 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Nov 08, 2019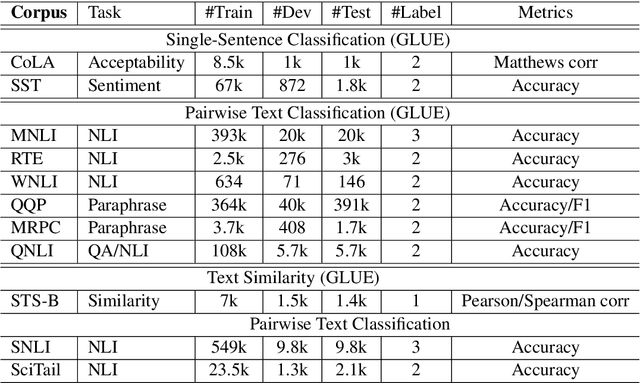
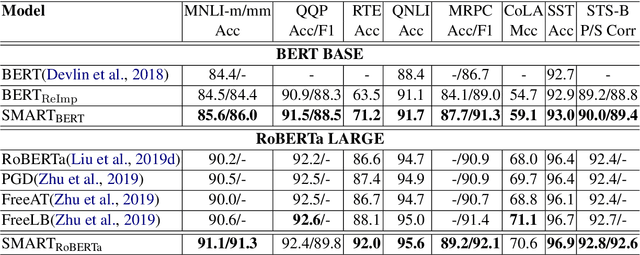
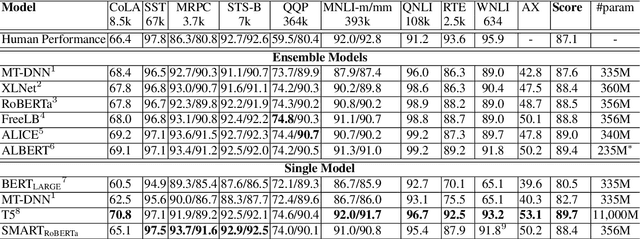
Transfer learning has fundamentally changed the landscape of natural language processing (NLP) research. Many existing state-of-the-art models are first pre-trained on a large text corpus and then fine-tuned on downstream tasks. However, due to limited data resources from downstream tasks and the extremely large capacity of pre-trained models, aggressive fine-tuning often causes the adapted model to overfit the data of downstream tasks and forget the knowledge of the pre-trained model. To address the above issue in a more principled manner, we propose a new computational framework for robust and efficient fine-tuning for pre-trained language models. Specifically, our proposed framework contains two important ingredients: 1. Smoothness-inducing regularization, which effectively manages the capacity of the model; 2. Bregman proximal point optimization, which is a class of trust-region methods and can prevent knowledge forgetting. Our experiments demonstrate that our proposed method achieves the state-of-the-art performance on multiple NLP benchmarks.
Unsupervised Common Question Generation from Multiple Documents using Reinforced Contrastive Coordinator
Nov 08, 2019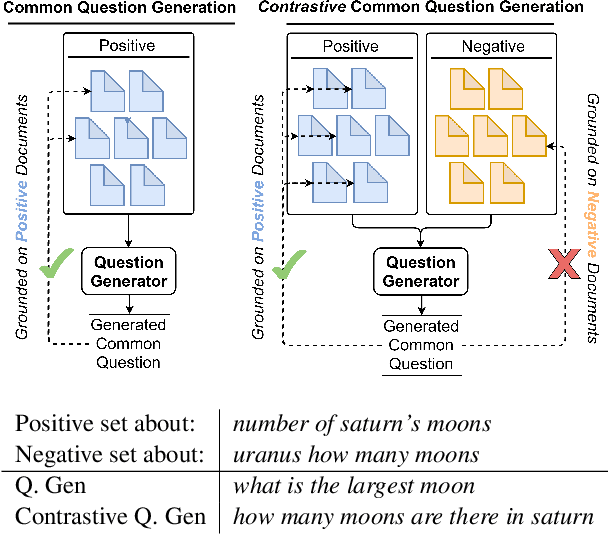
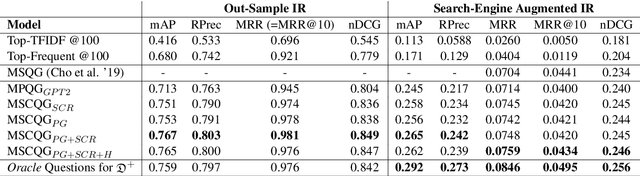
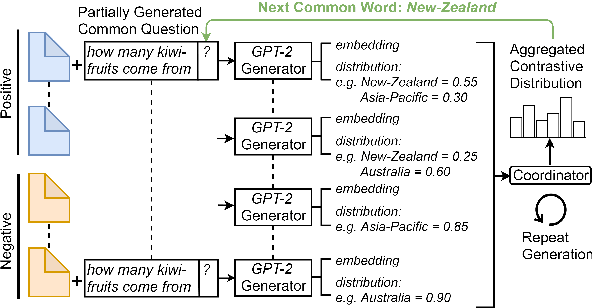
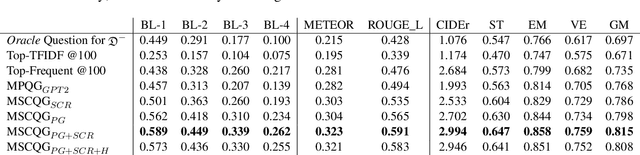
Web search engines today return a ranked list of document links in response to a user's query. However, when a user query is vague, the resultant documents span multiple subtopics. In such a scenario, it would be helpful if the search engine provided clarification options to the user's initial query in a way that each clarification option is closely related to the documents in one subtopic and is far away from the documents in all other subtopics. Motivated by this scenario, we address the task of contrastive common question generation where given a "positive" set of documents and a "negative" set of documents, we generate a question that is closely related to the "positive" set and is far away from the "negative" set. We propose Multi-Source Coordinated Question Generator (MSCQG), a novel coordinator model trained using reinforcement learning to optimize a reward based on document-question ranker score. We also develop an effective auxiliary objective, named Set-induced Contrastive Regularization (SCR) that draws the coordinator's generation behavior more closely toward "positive" documents and away from "negative" documents. We show that our model significantly outperforms strong retrieval baselines as well as a baseline model developed for a similar task, as measured by various metrics.
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
Nov 01, 2019
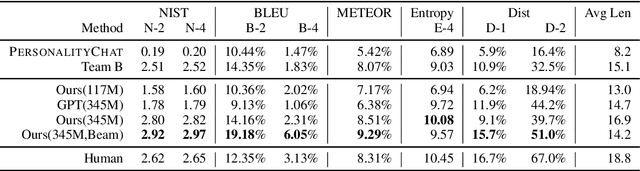

We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response generation and the development of more intelligent open-domain dialogue systems.
HUBERT Untangles BERT to Improve Transfer across NLP Tasks
Oct 25, 2019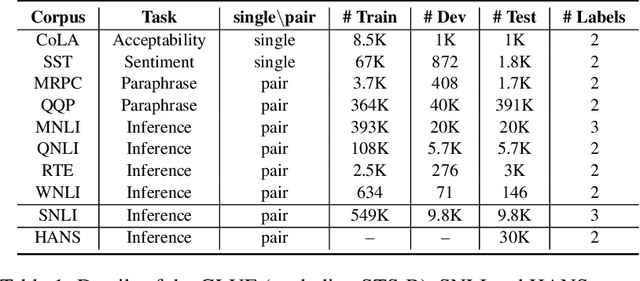
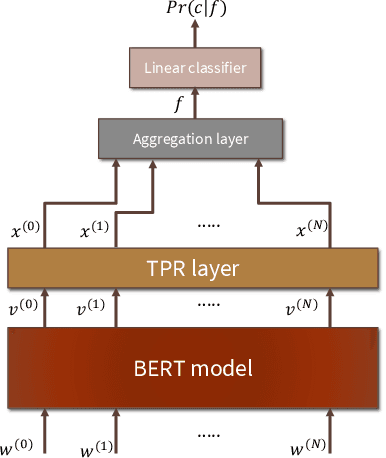
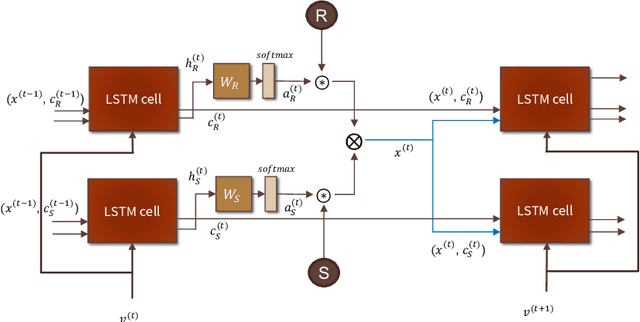

We introduce HUBERT which combines the structured-representational power of Tensor-Product Representations (TPRs) and BERT, a pre-trained bidirectional Transformer language model. We show that there is shared structure between different NLP datasets that HUBERT, but not BERT, is able to learn and leverage. We validate the effectiveness of our model on the GLUE benchmark and HANS dataset. Our experiment results show that untangling data-specific semantics from general language structure is key for better transfer among NLP tasks.
Enhancing the Transformer with Explicit Relational Encoding for Math Problem Solving
Oct 15, 2019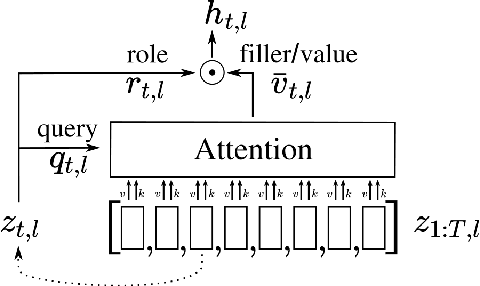
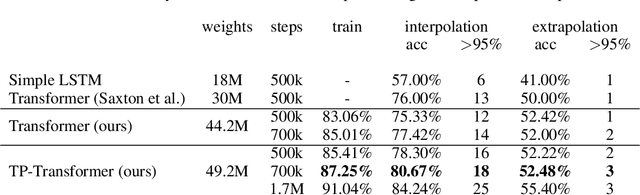
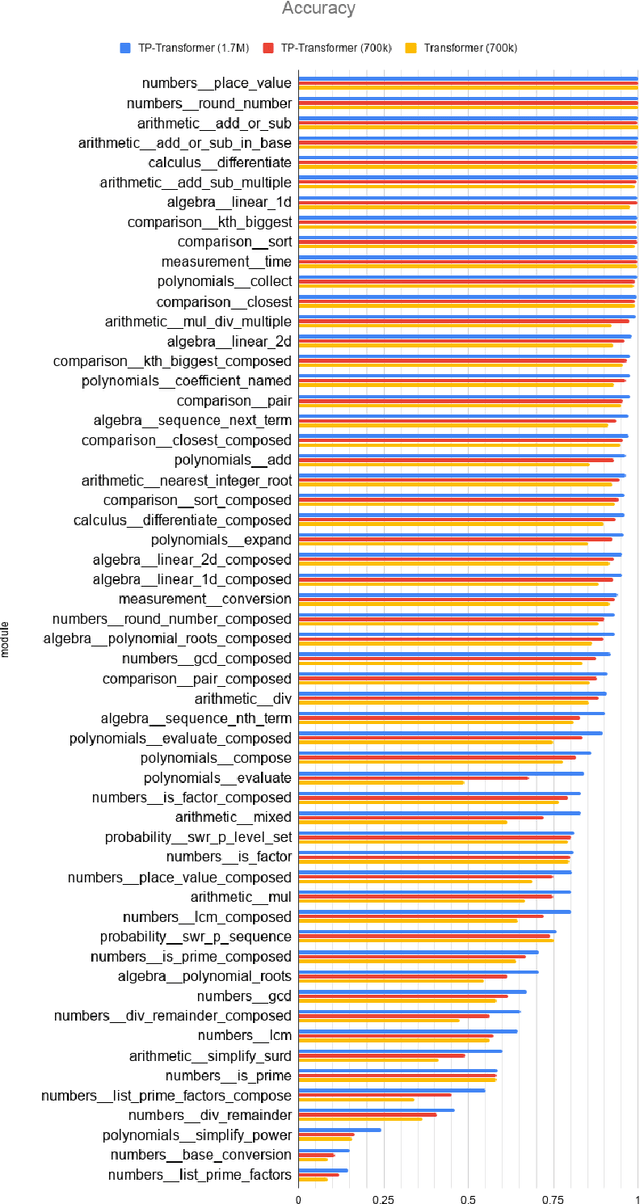

We incorporate Tensor-Product Representations within the Transformer in order to better support the explicit representation of relation structure. Our Tensor-Product Transformer (TP-Transformer) sets a new state of the art on the recently-introduced Mathematics Dataset containing 56 categories of free-form math word-problems. The essential component of the model is a novel attention mechanism, called TP-Attention, which explicitly encodes the relations between each Transformer cell and the other cells from which values have been retrieved by attention. TP-Attention goes beyond linear combination of retrieved values, strengthening representation-building and resolving ambiguities introduced by multiple layers of standard attention. The TP-Transformer's attention maps give better insights into how it is capable of solving the Mathematics Dataset's challenging problems. Pretrained models and code will be made available after publication.
Natural- to formal-language generation using Tensor Product Representations
Oct 05, 2019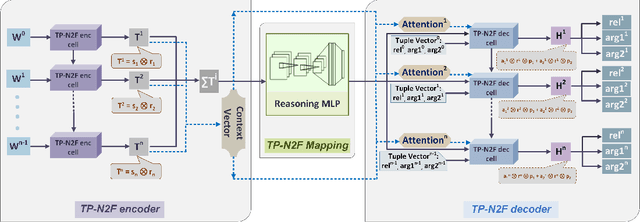

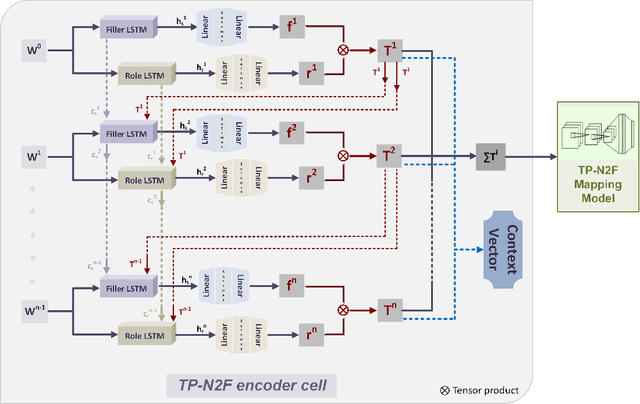
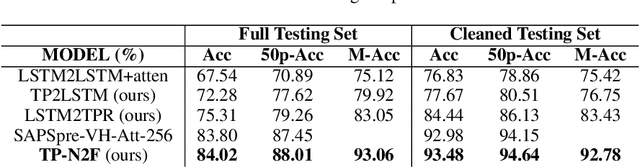
Generating formal-language represented by relational tuples, such as Lisp programs or mathematical expressions, from a natural-language input is an extremely challenging task because it requires to explicitly capture discrete symbolic structural information from the input to generate the output. Most state-of-the-art neural sequence models do not explicitly capture such structure information, and thus do not perform well on these tasks. In this paper, we propose a new encoder-decoder model based on Tensor Product Representations (TPRs) for Natural- to Formal-language generation, called TP-N2F. The encoder of TP-N2F employs TPR 'binding' to encode natural-language symbolic structure in vector space and the decoder uses TPR 'unbinding' to generate a sequence of relational tuples, each consisting of a relation (or operation) and a number of arguments, in symbolic space. TP-N2F considerably outperforms LSTM-based Seq2Seq models, creating a new state of the art results on two benchmarks: the MathQA dataset for math problem solving, and the AlgoList dataset for program synthesis. Ablation studies show that improvements are mainly attributed to the use of TPRs in both the encoder and decoder to explicitly capture relational structure information for symbolic reasoning.
Unified Vision-Language Pre-Training for Image Captioning and VQA
Oct 03, 2019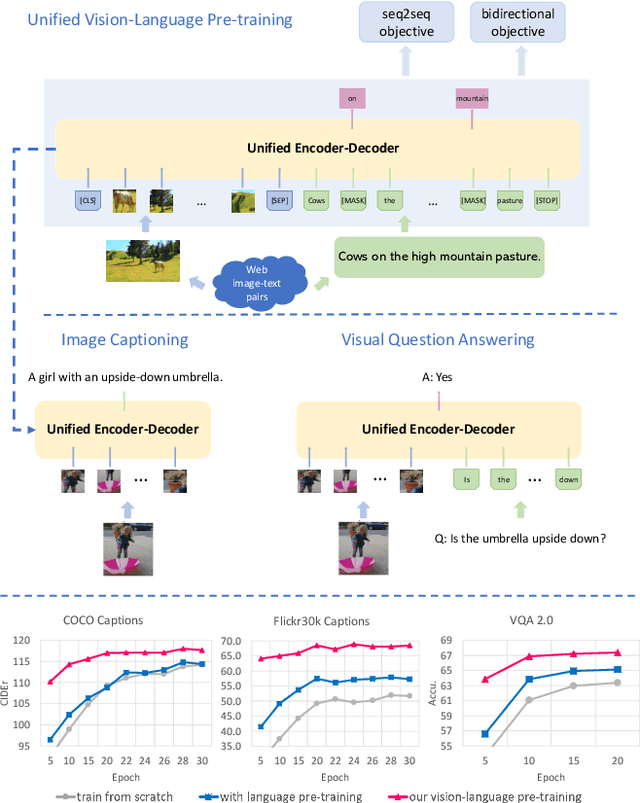
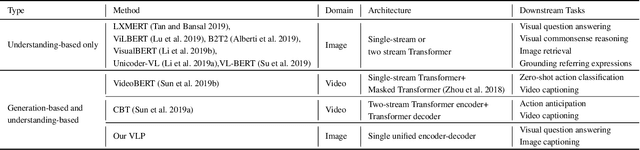
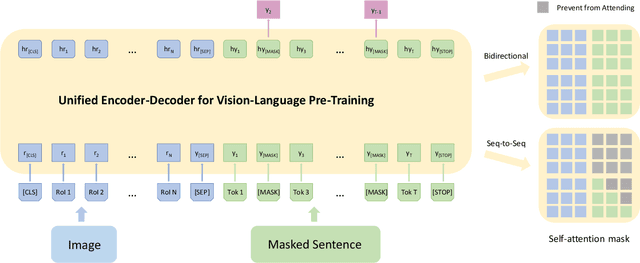
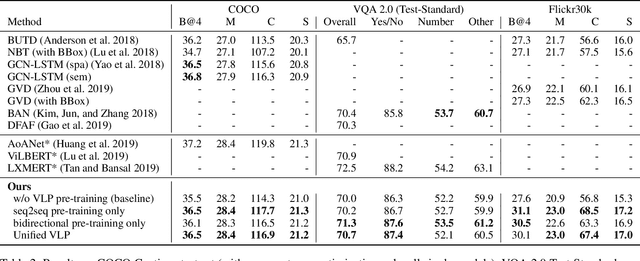
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0. The code and the pre-trained models are available at https://github.com/LuoweiZhou/VLP.
Learning Visual Relation Priors for Image-Text Matching and Image Captioning with Neural Scene Graph Generators
Sep 22, 2019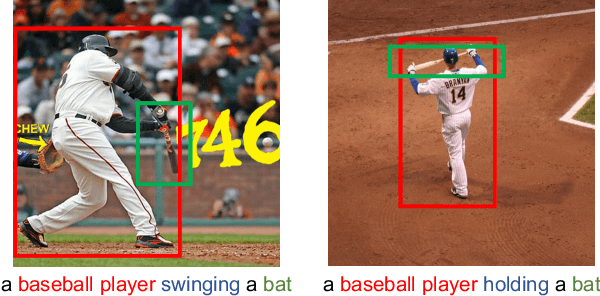
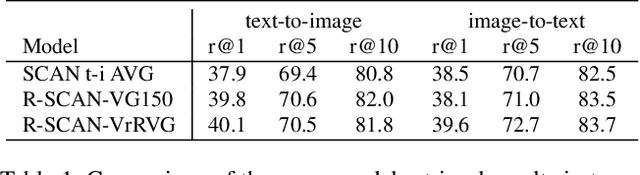
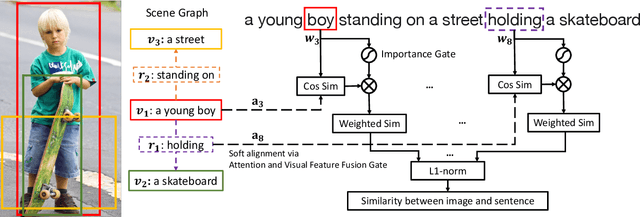
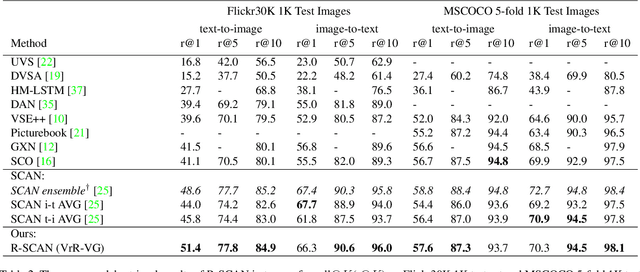
Grounding language to visual relations is critical to various language-and-vision applications. In this work, we tackle two fundamental language-and-vision tasks: image-text matching and image captioning, and demonstrate that neural scene graph generators can learn effective visual relation features to facilitate grounding language to visual relations and subsequently improve the two end applications. By combining relation features with the state-of-the-art models, our experiments show significant improvement on the standard Flickr30K and MSCOCO benchmarks. Our experimental results and analysis show that relation features improve downstream models' capability of capturing visual relations in end vision-and-language applications. We also demonstrate the importance of learning scene graph generators with visually relevant relations to the effectiveness of relation features.
Implicit Deep Latent Variable Models for Text Generation
Sep 18, 2019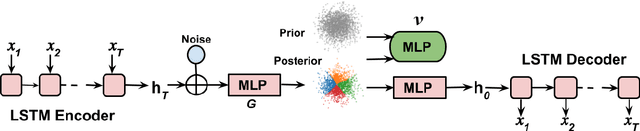
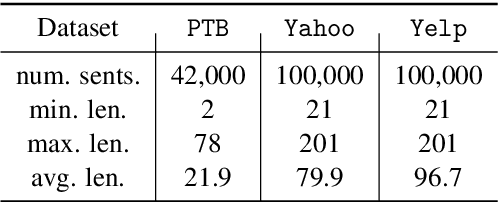
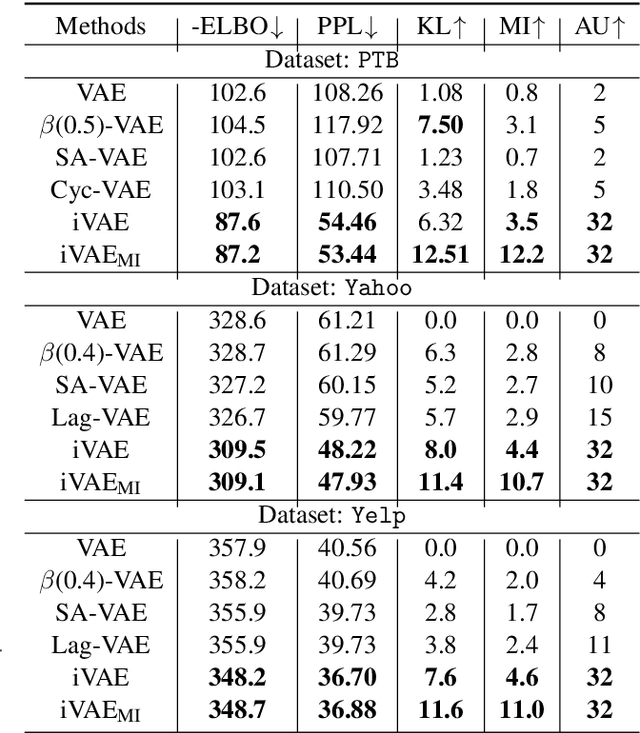
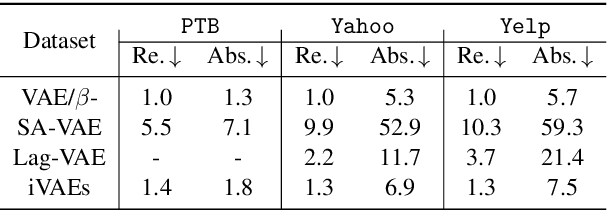
Deep latent variable models (LVM) such as variational auto-encoder (VAE) have recently played an important role in text generation. One key factor is the exploitation of smooth latent structures to guide the generation. However, the representation power of VAEs is limited due to two reasons: (1) the Gaussian assumption is often made on the variational posteriors; and meanwhile (2) a notorious "posterior collapse" issue occurs. In this paper, we advocate sample-based representations of variational distributions for natural language, leading to implicit latent features, which can provide flexible representation power compared with Gaussian-based posteriors. We further develop an LVM to directly match the aggregated posterior to the prior. It can be viewed as a natural extension of VAEs with a regularization of maximizing mutual information, mitigating the "posterior collapse" issue. We demonstrate the effectiveness and versatility of our models in various text generation scenarios, including language modeling, unaligned style transfer, and dialog response generation. The source code to reproduce our experimental results is available on GitHub.
What Makes A Good Story? Designing Composite Rewards for Visual Storytelling
Sep 11, 2019
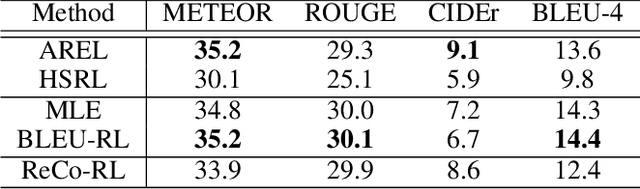
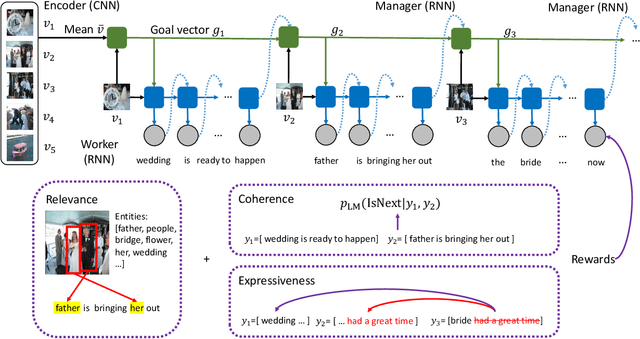

Previous storytelling approaches mostly focused on optimizing traditional metrics such as BLEU, ROUGE and CIDEr. In this paper, we re-examine this problem from a different angle, by looking deep into what defines a realistically-natural and topically-coherent story. To this end, we propose three assessment criteria: relevance, coherence and expressiveness, which we observe through empirical analysis could constitute a "high-quality" story to the human eye. Following this quality guideline, we propose a reinforcement learning framework, ReCo-RL, with reward functions designed to capture the essence of these quality criteria. Experiments on the Visual Storytelling Dataset (VIST) with both automatic and human evaluations demonstrate that our ReCo-RL model achieves better performance than state-of-the-art baselines on both traditional metrics and the proposed new criteria.