 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025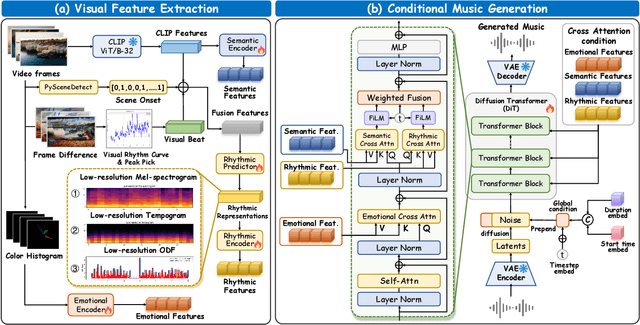
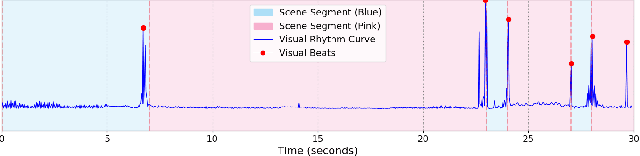
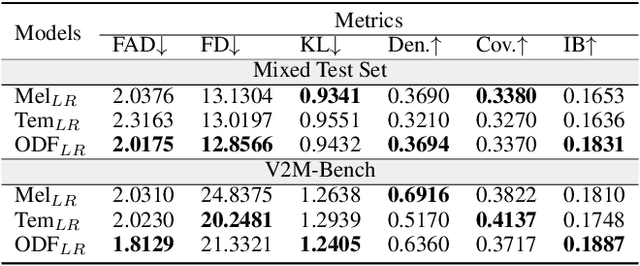
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
Losing is for Cherishing: Data Valuation Based on Machine Unlearning and Shapley Value
May 22, 2025The proliferation of large models has intensified the need for efficient data valuation methods to quantify the contribution of individual data providers. Traditional approaches, such as game-theory-based Shapley value and influence-function-based techniques, face prohibitive computational costs or require access to full data and model training details, making them hardly achieve partial data valuation. To address this, we propose Unlearning Shapley, a novel framework that leverages machine unlearning to estimate data values efficiently. By unlearning target data from a pretrained model and measuring performance shifts on a reachable test set, our method computes Shapley values via Monte Carlo sampling, avoiding retraining and eliminating dependence on full data. Crucially, Unlearning Shapley supports both full and partial data valuation, making it scalable for large models (e.g., LLMs) and practical for data markets. Experiments on benchmark datasets and large-scale text corpora demonstrate that our approach matches the accuracy of state-of-the-art methods while reducing computational overhead by orders of magnitude. Further analysis confirms a strong correlation between estimated values and the true impact of data subsets, validating its reliability in real-world scenarios. This work bridges the gap between data valuation theory and practical deployment, offering a scalable, privacy-compliant solution for modern AI ecosystems.
A Survey on Music Generation from Single-Modal, Cross-Modal, and Multi-Modal Perspectives: Data, Methods, and Challenges
Apr 01, 2025Multi-modal music generation, using multiple modalities like images, video, and text alongside musical scores and audio as guidance, is an emerging research area with broad applications. This paper reviews this field, categorizing music generation systems from the perspective of modalities. It covers modality representation, multi-modal data alignment, and their utilization to guide music generation. We also discuss current datasets and evaluation methods. Key challenges in this area include effective multi-modal integration, large-scale comprehensive datasets, and systematic evaluation methods. Finally, we provide an outlook on future research directions focusing on multi-modal fusion, alignment, data, and evaluation.
A Comprehensive Survey on Generative AI for Video-to-Music Generation
Feb 18, 2025The burgeoning growth of video-to-music generation can be attributed to the ascendancy of multimodal generative models. However, there is a lack of literature that comprehensively combs through the work in this field. To fill this gap, this paper presents a comprehensive review of video-to-music generation using deep generative AI techniques, focusing on three key components: visual feature extraction, music generation frameworks, and conditioning mechanisms. We categorize existing approaches based on their designs for each component, clarifying the roles of different strategies. Preceding this, we provide a fine-grained classification of video and music modalities, illustrating how different categories influence the design of components within the generation pipelines. Furthermore, we summarize available multimodal datasets and evaluation metrics while highlighting ongoing challenges in the field.
SongGLM: Lyric-to-Melody Generation with 2D Alignment Encoding and Multi-Task Pre-Training
Dec 24, 2024



Lyric-to-melody generation aims to automatically create melodies based on given lyrics, requiring the capture of complex and subtle correlations between them. However, previous works usually suffer from two main challenges: 1) lyric-melody alignment modeling, which is often simplified to one-syllable/word-to-one-note alignment, while others have the problem of low alignment accuracy; 2) lyric-melody harmony modeling, which usually relies heavily on intermediates or strict rules, limiting model's capabilities and generative diversity. In this paper, we propose SongGLM, a lyric-to-melody generation system that leverages 2D alignment encoding and multi-task pre-training based on the General Language Model (GLM) to guarantee the alignment and harmony between lyrics and melodies. Specifically, 1) we introduce a unified symbolic song representation for lyrics and melodies with word-level and phrase-level (2D) alignment encoding to capture the lyric-melody alignment; 2) we design a multi-task pre-training framework with hierarchical blank infilling objectives (n-gram, phrase, and long span), and incorporate lyric-melody relationships into the extraction of harmonized n-grams to ensure the lyric-melody harmony. We also construct a large-scale lyric-melody paired dataset comprising over 200,000 English song pieces for pre-training and fine-tuning. The objective and subjective results indicate that SongGLM can generate melodies from lyrics with significant improvements in both alignment and harmony, outperforming all the previous baseline methods.
MetaBGM: Dynamic Soundtrack Transformation For Continuous Multi-Scene Experiences With Ambient Awareness And Personalization
Sep 05, 2024



This paper introduces MetaBGM, a groundbreaking framework for generating background music that adapts to dynamic scenes and real-time user interactions. We define multi-scene as variations in environmental contexts, such as transitions in game settings or movie scenes. To tackle the challenge of converting backend data into music description texts for audio generation models, MetaBGM employs a novel two-stage generation approach that transforms continuous scene and user state data into these texts, which are then fed into an audio generation model for real-time soundtrack creation. Experimental results demonstrate that MetaBGM effectively generates contextually relevant and dynamic background music for interactive applications.
SaMoye: Zero-shot Singing Voice Conversion Based on Feature Disentanglement and Synthesis
Jul 11, 2024



Singing voice conversion (SVC) aims to convert a singer's voice in a given music piece to another singer while keeping the original content. We propose an end-to-end feature disentanglement-based model, which we named SaMoye, to enable zero-shot many-to-many singing voice conversion. SaMoye disentangles the features of the singing voice into content features, timbre features, and pitch features respectively. The content features are enhanced using a GPT-based model to perform cross-prediction with the phoneme of the lyrics. SaMoye can generate the music with converted voice by replacing the timbre features with the target singer. We also establish an unparalleled large-scale dataset to guarantee zero-shot performance. The dataset consists of 1500k pure singing vocal clips containing at least 10,000 singers.
MuDiT & MuSiT: Alignment with Colloquial Expression in Description-to-Song Generation
Jul 03, 2024



Amid the rising intersection of generative AI and human artistic processes, this study probes the critical yet less-explored terrain of alignment in human-centric automatic song composition. We propose a novel task of Colloquial Description-to-Song Generation, which focuses on aligning the generated content with colloquial human expressions. This task is aimed at bridging the gap between colloquial language understanding and auditory expression within an AI model, with the ultimate goal of creating songs that accurately satisfy human auditory expectations and structurally align with musical norms. Current datasets are limited due to their narrow descriptive scope, semantic gaps and inaccuracies. To overcome data scarcity in this domain, we present the Caichong Music Dataset (CaiMD). CaiMD is manually annotated by both professional musicians and amateurs, offering diverse perspectives and a comprehensive understanding of colloquial descriptions. Unlike existing datasets pre-set with expert annotations or auto-generated ones with inherent biases, CaiMD caters more sufficiently to our purpose of aligning AI-generated music with widespread user-desired results. Moreover, we propose an innovative single-stage framework called MuDiT/MuSiT for enabling effective human-machine alignment in song creation. This framework not only achieves cross-modal comprehension between colloquial language and auditory music perceptions but also ensures generated songs align with user-desired results. MuDiT/MuSiT employs one DiT/SiT model for end-to-end generation of musical components like melody, harmony, rhythm, vocals, and instrumentation. The approach ensures harmonious sonic cohesiveness amongst all generated musical components, facilitating better resonance with human auditory expectations.
MuChin: A Chinese Colloquial Description Benchmark for Evaluating Language Models in the Field of Music
Feb 15, 2024



The rapidly evolving multimodal Large Language Models (LLMs) urgently require new benchmarks to uniformly evaluate their performance on understanding and textually describing music. However, due to semantic gaps between Music Information Retrieval (MIR) algorithms and human understanding, discrepancies between professionals and the public, and low precision of annotations, existing music description datasets cannot serve as benchmarks. To this end, we present MuChin, the first open-source music description benchmark in Chinese colloquial language, designed to evaluate the performance of multimodal LLMs in understanding and describing music. We established the Caichong Music Annotation Platform (CaiMAP) that employs an innovative multi-person, multi-stage assurance method, and recruited both amateurs and professionals to ensure the precision of annotations and alignment with popular semantics. Utilizing this method, we built a dataset with multi-dimensional, high-precision music annotations, the Caichong Music Dataset (CaiMD), and carefully selected 1,000 high-quality entries to serve as the test set for MuChin. Based on MuChin, we analyzed the discrepancies between professionals and amateurs in terms of music description, and empirically demonstrated the effectiveness of annotated data for fine-tuning LLMs. Ultimately, we employed MuChin to evaluate existing music understanding models on their ability to provide colloquial descriptions of music. All data related to the benchmark and the code for scoring have been open-sourced.
Online Differentiable Clustering for Intent Learning in Recommendation
Jan 24, 2024



Mining users' intents plays a crucial role in sequential recommendation. The recent approach, ICLRec, was introduced to extract underlying users' intents using contrastive learning and clustering. While it has shown effectiveness, the existing method suffers from complex and cumbersome alternating optimization, leading to two main issues. Firstly, the separation of representation learning and clustering optimization within a generalized expectation maximization (EM) framework often results in sub-optimal performance. Secondly, performing clustering on the entire dataset hampers scalability for large-scale industry data. To address these challenges, we propose a novel intent learning method called \underline{ODCRec}, which integrates representation learning into an \underline{O}nline \underline{D}ifferentiable \underline{C}lustering framework for \underline{Rec}ommendation. Specifically, we encode users' behavior sequences and initialize the cluster centers as differentiable network parameters. Additionally, we design a clustering loss that guides the networks to differentiate between different cluster centers and pull similar samples towards their respective cluster centers. This allows simultaneous optimization of recommendation and clustering using mini-batch data. Moreover, we leverage the learned cluster centers as self-supervision signals for representation learning, resulting in further enhancement of recommendation performance. Extensive experiments conducted on open benchmarks and industry data validate the superiority, effectiveness, and efficiency of our proposed ODCRec method. Code is available at: https://github.com/yueliu1999/ELCRec.