 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk the Talk: Bridging the Reasoning-Action Gap for Thinking with Images via Multimodal Agentic Policy Optimization
Apr 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have incentivized models to ``think with images'' by actively invoking visual tools during multi-turn reasoning. The common Reinforcement Learning (RL) practice of relying on outcome-based rewards ignores the fact that textual plausibility often masks executive failure, meaning that models may exhibit intuitive textual reasoning while executing imprecise or irrelevant visual actions within their agentic reasoning trajectories. This reasoning-action discrepancy introduces noise that accumulates throughout the multi-turn reasoning process, severely degrading the model's multimodal reasoning capabilities and potentially leading to training collapse. In this paper, we introduce Multimodal Agentic Policy Optimization (MAPO), bridging the gap between textual reasoning and visual actions generated by models within their Multimodal Chain-of-Thought (MCoT). Specifically, MAPO mandates the model to generate explicit textual descriptions for the visual content obtained via tool usage. We then employ a novel advantage estimation that couples the semantic alignment between these descriptions and the actual observations with the task reward. Theoretical findings are provided to justify the rationale behind MAPO, which inherently reduces the variance of gradients, and extensive experiments demonstrate that our method achieves superior performance across multiple visual reasoning benchmarks.
Training-Free Image Editing with Visual Context Integration and Concept Alignment
Apr 06, 2026In image editing, it is essential to incorporate a context image to convey the user's precise requirements, such as subject appearance or image style. Existing training-based visual context-aware editing methods incur data collection effort and training cost. On the other hand, the training-free alternatives are typically established on diffusion inversion, which struggles with consistency and flexibility. In this work, we propose VicoEdit, a training-free and inversion-free method to inject the visual context into the pretrained text-prompted editing model. More specifically, VicoEdit directly transforms the source image into the target one based on the visual context, thereby eliminating the need for inversion that can lead to deviated trajectories. Moreover, we design a posterior sampling approach guided by concept alignment to enhance the editing consistency. Empirical results demonstrate that our training-free method achieves even better editing performance than the state-of-the-art training-based models.
M$^2$: Dual-Memory Augmentation for Long-Horizon Web Agents via Trajectory Summarization and Insight Retrieval
Feb 28, 2026Multimodal Large Language Models (MLLMs) based agents have demonstrated remarkable potential in autonomous web navigation. However, handling long-horizon tasks remains a critical bottleneck. Prevailing strategies often rely heavily on extensive data collection and model training, yet still struggle with high computational costs and insufficient reasoning capabilities when facing complex, long-horizon scenarios. To address this, we propose M$^2$, a training-free, memory-augmented framework designed to optimize context efficiency and decision-making robustness. Our approach incorporates a dual-tier memory mechanism that synergizes Dynamic Trajectory Summarization (Internal Memory) to compress verbose interaction history into concise state updates, and Insight Retrieval Augmentation (External Memory) to guide the agent with actionable guidelines retrieved from an offline insight bank. Extensive evaluations across WebVoyager and OnlineMind2Web demonstrate that M$^2$ consistently surpasses baselines, yielding up to a 19.6% success rate increase and 58.7% token reduction for Qwen3-VL-32B, while proprietary models like Claude achieve accuracy gains up to 12.5% alongside significantly lower computational overhead.
Building Autonomous GUI Navigation via Agentic-Q Estimation and Step-Wise Policy Optimization
Feb 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have substantially driven the progress of autonomous agents for Graphical User Interface (GUI). Nevertheless, in real-world applications, GUI agents are often faced with non-stationary environments, leading to high computational costs for data curation and policy optimization. In this report, we introduce a novel MLLM-centered framework for GUI agents, which consists of two components: agentic-Q estimation and step-wise policy optimization. The former one aims to optimize a Q-model that can generate step-wise values to evaluate the contribution of a given action to task completion. The latter one takes step-wise samples from the state-action trajectory as inputs, and optimizes the policy via reinforcement learning with our agentic-Q model. It should be noticed that (i) all state-action trajectories are produced by the policy itself, so that the data collection costs are manageable; (ii) the policy update is decoupled from the environment, ensuring stable and efficient optimization. Empirical evaluations show that our framework endows Ovis2.5-9B with powerful GUI interaction capabilities, achieving remarkable performances on GUI navigation and grounding benchmarks and even surpassing contenders with larger scales.
Adaptive Debiasing Tsallis Entropy for Test-Time Adaptation
Feb 12, 2026Mainstream Test-Time Adaptation (TTA) methods for adapting vision-language models, e.g., CLIP, typically rely on Shannon Entropy (SE) at test time to measure prediction uncertainty and inconsistency. However, since CLIP has a built-in bias from pretraining on highly imbalanced web-crawled data, SE inevitably results in producing biased estimates of uncertainty entropy. To address this issue, we notably find and demonstrate that Tsallis Entropy (TE), a generalized form of SE, is naturally suited for characterizing biased distributions by introducing a non-extensive parameter q, with the performance of SE serving as a lower bound for TE. Building upon this, we generalize TE into Adaptive Debiasing Tsallis Entropy (ADTE) for TTA, customizing a class-specific parameter q^l derived by normalizing the estimated label bias from continuously incoming test instances, for each category. This adaptive approach allows ADTE to accurately select high-confidence views and seamlessly integrate with a label adjustment strategy to enhance adaptation, without introducing distribution-specific hyperparameter tuning. Besides, our investigation reveals that both TE and ADTE can serve as direct, advanced alternatives to SE in TTA, without any other modifications. Experimental results show that ADTE outperforms state-of-the-art methods on ImageNet and its five variants, and achieves the highest average performance on 10 cross-domain benchmarks, regardless of the model architecture or text prompts used. Our code is available at https://github.com/Jinx630/ADTE.
Triplets Better Than Pairs: Towards Stable and Effective Self-Play Fine-Tuning for LLMs
Jan 13, 2026Recently, self-play fine-tuning (SPIN) has been proposed to adapt large language models to downstream applications with scarce expert-annotated data, by iteratively generating synthetic responses from the model itself. However, SPIN is designed to optimize the current reward advantages of annotated responses over synthetic responses at hand, which may gradually vanish during iterations, leading to unstable optimization. Moreover, the utilization of reference policy induces a misalignment issue between the reward formulation for training and the metric for generation. To address these limitations, we propose a novel Triplet-based Self-Play fIne-tuNing (T-SPIN) method that integrates two key designs. First, beyond current advantages, T-SPIN additionally incorporates historical advantages between iteratively generated responses and proto-synthetic responses produced by the initial policy. Even if the current advantages diminish, historical advantages remain effective, stabilizing the overall optimization. Second, T-SPIN introduces the entropy constraint into the self-play framework, which is theoretically justified to support reference-free fine-tuning, eliminating the training-generation discrepancy. Empirical results on various tasks demonstrate not only the superior performance of T-SPIN over SPIN, but also its stable evolution during iterations. Remarkably, compared to supervised fine-tuning, T-SPIN achieves comparable or even better performance with only 25% samples, highlighting its effectiveness when faced with scarce annotated data.
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images
Dec 19, 2025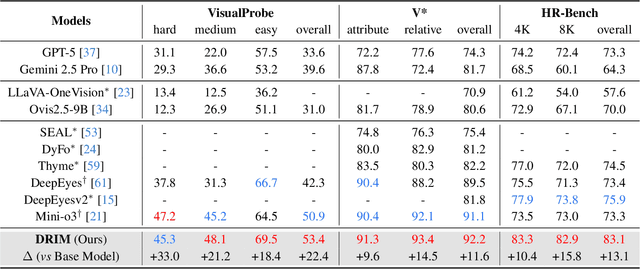
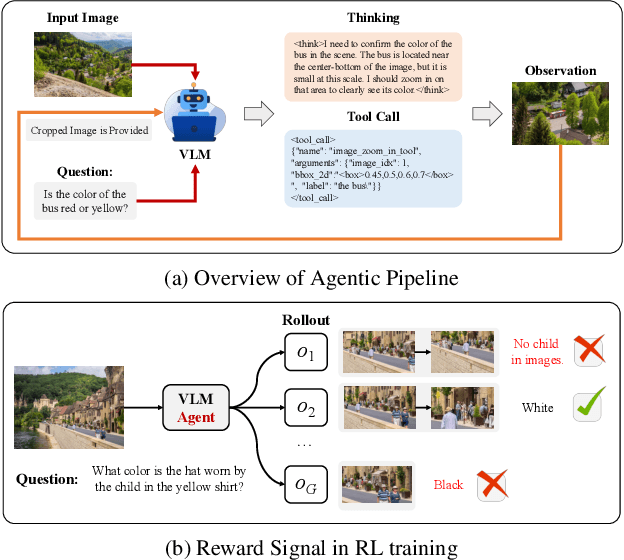
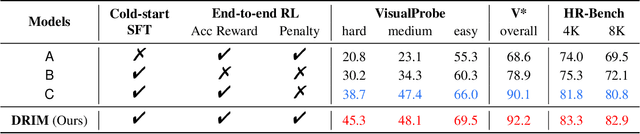
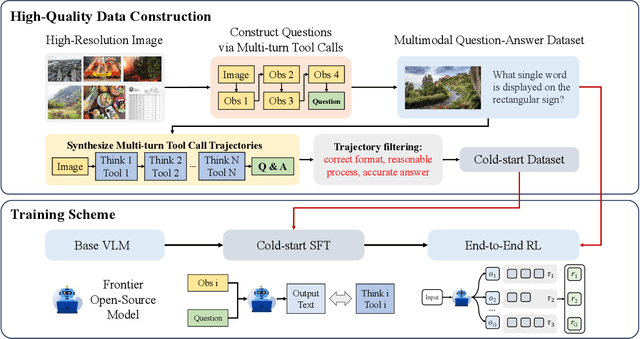
Recent advances in large Vision-Language Models (VLMs) have exhibited strong reasoning capabilities on complex visual tasks by thinking with images in their Chain-of-Thought (CoT), which is achieved by actively invoking tools to analyze visual inputs rather than merely perceiving them. However, existing models often struggle to reflect on and correct themselves when attempting incorrect reasoning trajectories. To address this limitation, we propose DRIM, a model that enables deep but reliable multi-turn reasoning when thinking with images in its multimodal CoT. Our pipeline comprises three stages: data construction, cold-start SFT and RL. Based on a high-resolution image dataset, we construct high-difficulty and verifiable visual question-answer pairs, where solving each task requires multi-turn tool calls to reach the correct answer. In the SFT stage, we collect tool trajectories as cold-start data, guiding a multi-turn reasoning pattern. In the RL stage, we introduce redundancy-penalized policy optimization, which incentivizes the model to develop a self-reflective reasoning pattern. The basic idea is to impose judgment on reasoning trajectories and penalize those that produce incorrect answers without sufficient multi-scale exploration. Extensive experiments demonstrate that DRIM achieves superior performance on visual understanding benchmarks.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025



The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
Multimodal Tabular Reasoning with Privileged Structured Information
Jun 04, 2025Tabular reasoning involves multi-step information extraction and logical inference over tabular data. While recent advances have leveraged large language models (LLMs) for reasoning over structured tables, such high-quality textual representations are often unavailable in real-world settings, where tables typically appear as images. In this paper, we tackle the task of tabular reasoning from table images, leveraging privileged structured information available during training to enhance multimodal large language models (MLLMs). The key challenges lie in the complexity of accurately aligning structured information with visual representations, and in effectively transferring structured reasoning skills to MLLMs despite the input modality gap. To address these, we introduce TabUlar Reasoning with Bridged infOrmation ({\sc Turbo}), a new framework for multimodal tabular reasoning with privileged structured tables. {\sc Turbo} benefits from a structure-aware reasoning trace generator based on DeepSeek-R1, contributing to high-quality modality-bridged data. On this basis, {\sc Turbo} repeatedly generates and selects the advantageous reasoning paths, further enhancing the model's tabular reasoning ability. Experimental results demonstrate that, with limited ($9$k) data, {\sc Turbo} achieves state-of-the-art performance ($+7.2\%$ vs. previous SOTA) across multiple datasets.