 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVideoAgent: Multi-Agent Reasoning with Long Videos
Dec 23, 2025



Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Dec 19, 2025Multimodal Large Language Models struggle to maintain reliable performance under extreme real-world visual degradations, which impede their practical robustness. Existing robust MLLMs predominantly rely on implicit training/adaptation that focuses solely on visual encoder generalization, suffering from limited interpretability and isolated optimization. To overcome these limitations, we propose Robust-R1, a novel framework that explicitly models visual degradations through structured reasoning chains. Our approach integrates: (i) supervised fine-tuning for degradation-aware reasoning foundations, (ii) reward-driven alignment for accurately perceiving degradation parameters, and (iii) dynamic reasoning depth scaling adapted to degradation intensity. To facilitate this approach, we introduce a specialized 11K dataset featuring realistic degradations synthesized across four critical real-world visual processing stages, each annotated with structured chains connecting degradation parameters, perceptual influence, pristine semantic reasoning chain, and conclusion. Comprehensive evaluations demonstrate state-of-the-art robustness: Robust-R1 outperforms all general and robust baselines on the real-world degradation benchmark R-Bench, while maintaining superior anti-degradation performance under multi-intensity adversarial degradations on MMMB, MMStar, and RealWorldQA.
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025



Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025



The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
Sage Deer: A Super-Aligned Driving Generalist Is Your Copilot
May 15, 2025The intelligent driving cockpit, an important part of intelligent driving, needs to match different users' comfort, interaction, and safety needs. This paper aims to build a Super-Aligned and GEneralist DRiving agent, SAGE DeeR. Sage Deer achieves three highlights: (1) Super alignment: It achieves different reactions according to different people's preferences and biases. (2) Generalist: It can understand the multi-view and multi-mode inputs to reason the user's physiological indicators, facial emotions, hand movements, body movements, driving scenarios, and behavioral decisions. (3) Self-Eliciting: It can elicit implicit thought chains in the language space to further increase generalist and super-aligned abilities. Besides, we collected multiple data sets and built a large-scale benchmark. This benchmark measures the deer's perceptual decision-making ability and the super alignment's accuracy.
Locating and Mitigating Gradient Conflicts in Point Cloud Domain Adaptation via Saliency Map Skewness
Apr 22, 2025



Object classification models utilizing point cloud data are fundamental for 3D media understanding, yet they often struggle with unseen or out-of-distribution (OOD) scenarios. Existing point cloud unsupervised domain adaptation (UDA) methods typically employ a multi-task learning (MTL) framework that combines primary classification tasks with auxiliary self-supervision tasks to bridge the gap between cross-domain feature distributions. However, our further experiments demonstrate that not all gradients from self-supervision tasks are beneficial and some may negatively impact the classification performance. In this paper, we propose a novel solution, termed Saliency Map-based Data Sampling Block (SM-DSB), to mitigate these gradient conflicts. Specifically, our method designs a new scoring mechanism based on the skewness of 3D saliency maps to estimate gradient conflicts without requiring target labels. Leveraging this, we develop a sample selection strategy that dynamically filters out samples whose self-supervision gradients are not beneficial for the classification. Our approach is scalable, introducing modest computational overhead, and can be integrated into all the point cloud UDA MTL frameworks. Extensive evaluations demonstrate that our method outperforms state-of-the-art approaches. In addition, we provide a new perspective on understanding the UDA problem through back-propagation analysis.
SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
Mar 26, 2025



Despite the growing integration of deep models into mobile terminals, the accuracy of these models declines significantly due to various deployment interferences. Test-time adaptation (TTA) has emerged to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in resource-constrained terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios during adaptation, allowing for flexible control of learning ability and memory cost in a data-sensitive manner. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses the baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, architectures, and tasks.
CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Mar 09, 2025
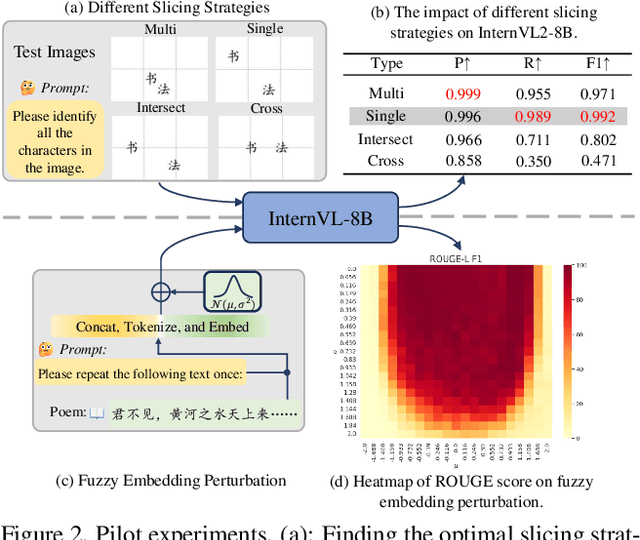
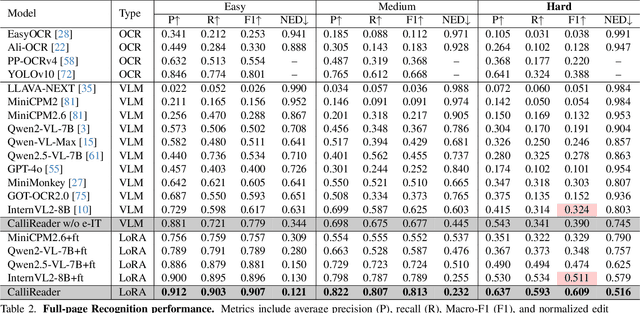
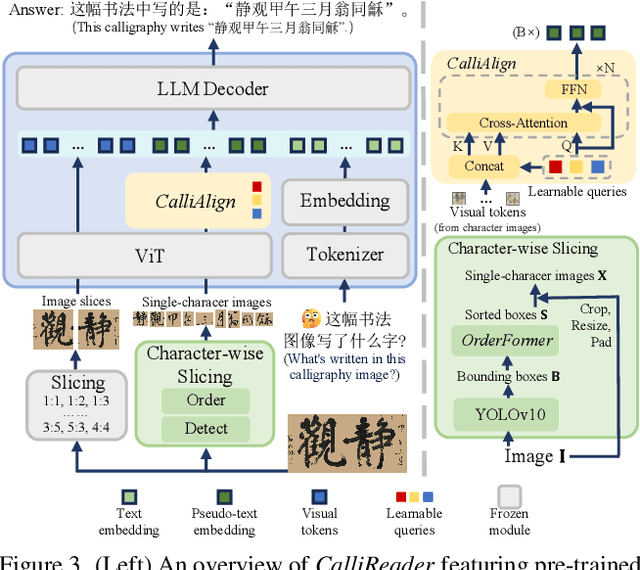
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader's \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader's efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
Adaptivity and Convergence of Probability Flow ODEs in Diffusion Generative Models
Jan 31, 2025Score-based generative models, which transform noise into data by learning to reverse a diffusion process, have become a cornerstone of modern generative AI. This paper contributes to establishing theoretical guarantees for the probability flow ODE, a widely used diffusion-based sampler known for its practical efficiency. While a number of prior works address its general convergence theory, it remains unclear whether the probability flow ODE sampler can adapt to the low-dimensional structures commonly present in natural image data. We demonstrate that, with accurate score function estimation, the probability flow ODE sampler achieves a convergence rate of $O(k/T)$ in total variation distance (ignoring logarithmic factors), where $k$ is the intrinsic dimension of the target distribution and $T$ is the number of iterations. This dimension-free convergence rate improves upon existing results that scale with the typically much larger ambient dimension, highlighting the ability of the probability flow ODE sampler to exploit intrinsic low-dimensional structures in the target distribution for faster sampling.