 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide-Aware Boundary Localization for More Precise Object Detection
Dec 09, 2019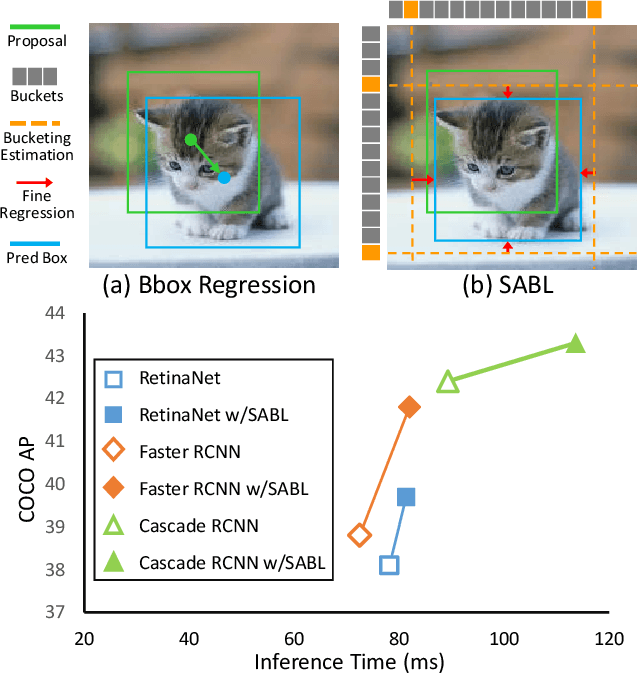
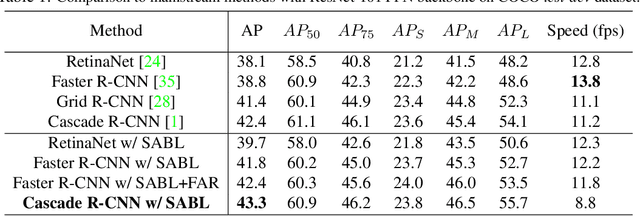
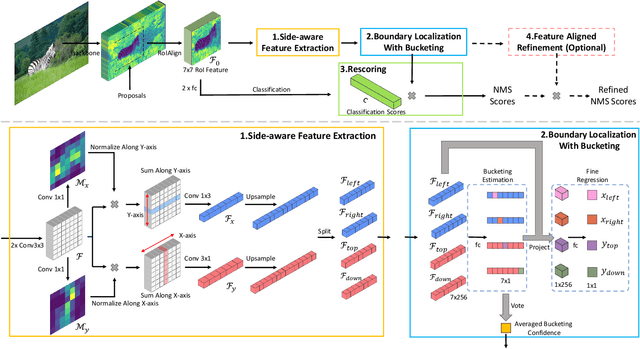
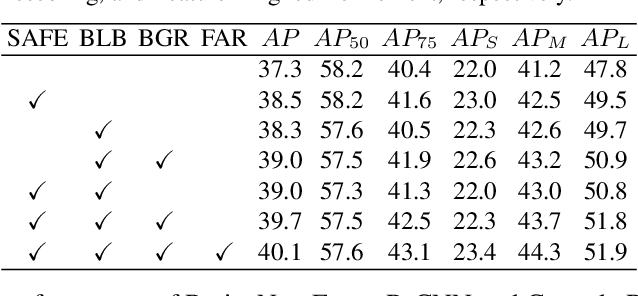
Current object detection frameworks mainly rely on bounding box regression to localize objects. Despite the remarkable progress in recent years, the precision of bounding box regression remains unsatisfactory, hence limiting performance in object detection. We observe that precise localization requires careful placement of each side of the bounding box. However, the mainstream approach, which focuses on predicting centers and sizes, is not the most effective way to accomplish this task, especially when there exists displacements with large variance between the anchors and the targets.In this paper, we propose an alternative approach, named as Side-Aware Boundary Localization (SABL), where each side of the bounding box is respectively localized with a dedicated network branch. Moreover, to tackle the difficulty of precise localization in the presence of displacements with large variance, we further propose a two-step localization scheme, which first predicts a range of movement through bucket prediction and then pinpoints the precise position within the predicted bucket. We test the proposed method on both two-stage and single-stage detection frameworks. Replacing the standard bounding box regression branch with the proposed design leads to significant improvements on Faster R-CNN, RetinaNet, and Cascade R-CNN, by 3.0%, 1.6%, and 0.9%, respectively. Code and models will be available at https://github.com/open-mmlab/mmdetection.
Learning Driving Decisions by Imitating Drivers' Control Behaviors
Nov 30, 2019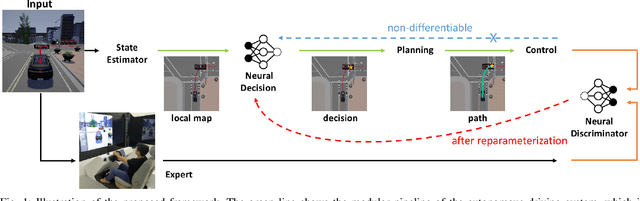
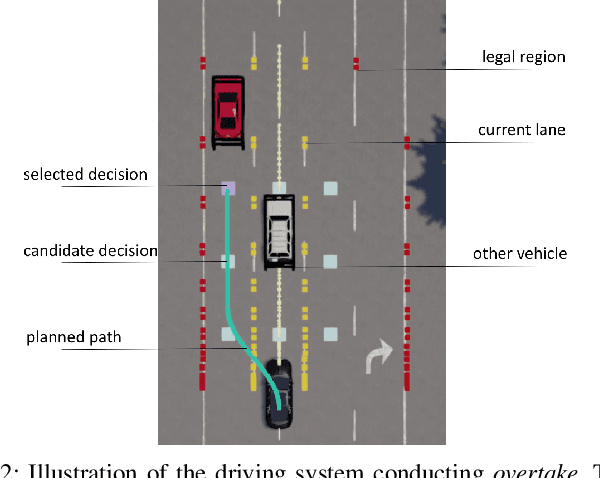
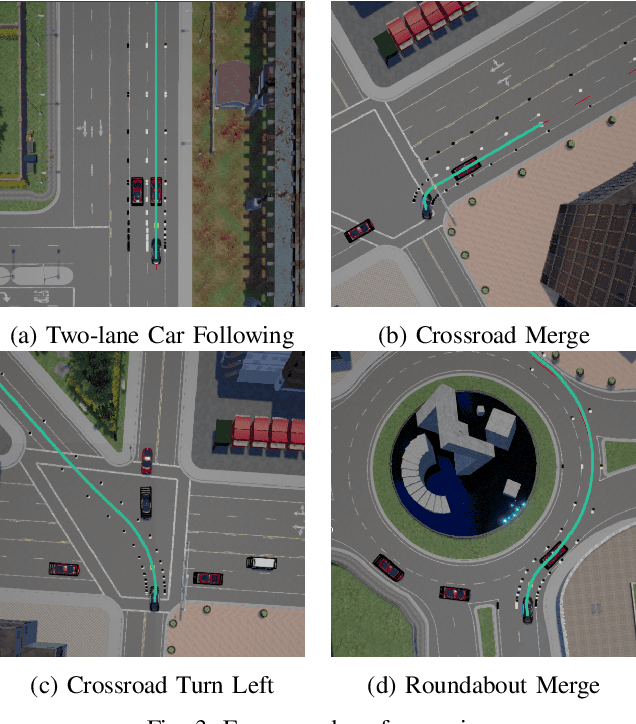

Classical autonomous driving systems are modularized as a pipeline of perception, decision, planning, and control. The driving decision plays a central role in processing the observation from the perception as well as directing the execution of downstream planning and control modules. Commonly the decision module is designed to be rule-based and is difficult to learn from data. Recently end-to-end neural control policy has been proposed to replace this pipeline, given its generalization ability. However, it remains challenging to enforce physical or logical constraints on the decision to ensure driving safety and stability. In this work, we propose a hybrid framework for learning a decision module, which is agnostic to the mechanisms of perception, planning, and control modules. By imitating the low-level control behavior, it learns the high-level driving decisions while bypasses the ambiguous annotation of high-level driving decisions. We demonstrate that the simulation agents with a learned decision module can be generalized to various complex driving scenarios where the rule-based approach fails. Furthermore, it can generate driving behaviors that are smoother and safer than end-to-end neural policies.
Every Frame Counts: Joint Learning of Video Segmentation and Optical Flow
Nov 28, 2019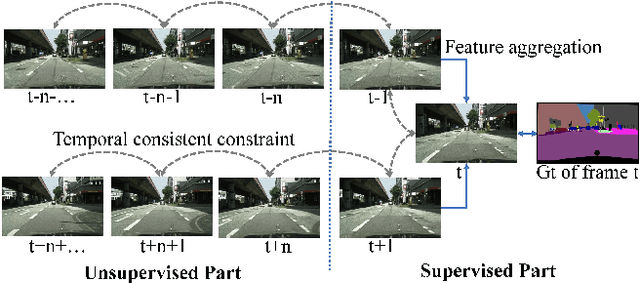

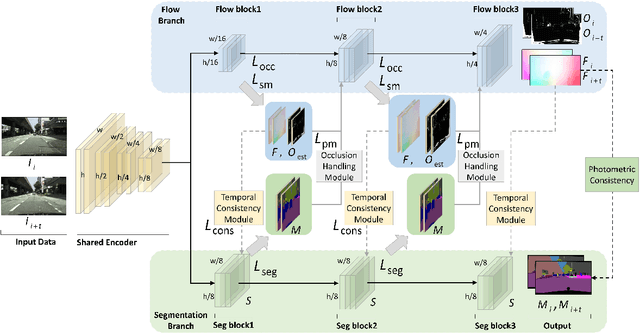
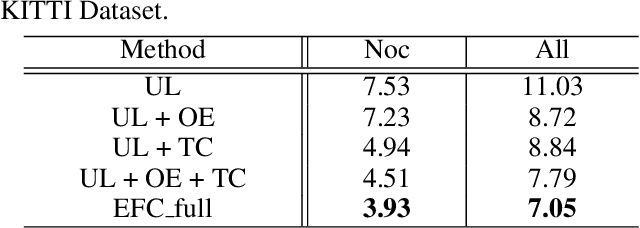
A major challenge for video semantic segmentation is the lack of labeled data. In most benchmark datasets, only one frame of a video clip is annotated, which makes most supervised methods fail to utilize information from the rest of the frames. To exploit the spatio-temporal information in videos, many previous works use pre-computed optical flows, which encode the temporal consistency to improve the video segmentation. However, the video segmentation and optical flow estimation are still considered as two separate tasks. In this paper, we propose a novel framework for joint video semantic segmentation and optical flow estimation. Semantic segmentation brings semantic information to handle occlusion for more robust optical flow estimation, while the non-occluded optical flow provides accurate pixel-level temporal correspondences to guarantee the temporal consistency of the segmentation. Moreover, our framework is able to utilize both labeled and unlabeled frames in the video through joint training, while no additional calculation is required in inference. Extensive experiments show that the proposed model makes the video semantic segmentation and optical flow estimation benefit from each other and outperforms existing methods under the same settings in both tasks.
Dense Fusion Classmate Network for Land Cover Classification
Nov 19, 2019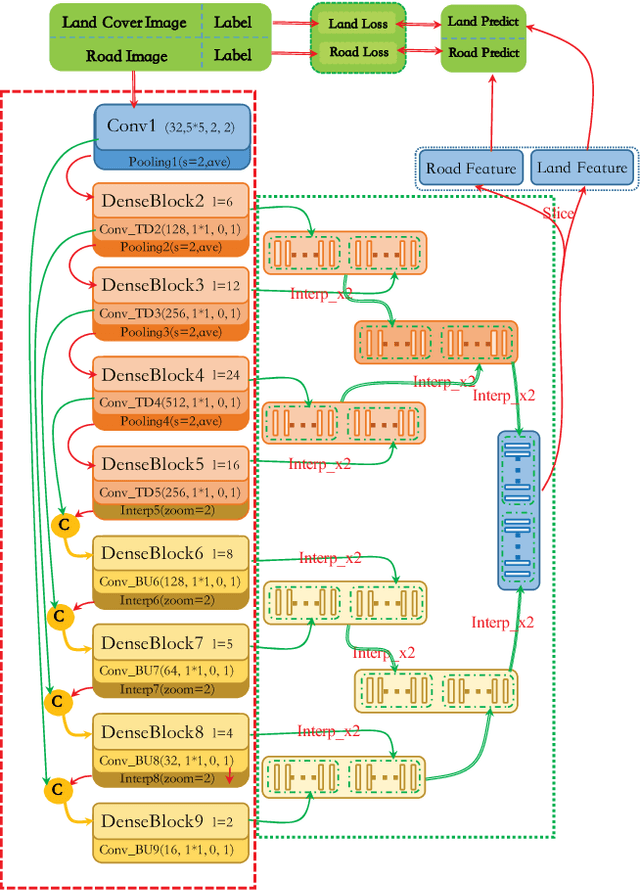
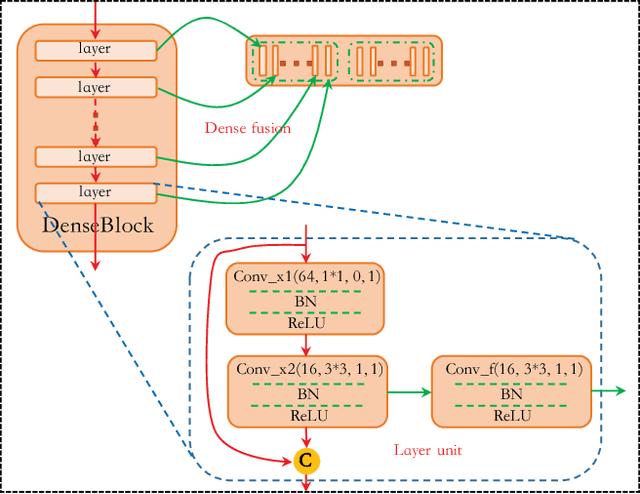

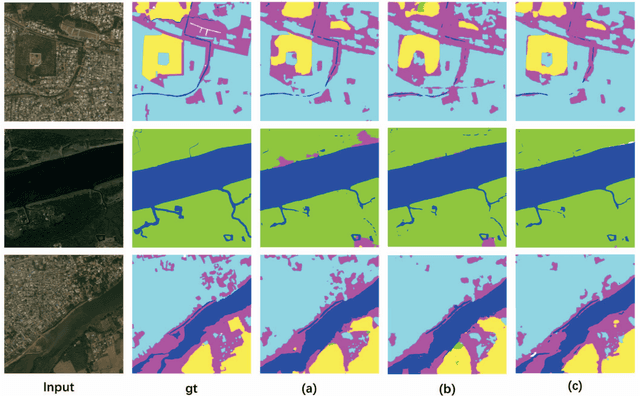
Recently, FCNs based methods have made great progress in semantic segmentation. Different with ordinary scenes, satellite image owns specific characteristics, which elements always extend to large scope and no regular or clear boundaries. Therefore, effective mid-level structure information extremely missing, precise pixel-level classification becomes tough issues. In this paper, a Dense Fusion Classmate Network (DFCNet) is proposed to adopt in land cover classification.
Depth Completion from Sparse LiDAR Data with Depth-Normal Constraints
Oct 15, 2019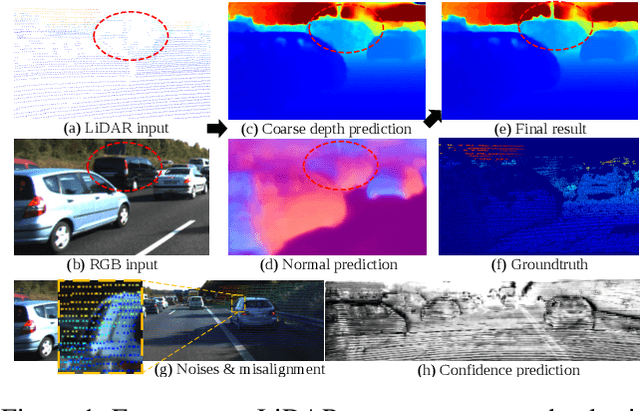
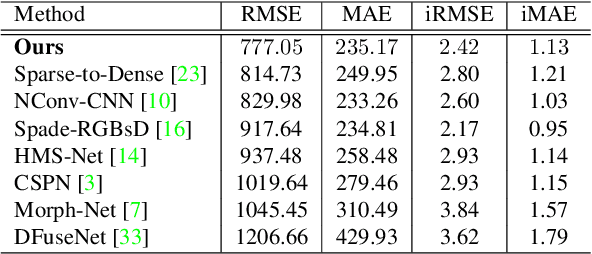
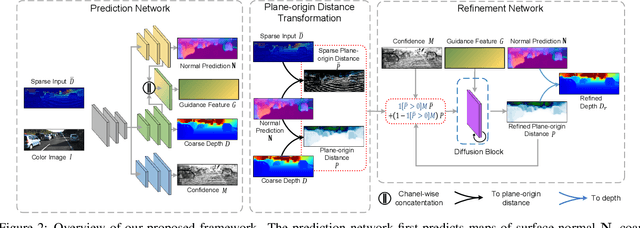
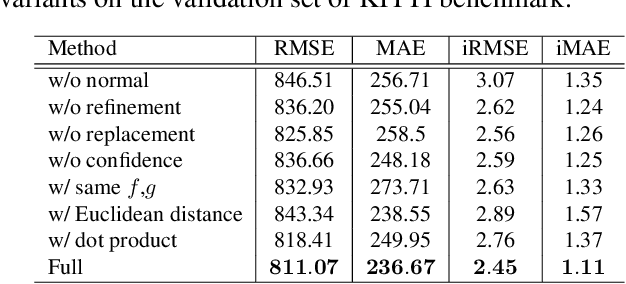
Depth completion aims to recover dense depth maps from sparse depth measurements. It is of increasing importance for autonomous driving and draws increasing attention from the vision community. Most of existing methods directly train a network to learn a mapping from sparse depth inputs to dense depth maps, which has difficulties in utilizing the 3D geometric constraints and handling the practical sensor noises. In this paper, to regularize the depth completion and improve the robustness against noise, we propose a unified CNN framework that 1) models the geometric constraints between depth and surface normal in a diffusion module and 2) predicts the confidence of sparse LiDAR measurements to mitigate the impact of noise. Specifically, our encoder-decoder backbone predicts surface normals, coarse depth and confidence of LiDAR inputs simultaneously, which are subsequently inputted into our diffusion refinement module to obtain the final completion results. Extensive experiments on KITTI depth completion dataset and NYU-Depth-V2 dataset demonstrate that our method achieves state-of-the-art performance. Further ablation study and analysis give more insights into the proposed method and demonstrate the generalization capability and stability of our model.
Graph-guided Architecture Search for Real-time Semantic Segmentation
Sep 15, 2019
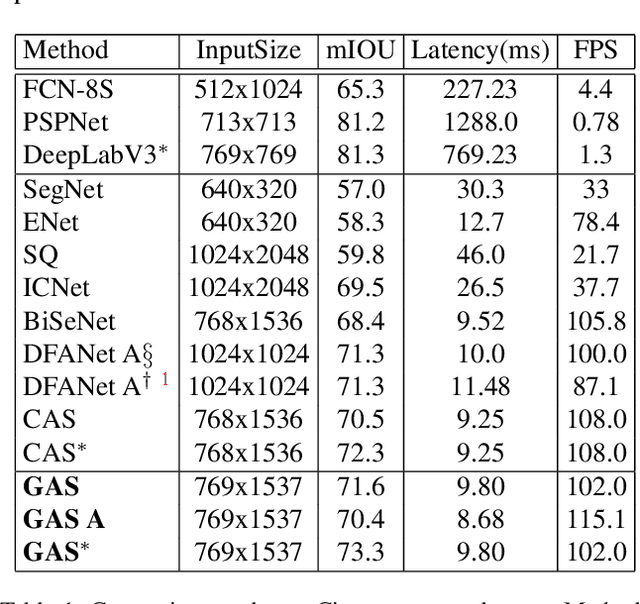
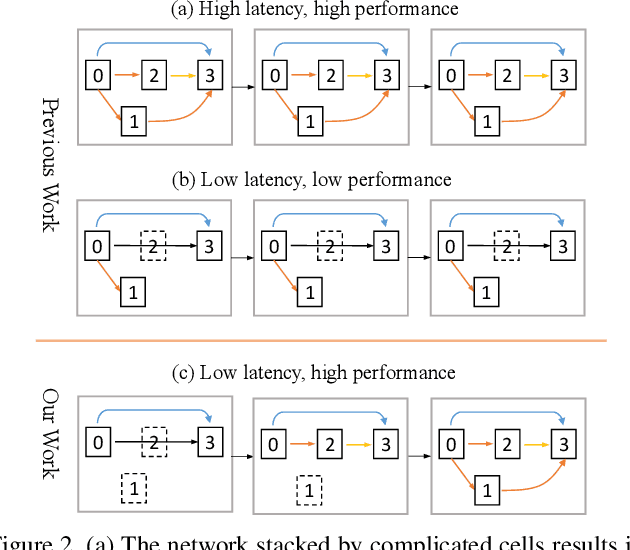
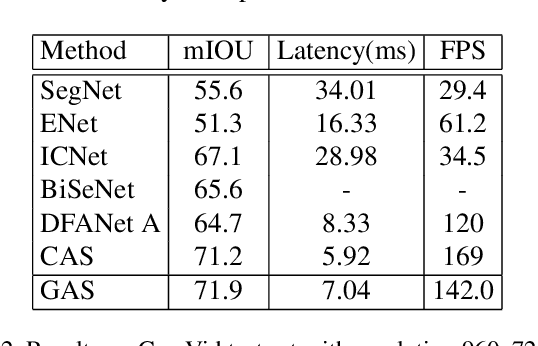
Designing a lightweight semantic segmentation network often requires researchers to find a trade-off between performance and speed, which is always empirical due to the limited interpretability of neural networks. In order to release researchers from these tedious mechanical trials, we propose a Graph-guided Architecture Search (GAS) pipeline to automatically search real-time semantic segmentation networks. Unlike previous works that use a simplified search space and stack a repeatable cell to form a network, we introduce a novel search mechanism with new search space where a lightweight model can be effectively explored through the cell-level diversity and latencyoriented constraint. Specifically, to produce the cell-level diversity, the cell-sharing constraint is eliminated through the cell-independent manner. Then a graph convolution network (GCN) is seamlessly integrated as a communication mechanism between cells. Finally, a latency-oriented constraint is endowed into the search process to balance the speed and performance. Extensive experiments on Cityscapes and CamVid datasets demonstrate that GAS achieves new state-of-the-art trade-off between accuracy and speed. In particular, on Cityscapes dataset, GAS achieves the new best performance of 73.3% mIoU with speed of 102 FPS on Titan Xp.
Robust Multi-Modality Multi-Object Tracking
Sep 09, 2019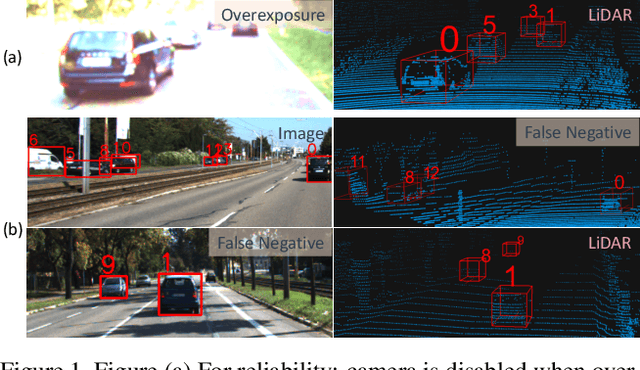
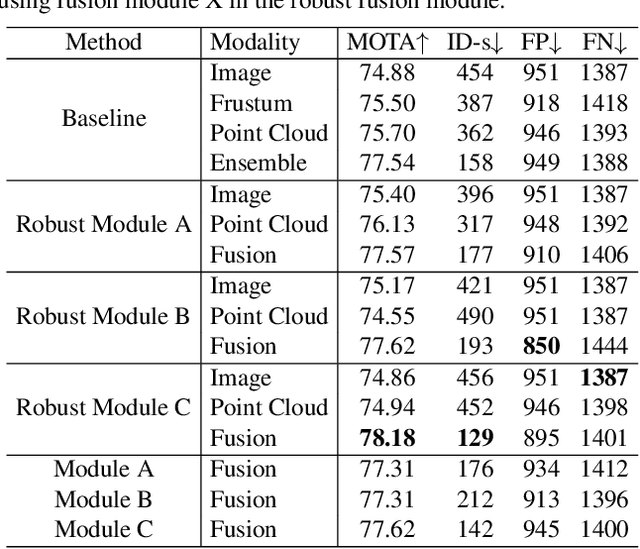
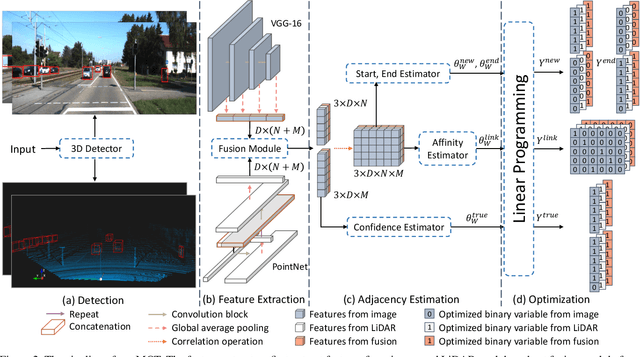
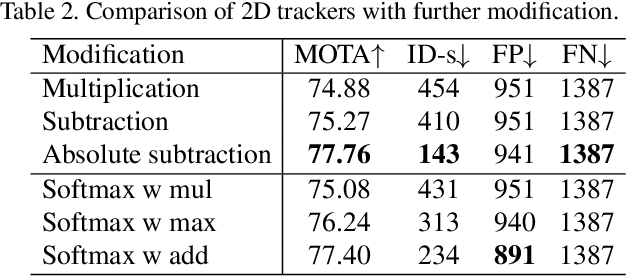
Multi-sensor perception is crucial to ensure the reliability and accuracy in autonomous driving system, while multi-object tracking (MOT) improves that by tracing sequential movement of dynamic objects. Most current approaches for multi-sensor multi-object tracking are either lack of reliability by tightly relying on a single input source (e.g., center camera), or not accurate enough by fusing the results from multiple sensors in post processing without fully exploiting the inherent information. In this study, we design a generic sensor-agnostic multi-modality MOT framework (mmMOT), where each modality (i.e., sensors) is capable of performing its role independently to preserve reliability, and further improving its accuracy through a novel multi-modality fusion module. Our mmMOT can be trained in an end-to-end manner, enables joint optimization for the base feature extractor of each modality and an adjacency estimator for cross modality. Our mmMOT also makes the first attempt to encode deep representation of point cloud in data association process in MOT. We conduct extensive experiments to evaluate the effectiveness of the proposed framework on the challenging KITTI benchmark and report state-of-the-art performance. Code and models are available at https://github.com/ZwwWayne/mmMOT.
GDRQ: Group-based Distribution Reshaping for Quantization
Aug 05, 2019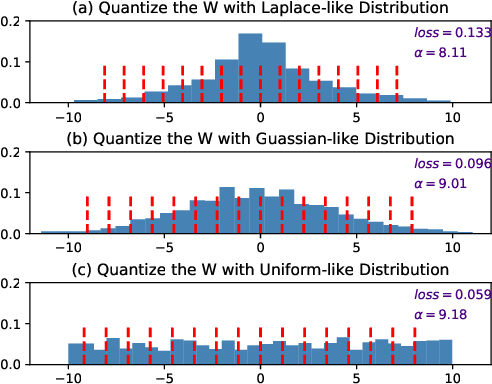

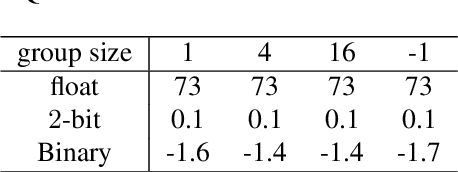
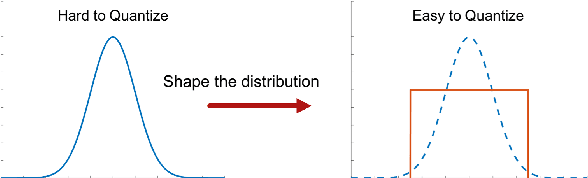
Low-bit quantization is challenging to maintain high performance with limited model capacity (e.g., 4-bit for both weights and activations). Naturally, the distribution of both weights and activations in deep neural network are Gaussian-like. Nevertheless, due to the limited bitwidth of low-bit model, uniform-like distributed weights and activations have been proved to be more friendly to quantization while preserving accuracy~\cite{Han2015Learning}. Motivated by this, we propose Scale-Clip, a Distribution Reshaping technique that can reshape weights or activations into a uniform-like distribution in a dynamic manner. Furthermore, to increase the model capability for a low-bit model, a novel Group-based Quantization algorithm is proposed to split the filters into several groups. Different groups can learn different quantization parameters, which can be elegantly merged in to batch normalization layer without extra computational cost in the inference stage. Finally, we integrate Scale-Clip technique with Group-based Quantization algorithm and propose the Group-based Distribution Reshaping Quantization (GDQR) framework to further improve the quantization performance. Experiments on various networks (e.g. VGGNet and ResNet) and vision tasks (e.g. classification, detection and segmentation) demonstrate that our framework achieves good performance.
MMDetection: Open MMLab Detection Toolbox and Benchmark
Jun 17, 2019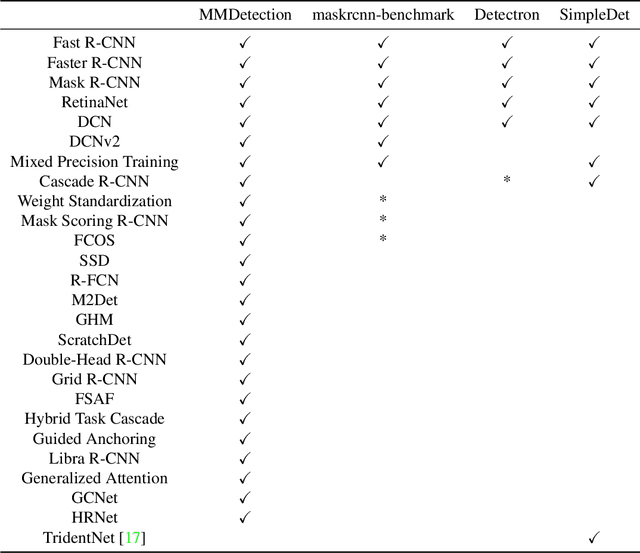
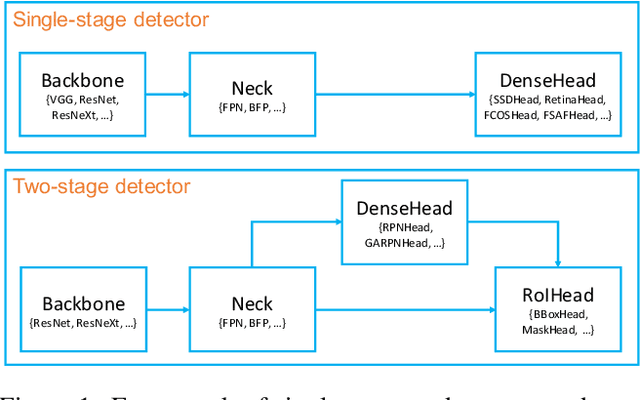
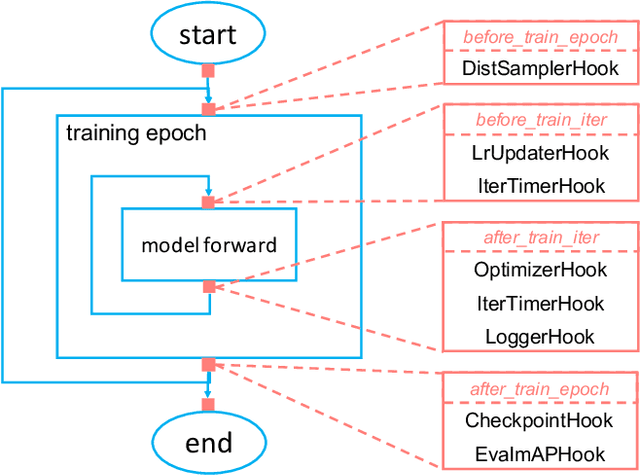
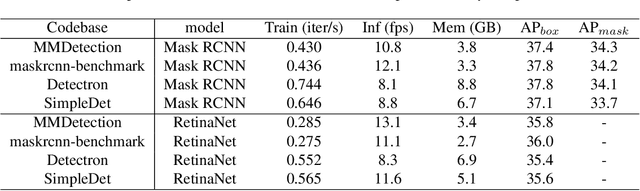
We present MMDetection, an object detection toolbox that contains a rich set of object detection and instance segmentation methods as well as related components and modules. The toolbox started from a codebase of MMDet team who won the detection track of COCO Challenge 2018. It gradually evolves into a unified platform that covers many popular detection methods and contemporary modules. It not only includes training and inference codes, but also provides weights for more than 200 network models. We believe this toolbox is by far the most complete detection toolbox. In this paper, we introduce the various features of this toolbox. In addition, we also conduct a benchmarking study on different methods, components, and their hyper-parameters. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new detectors. Code and models are available at https://github.com/open-mmlab/mmdetection. The project is under active development and we will keep this document updated.
OVSNet : Towards One-Pass Real-Time Video Object Segmentation
May 24, 2019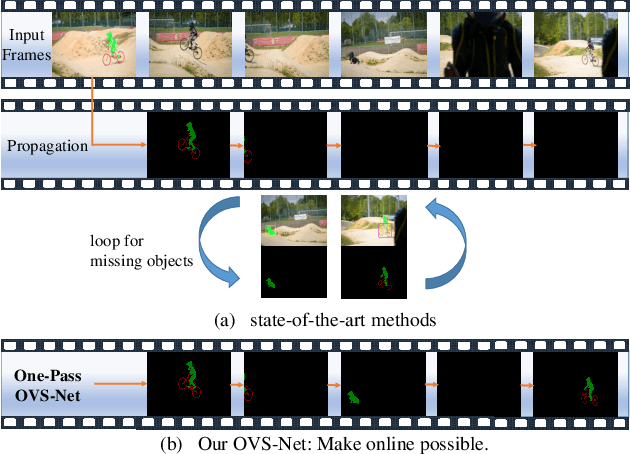
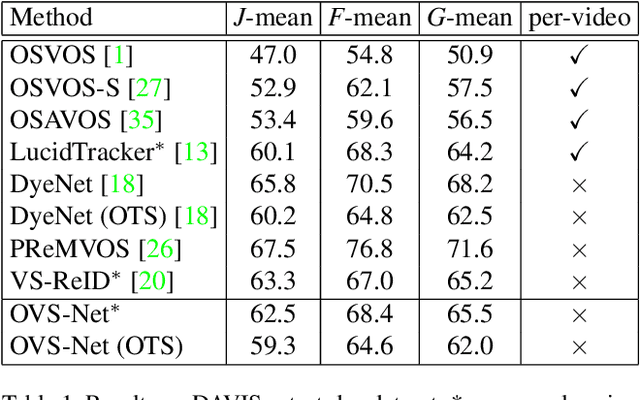
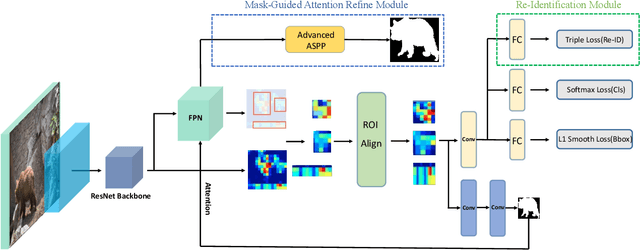
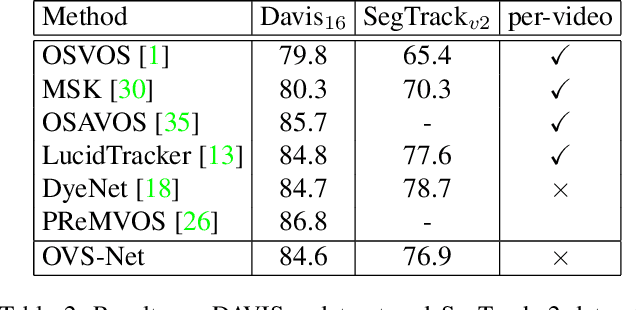
Video object segmentation aims at accurately segmenting the target object regions across consecutive frames. It is technically challenging for coping with complicated factors (e.g., shape deformations, occlusion and out of the lens). Recent approaches have largely solved them by using backforth re-identification and bi-directional mask propagation. However, their methods are extremely slow and only support offline inference, which in principle cannot be applied in real time. Motivated by this observation, we propose a new detection-based paradigm for video object segmentation. We propose an unified One-Pass Video Segmentation framework (OVS-Net) for modeling spatial-temporal representation in an end-to-end pipeline, which seamlessly integrates object detection, object segmentation, and object re-identification. The proposed framework lends itself to one-pass inference that effectively and efficiently performs video object segmentation. Moreover, we propose a mask guided attention module for modeling the multi-scale object boundary and multi-level feature fusion. Experiments on the challenging DAVIS 2017 demonstrate the effectiveness of the proposed framework with comparable performance to the state-of-the-art, and the great efficiency about 11.5 fps towards pioneering real-time work to our knowledge, more than 5 times faster than other state-of-the-art methods.