 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaMARP: An Adaptive Multi-Agent Interaction Framework for General Immersive Role-Playing
Jan 16, 2026LLM role-playing aims to portray arbitrary characters in interactive narratives, yet existing systems often suffer from limited immersion and adaptability. They typically under-model dynamic environmental information and assume largely static scenes and casts, offering insufficient support for multi-character orchestration, scene transitions, and on-the-fly character introduction. We propose an adaptive multi-agent role-playing framework, AdaMARP, featuring an immersive message format that interleaves [Thought], (Action), <Environment>, and Speech, together with an explicit Scene Manager that governs role-playing through discrete actions (init_scene, pick_speaker, switch_scene, add_role, end) accompanied by rationales. To train these capabilities, we construct AdaRPSet for the Actor Model and AdaSMSet for supervising orchestration decisions, and introduce AdaptiveBench for trajectory-level evaluation. Experiments across multiple backbones and model scales demonstrate consistent improvements: AdaRPSet enhances character consistency, environment grounding, and narrative coherence, with an 8B actor outperforming several commercial LLMs, while AdaSMSet enables smoother scene transitions and more natural role introductions, surpassing Claude Sonnet 4.5 using only a 14B LLM.
PID-Guided Partial Alignment for Multimodal Decentralized Federated Learning
Jan 15, 2026Multimodal decentralized federated learning (DFL) is challenging because agents differ in available modalities and model architectures, yet must collaborate over peer-to-peer (P2P) networks without a central coordinator. Standard multimodal pipelines learn a single shared embedding across all modalities. In DFL, such a monolithic representation induces gradient misalignment between uni- and multimodal agents; as a result, it suppresses heterogeneous sharing and cross-modal interaction. We present PARSE, a multimodal DFL framework that operationalizes partial information decomposition (PID) in a server-free setting. Each agent performs feature fission to factorize its latent representation into redundant, unique, and synergistic slices. P2P knowledge sharing among heterogeneous agents is enabled by slice-level partial alignment: only semantically shareable branches are exchanged among agents that possess the corresponding modality. By removing the need for central coordination and gradient surgery, PARSE resolves uni-/multimodal gradient conflicts, thereby overcoming the multimodal DFL dilemma while remaining compatible with standard DFL constraints. Across benchmarks and agent mixes, PARSE yields consistent gains over task-, modality-, and hybrid-sharing DFL baselines. Ablations on fusion operators and split ratios, together with qualitative visualizations, further demonstrate the efficiency and robustness of the proposed design.
Deep Incomplete Multi-View Clustering via Hierarchical Imputation and Alignment
Jan 14, 2026Incomplete multi-view clustering (IMVC) aims to discover shared cluster structures from multi-view data with partial observations. The core challenges lie in accurately imputing missing views without introducing bias, while maintaining semantic consistency across views and compactness within clusters. To address these challenges, we propose DIMVC-HIA, a novel deep IMVC framework that integrates hierarchical imputation and alignment with four key components: (1) view-specific autoencoders for latent feature extraction, coupled with a view-shared clustering predictor to produce soft cluster assignments; (2) a hierarchical imputation module that first estimates missing cluster assignments based on cross-view contrastive similarity, and then reconstructs missing features using intra-view, intra-cluster statistics; (3) an energy-based semantic alignment module, which promotes intra-cluster compactness by minimizing energy variance around low-energy cluster anchors; and (4) a contrastive assignment alignment module, which enhances cross-view consistency and encourages confident, well-separated cluster predictions. Experiments on benchmarks demonstrate that our framework achieves superior performance under varying levels of missingness.
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Jan 07, 2026Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
Disco-RAG: Discourse-Aware Retrieval-Augmented Generation
Jan 07, 2026Retrieval-Augmented Generation (RAG) has emerged as an important means of enhancing the performance of large language models (LLMs) in knowledge-intensive tasks. However, most existing RAG strategies treat retrieved passages in a flat and unstructured way, which prevents the model from capturing structural cues and constrains its ability to synthesize knowledge from dispersed evidence across documents. To overcome these limitations, we propose Disco-RAG, a discourse-aware framework that explicitly injects discourse signals into the generation process. Our method constructs intra-chunk discourse trees to capture local hierarchies and builds inter-chunk rhetorical graphs to model cross-passage coherence. These structures are jointly integrated into a planning blueprint that conditions the generation. Experiments on question answering and long-document summarization benchmarks show the efficacy of our approach. Disco-RAG achieves state-of-the-art results on the benchmarks without fine-tuning. These findings underscore the important role of discourse structure in advancing RAG systems.
Batch-of-Thought: Cross-Instance Learning for Enhanced LLM Reasoning
Jan 06, 2026Current Large Language Model reasoning systems process queries independently, discarding valuable cross-instance signals such as shared reasoning patterns and consistency constraints. We introduce Batch-of-Thought (BoT), a training-free method that processes related queries jointly to enable cross-instance learning. By performing comparative analysis across batches, BoT identifies high-quality reasoning templates, detects errors through consistency checks, and amortizes computational costs. We instantiate BoT within a multi-agent reflection architecture (BoT-R), where a Reflector performs joint evaluation to unlock mutual information gain unavailable in isolated processing. Experiments across three model families and six benchmarks demonstrate that BoT-R consistently improves accuracy and confidence calibration while reducing inference costs by up to 61%. Our theoretical and experimental analysis reveals when and why batch-aware reasoning benefits LLM systems.
Evaluating the Diagnostic Classification Ability of Multimodal Large Language Models: Insights from the Osteoarthritis Initiative
Jan 05, 2026Multimodal large language models (MLLMs) show promising performance on medical visual question answering (VQA) and report generation, but these generation and explanation abilities do not reliably transfer to disease-specific classification. We evaluated MLLM architectures on knee osteoarthritis (OA) radiograph classification, which remains underrepresented in existing medical MLLM benchmarks, even though knee OA affects an estimated 300 to 400 million people worldwide. Through systematic ablation studies manipulating the vision encoder, the connector, and the large language model (LLM) across diverse training strategies, we measured each component's contribution to diagnostic accuracy. In our classification task, a trained vision encoder alone could outperform full MLLM pipelines in classification accuracy and fine-tuning the LLM provided no meaningful improvement over prompt-based guidance. And LoRA fine-tuning on a small, class-balanced dataset (500 images) gave better results than training on a much larger but class-imbalanced set (5,778 images), indicating that data balance and quality can matter more than raw scale for this task. These findings suggest that for domain-specific medical classification, LLMs are more effective as interpreters and report generators rather than as primary classifiers. Therefore, the MLLM architecture appears less suitable for medical image diagnostic classification tasks that demand high certainty. We recommend prioritizing vision encoder optimization and careful dataset curation when developing clinically applicable systems.
JParc: Joint cortical surface parcellation with registration
Dec 27, 2025Cortical surface parcellation is a fundamental task in both basic neuroscience research and clinical applications, enabling more accurate mapping of brain regions. Model-based and learning-based approaches for automated parcellation alleviate the need for manual labeling. Despite the advancement in parcellation performance, learning-based methods shift away from registration and atlas propagation without exploring the reason for the improvement compared to traditional methods. In this study, we present JParc, a joint cortical registration and parcellation framework, that outperforms existing state-of-the-art parcellation methods. In rigorous experiments, we demonstrate that the enhanced performance of JParc is primarily attributable to accurate cortical registration and a learned parcellation atlas. By leveraging a shallow subnetwork to fine-tune the propagated atlas labels, JParc achieves a Dice score greater than 90% on the Mindboggle dataset, using only basic geometric features (sulcal depth, curvature) that describe cortical folding patterns. The superior accuracy of JParc can significantly increase the statistical power in brain mapping studies as well as support applications in surgical planning and many other downstream neuroscientific and clinical tasks.
HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
Dec 17, 20253D Scene Graphs (3DSGs) constitute a powerful representation of the physical world, distinguished by their abilities to explicitly model the complex spatial, semantic, and functional relationships between entities, rendering a foundational understanding that enables agents to interact intelligently with their environment and execute versatile behaviors. Embodied navigation, as a crucial component of such capabilities, leverages the compact and expressive nature of 3DSGs to enable long-horizon reasoning and planning in complex, large-scale environments. However, prior works rely on a static-world assumption, defining traversable space solely based on static spatial layouts and thereby treating interactable obstacles as non-traversable. This fundamental limitation severely undermines their effectiveness in real-world scenarios, leading to limited reachability, low efficiency, and inferior extensibility. To address these issues, we propose HERO, a novel framework for constructing Hierarchical Traversable 3DSGs, that redefines traversability by modeling operable obstacles as pathways, capturing their physical interactivity, functional semantics, and the scene's relational hierarchy. The results show that, relative to its baseline, HERO reduces PL by 35.1% in partially obstructed environments and increases SR by 79.4% in fully obstructed ones, demonstrating substantially higher efficiency and reachability.
TAO-Net: Two-stage Adaptive OOD Classification Network for Fine-grained Encrypted Traffic Classification
Dec 11, 2025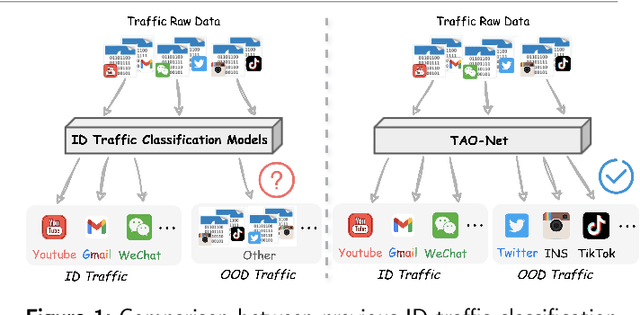

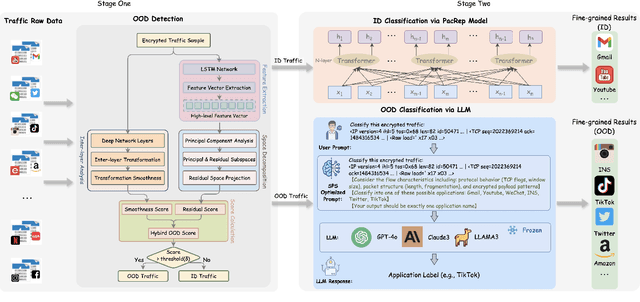
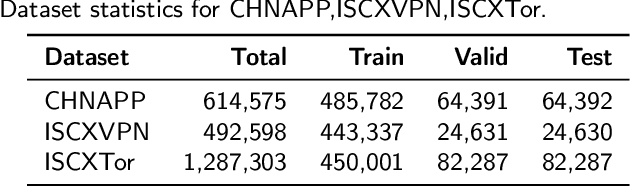
Encrypted traffic classification aims to identify applications or services by analyzing network traffic data. One of the critical challenges is the continuous emergence of new applications, which generates Out-of-Distribution (OOD) traffic patterns that deviate from known categories and are not well represented by predefined models. Current approaches rely on predefined categories, which limits their effectiveness in handling unknown traffic types. Although some methods mitigate this limitation by simply classifying unknown traffic into a single "Other" category, they fail to make a fine-grained classification. In this paper, we propose a Two-stage Adaptive OOD classification Network (TAO-Net) that achieves accurate classification for both In-Distribution (ID) and OOD encrypted traffic. The method incorporates an innovative two-stage design: the first stage employs a hybrid OOD detection mechanism that integrates transformer-based inter-layer transformation smoothness and feature analysis to effectively distinguish between ID and OOD traffic, while the second stage leverages large language models with a novel semantic-enhanced prompt strategy to transform OOD traffic classification into a generation task, enabling flexible fine-grained classification without relying on predefined labels. Experiments on three datasets demonstrate that TAO-Net achieves 96.81-97.70% macro-precision and 96.77-97.68% macro-F1, outperforming previous methods that only reach 44.73-86.30% macro-precision, particularly in identifying emerging network applications.