tracking the internal states of the LLMs through identifying working languages and language transferring neurons. Experimental results show that the internal state changes of the LLM are consistent with our Babel Tower Hypothesis. Building on these insights, we propose a novel method to construct an optimized pre-training corpus for multilingual code LLMs, which significantly outperforms LLMs trained on the original corpus. The proposed Babel Tower Hypothesis provides new insights into designing pre-training data distributions to achieve optimal multilingual capabilities in LLMs.
Graph Disentangle Causal Model: Enhancing Causal Inference in Networked Observational Data
Dec 05, 2024



Estimating individual treatment effects (ITE) from observational data is a critical task across various domains. However, many existing works on ITE estimation overlook the influence of hidden confounders, which remain unobserved at the individual unit level. To address this limitation, researchers have utilized graph neural networks to aggregate neighbors' features to capture the hidden confounders and mitigate confounding bias by minimizing the discrepancy of confounder representations between the treated and control groups. Despite the success of these approaches, practical scenarios often treat all features as confounders and involve substantial differences in feature distributions between the treated and control groups. Confusing the adjustment and confounder and enforcing strict balance on the confounder representations could potentially undermine the effectiveness of outcome prediction. To mitigate this issue, we propose a novel framework called the \textit{Graph Disentangle Causal model} (GDC) to conduct ITE estimation in the network setting. GDC utilizes a causal disentangle module to separate unit features into adjustment and confounder representations. Then we design a graph aggregation module consisting of three distinct graph aggregators to obtain adjustment, confounder, and counterfactual confounder representations. Finally, a causal constraint module is employed to enforce the disentangled representations as true causal factors. The effectiveness of our proposed method is demonstrated by conducting comprehensive experiments on two networked datasets.
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.