 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIDS: Quality-informed Incentive-driven Multi-agent Dispatching System for Mobile Crowdsensing
Dec 18, 2025



This paper addresses the challenge of achieving optimal Quality of Information (QoI) in non-dedicated vehicular mobile crowdsensing (NVMCS) systems. The key obstacles are the interrelated issues of sensing coverage, sensing reliability, and the dynamic participation of vehicles. To tackle these, we propose QUIDS, a QUality-informed Incentive-driven multi-agent Dispatching System, which ensures high sensing coverage and reliability under budget constraints. QUIDS introduces a novel metric, Aggregated Sensing Quality (ASQ), to quantitatively capture QoI by integrating both coverage and reliability. We also develop a Mutually Assisted Belief-aware Vehicle Dispatching algorithm that estimates sensing reliability and allocates incentives under uncertainty, further improving ASQ. Evaluation using real-world data from a metropolitan NVMCS deployment shows QUIDS improves ASQ by 38% over non-dispatching scenarios and by 10% over state-of-the-art methods. It also reduces reconstruction map errors by 39-74% across algorithms. By jointly optimizing coverage and reliability via a quality-informed incentive mechanism, QUIDS enables low-cost, high-quality urban monitoring without dedicated infrastructure, applicable to smart-city scenarios like traffic and environmental sensing.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Aug 18, 2025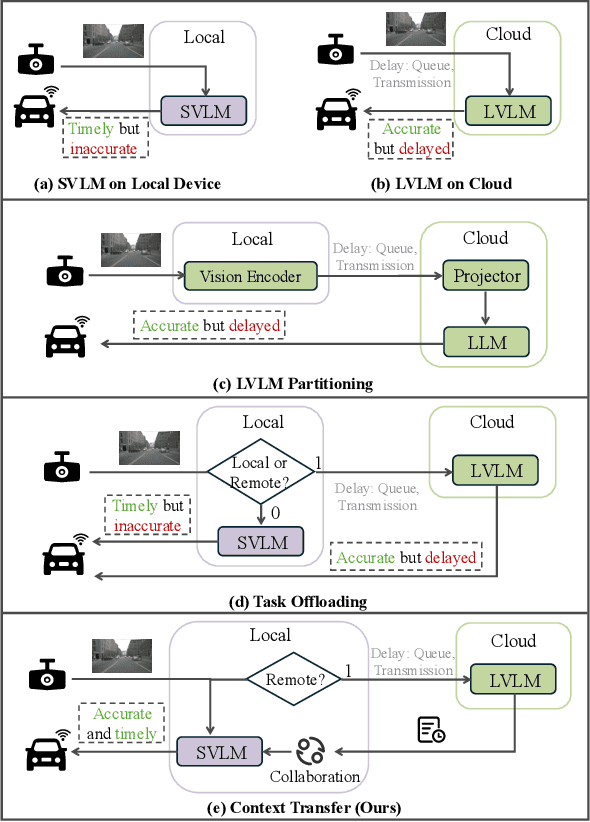
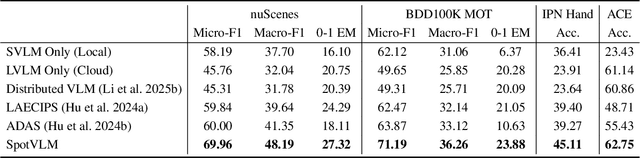
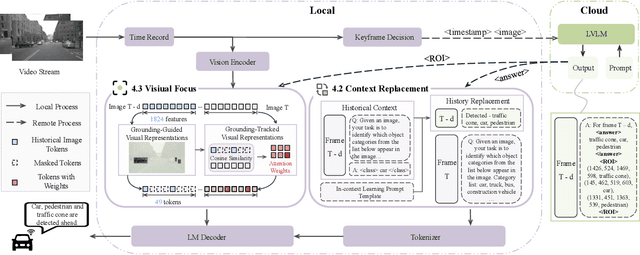
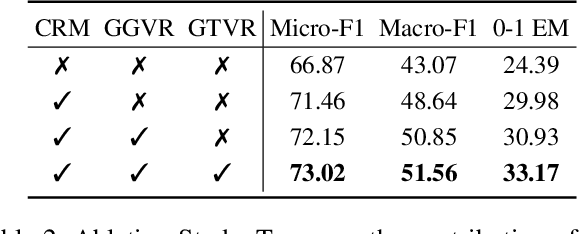
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.
SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Aug 08, 2025



Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5\% on VOC, 8.9\% on Context, 2.6\% on Object and 2.0\% on City.
SpecOffload: Unlocking Latent GPU Capacity for LLM Inference on Resource-Constrained Devices
May 15, 2025Efficient LLM inference on resource-constrained devices presents significant challenges in compute and memory utilization. Due to limited GPU memory, existing systems offload model weights to CPU memory, incurring substantial I/O overhead between the CPU and GPU. This leads to two major inefficiencies: (1) GPU cores are underutilized, often remaining idle while waiting for data to be loaded; and (2) GPU memory has low impact on performance, as reducing its capacity has minimal effect on overall throughput.In this paper, we propose SpecOffload, a high-throughput inference engine that embeds speculative decoding into offloading. Our key idea is to unlock latent GPU resources for storing and executing a draft model used for speculative decoding, thus accelerating inference at near-zero additional cost. To support this, we carefully orchestrate the interleaved execution of target and draft models in speculative decoding within the offloading pipeline, and propose a planner to manage tensor placement and select optimal parameters. Compared to the best baseline, SpecOffload improves GPU core utilization by 4.49x and boosts inference throughput by 2.54x. Our code is available at https://github.com/MobiSense/SpecOffload .
SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
Mar 26, 2025



Despite the growing integration of deep models into mobile terminals, the accuracy of these models declines significantly due to various deployment interferences. Test-time adaptation (TTA) has emerged to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in resource-constrained terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios during adaptation, allowing for flexible control of learning ability and memory cost in a data-sensitive manner. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses the baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, architectures, and tasks.
Palantir: Towards Efficient Super Resolution for Ultra-high-definition Live Streaming
Aug 12, 2024Neural enhancement through super-resolution deep neural networks opens up new possibilities for ultra-high-definition live streaming over existing encoding and networking infrastructure. Yet, the heavy SR DNN inference overhead leads to severe deployment challenges. To reduce the overhead, existing systems propose to apply DNN-based SR only on selected anchor frames while upscaling non-anchor frames via the lightweight reusing-based SR approach. However, frame-level scheduling is coarse-grained and fails to deliver optimal efficiency. In this work, we propose Palantir, the first neural-enhanced UHD live streaming system with fine-grained patch-level scheduling. In the presented solutions, two novel techniques are incorporated to make good scheduling decisions for inference overhead optimization and reduce the scheduling latency. Firstly, under the guidance of our pioneering and theoretical analysis, Palantir constructs a directed acyclic graph (DAG) for lightweight yet accurate quality estimation under any possible anchor patch set. Secondly, to further optimize the scheduling latency, Palantir improves parallelizability by refactoring the computation subprocedure of the estimation process into a sparse matrix-matrix multiplication operation. The evaluation results suggest that Palantir incurs a negligible scheduling latency accounting for less than 5.7% of the end-to-end latency requirement. When compared to the state-of-the-art real-time frame-level scheduling strategy, Palantir reduces the energy overhead of SR-integrated mobile clients by 38.1% at most (and 22.4% on average) and the monetary costs of cloud-based SR by 80.1% at most (and 38.4% on average).