 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Evidence Highlighting for Frozen LLMs
Apr 24, 2026Large Language Models (LLMs) can reason well, yet often miss decisive evidence when it is buried in long, noisy contexts. We introduce HiLight, an Evidence Emphasis framework that decouples evidence selection from reasoning for frozen LLM solvers. HiLight avoids compressing or rewriting the input, which can discard or distort evidence, by training a lightweight Emphasis Actor to insert minimal highlight tags around pivotal spans in the unaltered context. A frozen Solver then performs downstream reasoning on the emphasized input. We cast highlighting as a weakly supervised decision-making problem and optimize the Actor with reinforcement learning using only the Solver's task reward, requiring no evidence labels and no access to or modification of the Solver. Across sequential recommendation and long-context question answering, HiLight consistently improves performance over strong prompt-based and automated prompt-optimization baselines. The learned emphasis policy transfers zero-shot to both smaller and larger unseen Solver families, including an API-based Solver, suggesting that the Actor captures genuine, reusable evidence structure rather than overfitting to a single backbone.
PID-Guided Partial Alignment for Multimodal Decentralized Federated Learning
Jan 15, 2026Multimodal decentralized federated learning (DFL) is challenging because agents differ in available modalities and model architectures, yet must collaborate over peer-to-peer (P2P) networks without a central coordinator. Standard multimodal pipelines learn a single shared embedding across all modalities. In DFL, such a monolithic representation induces gradient misalignment between uni- and multimodal agents; as a result, it suppresses heterogeneous sharing and cross-modal interaction. We present PARSE, a multimodal DFL framework that operationalizes partial information decomposition (PID) in a server-free setting. Each agent performs feature fission to factorize its latent representation into redundant, unique, and synergistic slices. P2P knowledge sharing among heterogeneous agents is enabled by slice-level partial alignment: only semantically shareable branches are exchanged among agents that possess the corresponding modality. By removing the need for central coordination and gradient surgery, PARSE resolves uni-/multimodal gradient conflicts, thereby overcoming the multimodal DFL dilemma while remaining compatible with standard DFL constraints. Across benchmarks and agent mixes, PARSE yields consistent gains over task-, modality-, and hybrid-sharing DFL baselines. Ablations on fusion operators and split ratios, together with qualitative visualizations, further demonstrate the efficiency and robustness of the proposed design.
Uncertainty Minimization for Personalized Federated Semi-Supervised Learning
May 05, 2022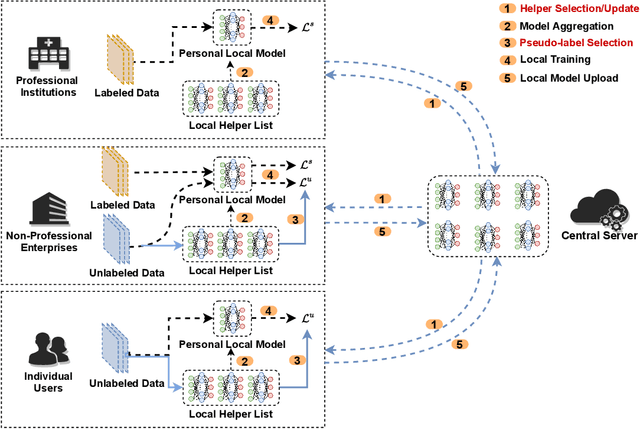
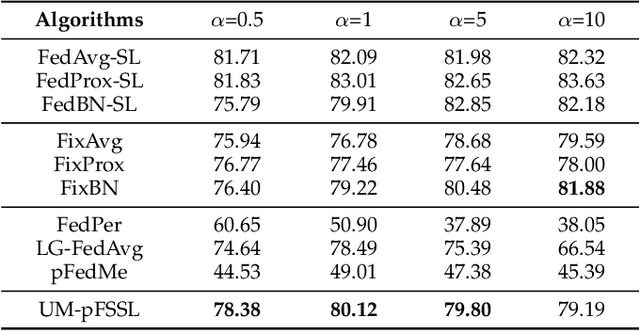
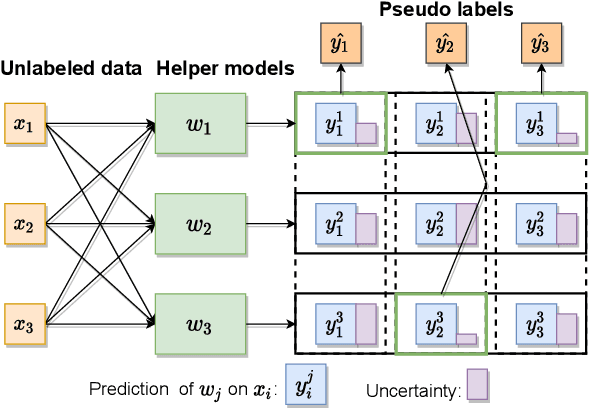
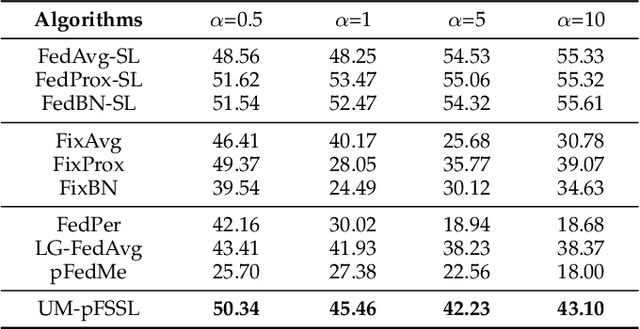
Since federated learning (FL) has been introduced as a decentralized learning technique with privacy preservation, statistical heterogeneity of distributed data stays the main obstacle to achieve robust performance and stable convergence in FL applications. Model personalization methods have been studied to overcome this problem. However, existing approaches are mainly under the prerequisite of fully labeled data, which is unrealistic in practice due to the requirement of expertise. The primary issue caused by partial-labeled condition is that, clients with deficient labeled data can suffer from unfair performance gain because they lack adequate insights of local distribution to customize the global model. To tackle this problem, 1) we propose a novel personalized semi-supervised learning paradigm which allows partial-labeled or unlabeled clients to seek labeling assistance from data-related clients (helper agents), thus to enhance their perception of local data; 2) based on this paradigm, we design an uncertainty-based data-relation metric to ensure that selected helpers can provide trustworthy pseudo labels instead of misleading the local training; 3) to mitigate the network overload introduced by helper searching, we further develop a helper selection protocol to achieve efficient communication with negligible performance sacrifice. Experiments show that our proposed method can obtain superior performance and more stable convergence than other related works with partial labeled data, especially in highly heterogeneous setting.