 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILM: Large Language Models for Multimodal Irregular Time Series with Informative Sampling
May 13, 2026Multimodal irregular time series (MITS) consist of asynchronous and irregularly sampled observations from heterogeneous numerical and textual channels. In healthcare, for example, patients' electronic health records (EHR) include irregular lab measurements and clinical notes. The irregular timing and channel patterns of observations carry predictive signal alongside the numerical values and textual content. LLMs are natural candidates for processing such heterogeneous data, given their extensive pretrained knowledge spanning textual and numerical domains. We introduce MILM (Multimodal Irregular time series Language Model), which represents MITS as time-ordered triplets in Extensible Markup Language (XML) format and fine-tunes an LLM through a two-stage strategy for MITS classification. The first stage trains on value-redacted MITS to predict from sampling patterns alone, and the second stage trains on full MITS to jointly model sampling patterns and observed values. Our two-stage model (MILM-2S) and its single-stage counterpart (MILM-Direct) achieve the best and second-best average performance on multiple EHR datasets. Further value redaction evaluations confirm that sampling patterns carry predictive signal and that MILM-2S learns to exploit them. In the value pending evaluation we introduce, where some values are unavailable at prediction time, MILM-2S outperforms MILM-Direct by a larger margin compared to standard evaluation. For MILM-2S, preserving the time and channel of value-pending observations as additional sampling information further improves in-hospital mortality prediction.
OMAC: A Broad Optimization Framework for LLM-Based Multi-Agent Collaboration
May 17, 2025Agents powered by advanced large language models (LLMs) have demonstrated impressive capabilities across diverse complex applications. Recently, Multi-Agent Systems (MAS), wherein multiple agents collaborate and communicate with each other, have exhibited enhanced capabilities in complex tasks, such as high-quality code generation and arithmetic reasoning. However, the development of such systems often relies on handcrafted methods, and the literature on systematic design and optimization of LLM-based MAS remains limited. In this work, we introduce OMAC, a general framework designed for holistic optimization of LLM-based MAS. Specifically, we identify five key optimization dimensions for MAS, encompassing both agent functionality and collaboration structure. Building upon these dimensions, we first propose a general algorithm, utilizing two actors termed the Semantic Initializer and the Contrastive Comparator, to optimize any single dimension. Then, we present an algorithm for joint optimization across multiple dimensions. Extensive experiments demonstrate the superior performance of OMAC on code generation, arithmetic reasoning, and general reasoning tasks against state-of-the-art approaches.
Goal-Conditioned Supervised Learning for Multi-Objective Recommendation
Dec 12, 2024Multi-objective learning endeavors to concurrently optimize multiple objectives using a single model, aiming to achieve high and balanced performance across these diverse objectives. However, it often involves a more complex optimization problem, particularly when navigating potential conflicts between objectives, leading to solutions with higher memory requirements and computational complexity. This paper introduces a Multi-Objective Goal-Conditioned Supervised Learning (MOGCSL) framework for automatically learning to achieve multiple objectives from offline sequential data. MOGCSL extends the conventional Goal-Conditioned Supervised Learning (GCSL) method to multi-objective scenarios by redefining goals from one-dimensional scalars to multi-dimensional vectors. The need for complex architectures and optimization constraints can be naturally eliminated. MOGCSL benefits from filtering out uninformative or noisy instances that do not achieve desirable long-term rewards. It also incorporates a novel goal-choosing algorithm to model and select "high" achievable goals for inference. While MOGCSL is quite general, we focus on its application to the next action prediction problem in commercial-grade recommender systems. In this context, any viable solution needs to be reasonably scalable and also be robust to large amounts of noisy data that is characteristic of this application space. We show that MOGCSL performs admirably on both counts. Specifically, extensive experiments conducted on real-world recommendation datasets validate its efficacy and efficiency. Also, analysis and experiments are included to explain its strength in discounting the noisier portions of training data in recommender systems.
LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
May 24, 2024



The success of large language models (LLMs) has fostered a new research trend of multi-modality large language models (MLLMs), which changes the paradigm of various fields in computer vision. Though MLLMs have shown promising results in numerous high-level vision and vision-language tasks such as VQA and text-to-image, no works have demonstrated how low-level vision tasks can benefit from MLLMs. We find that most current MLLMs are blind to low-level features due to their design of vision modules, thus are inherently incapable for solving low-level vision tasks. In this work, we purpose $\textbf{LM4LV}$, a framework that enables a FROZEN LLM to solve a range of low-level vision tasks without any multi-modal data or prior. This showcases the LLM's strong potential in low-level vision and bridges the gap between MLLMs and low-level vision tasks. We hope this work can inspire new perspectives on LLMs and deeper understanding of their mechanisms.
DSDRNet: Disentangling Representation and Reconstruct Network for Domain Generalization
Apr 22, 2024



Domain generalization faces challenges due to the distribution shift between training and testing sets, and the presence of unseen target domains. Common solutions include domain alignment, meta-learning, data augmentation, or ensemble learning, all of which rely on domain labels or domain adversarial techniques. In this paper, we propose a Dual-Stream Separation and Reconstruction Network, dubbed DSDRNet. It is a disentanglement-reconstruction approach that integrates features of both inter-instance and intra-instance through dual-stream fusion. The method introduces novel supervised signals by combining inter-instance semantic distance and intra-instance similarity. Incorporating Adaptive Instance Normalization (AdaIN) into a two-stage cyclic reconstruction process enhances self-disentangled reconstruction signals to facilitate model convergence. Extensive experiments on four benchmark datasets demonstrate that DSDRNet outperforms other popular methods in terms of domain generalization capabilities.
Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models
Apr 19, 2024



Adapter-based parameter-efficient transfer learning has achieved exciting results in vision-language models. Traditional adapter methods often require training or fine-tuning, facing challenges such as insufficient samples or resource limitations. While some methods overcome the need for training by leveraging image modality cache and retrieval, they overlook the text modality's importance and cross-modal cues for the efficient adaptation of parameters in visual-language models. This work introduces a cross-modal parameter-efficient approach named XMAdapter. XMAdapter establishes cache models for both text and image modalities. It then leverages retrieval through visual-language bimodal information to gather clues for inference. By dynamically adjusting the affinity ratio, it achieves cross-modal fusion, decoupling different modal similarities to assess their respective contributions. Additionally, it explores hard samples based on differences in cross-modal affinity and enhances model performance through adaptive adjustment of sample learning intensity. Extensive experimental results on benchmark datasets demonstrate that XMAdapter outperforms previous adapter-based methods significantly regarding accuracy, generalization, and efficiency.
Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
Apr 06, 2024



The chain-of-thought technique has been received well in multi-modal tasks. It is a step-by-step linear reasoning process that adjusts the length of the chain to improve the performance of generated prompts. However, human thought processes are predominantly non-linear, as they encompass multiple aspects simultaneously and employ dynamic adjustment and updating mechanisms. Therefore, we propose a novel Aggregation-Graph-of-Thought (AGoT) mechanism for soft-prompt tuning in multi-modal representation learning. The proposed AGoT models the human thought process not only as a chain but also models each step as a reasoning aggregation graph to cope with the overlooked multiple aspects of thinking in single-step reasoning. This turns the entire reasoning process into prompt aggregation and prompt flow operations. Experiments show that our multi-modal model enhanced with AGoT soft-prompting achieves good results in several tasks such as text-image retrieval, visual question answering, and image recognition. In addition, we demonstrate that it has good domain generalization performance due to better reasoning.
Embracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023



Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.
KuaiRand: An Unbiased Sequential Recommendation Dataset with Randomly Exposed Videos
Aug 23, 2022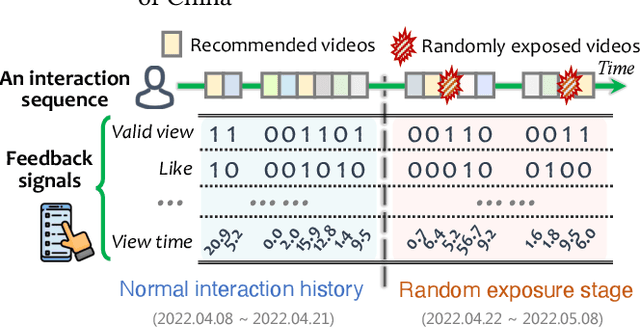
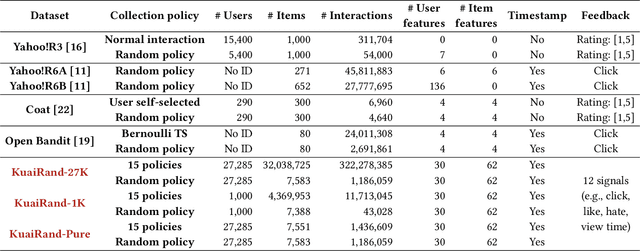
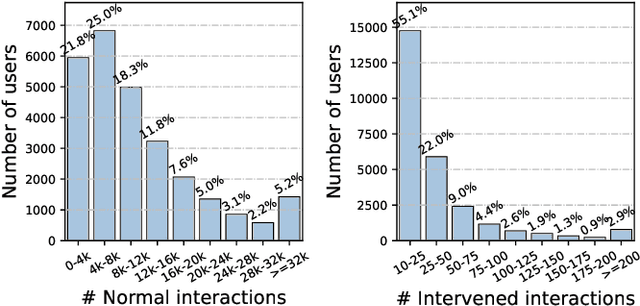
Recommender systems deployed in real-world applications can have inherent exposure bias, which leads to the biased logged data plaguing the researchers. A fundamental way to address this thorny problem is to collect users' interactions on randomly expose items, i.e., the missing-at-random data. A few works have asked certain users to rate or select randomly recommended items, e.g., Yahoo!, Coat, and OpenBandit. However, these datasets are either too small in size or lack key information, such as unique user ID or the features of users/items. In this work, we present KuaiRand, an unbiased sequential recommendation dataset containing millions of intervened interactions on randomly exposed videos, collected from the video-sharing mobile App, Kuaishou. Different from existing datasets, KuaiRand records 12 kinds of user feedback signals (e.g., click, like, and view time) on randomly exposed videos inserted in the recommendation feeds in two weeks. To facilitate model learning, we further collect rich features of users and items as well as users' behavior history. By releasing this dataset, we enable the research of advanced debiasing large-scale recommendation scenarios for the first time. Also, with its distinctive features, KuaiRand can support various other research directions such as interactive recommendation, long sequential behavior modeling, and multi-task learning. The dataset and its news will be available at https://kuairand.com.
CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System
Apr 04, 2022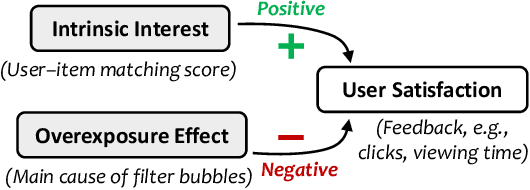

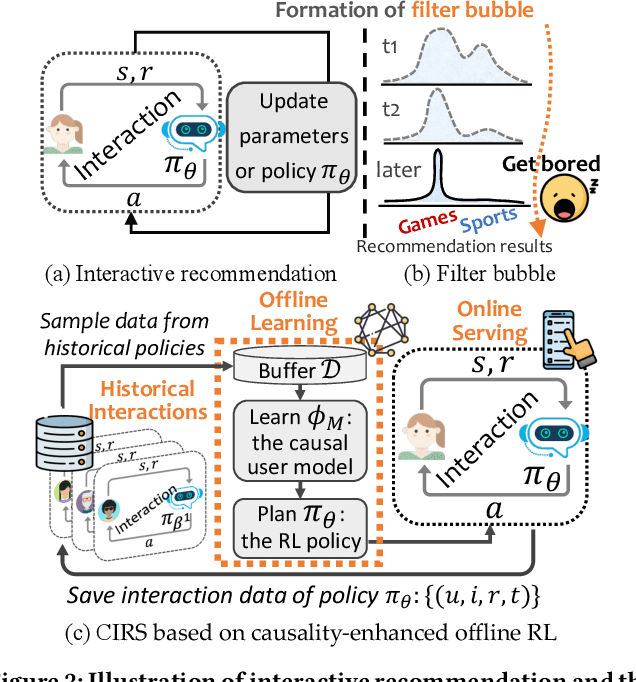
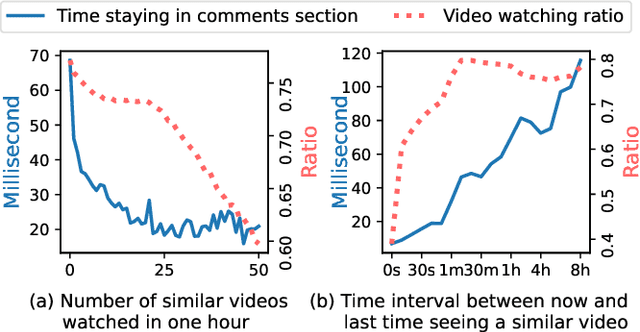
While personalization increases the utility of recommender systems, it also brings the issue of filter bubbles. E.g., if the system keeps exposing and recommending the items that the user is interested in, it may also make the user feel bored and less satisfied. Existing work studies filter bubbles in static recommendation, where the effect of overexposure is hard to capture. In contrast, we believe it is more meaningful to study the issue in interactive recommendation and optimize long-term user satisfaction. Nevertheless, it is unrealistic to train the model online due to the high cost. As such, we have to leverage offline training data and disentangle the causal effect on user satisfaction. To achieve this goal, we propose a counterfactual interactive recommender system (CIRS) that augments offline reinforcement learning (offline RL) with causal inference. The basic idea is to first learn a causal user model on historical data to capture the overexposure effect of items on user satisfaction. It then uses the learned causal user model to help the planning of the RL policy. To conduct evaluation offline, we innovatively create an authentic RL environment (KuaiEnv) based on a real-world fully observed user rating dataset. The experiments show the effectiveness of CIRS in bursting filter bubbles and achieving long-term success in interactive recommendation. The implementation of CIRS is available via https://github.com/chongminggao/CIRS-codes.