 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing
Paper and Code
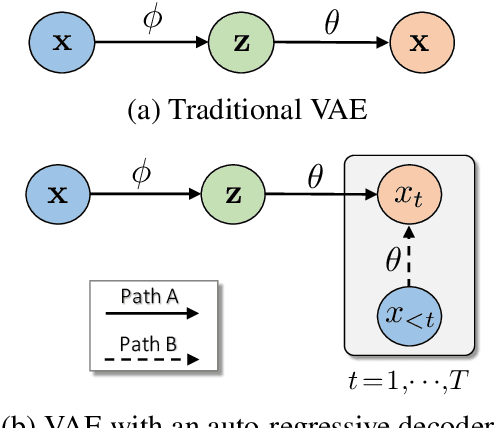
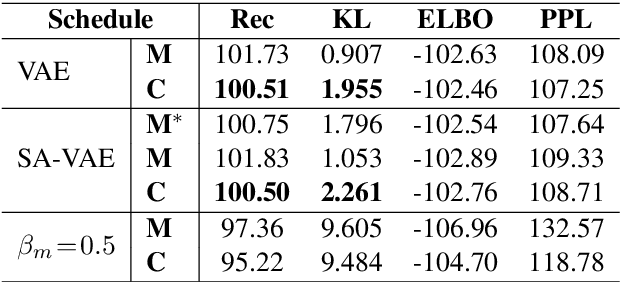
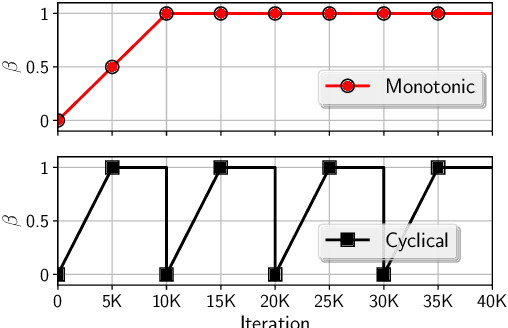

Variational autoencoders (VAEs) with an auto-regressive decoder have been applied for many natural language processing (NLP) tasks. The VAE objective consists of two terms, (i) reconstruction and (ii) KL regularization, balanced by a weighting hyper-parameter \beta. One notorious training difficulty is that the KL term tends to vanish. In this paper we study scheduling schemes for \beta, and show that KL vanishing is caused by the lack of good latent codes in training the decoder at the beginning of optimization. To remedy this, we propose a cyclical annealing schedule, which repeats the process of increasing \beta multiple times. This new procedure allows the progressive learning of more meaningful latent codes, by leveraging the informative representations of previous cycles as warm re-starts. The effectiveness of cyclical annealing is validated on a broad range of NLP tasks, including language modeling, dialog response generation and unsupervised language pre-training.