 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePepALD: Macrocyclic Peptide Generation via Autoregressive Latent Diffusion
Jun 12, 2026Macrocyclic peptides are promising therapeutic candidates for intracellular targets, but their design requires simultaneous control over non-natural monomer chemistry, ring topology, membrane permeability, and target binding. Existing SMILES- or HELM-string generative models either operate in long atom-level sequence spaces or treat monomers as symbolic tokens with limited chemical grounding. We introduce PepALD, an Autoregressive Latent Diffusion (ALD) foundation model for \textit{de novo} macrocyclic peptide generation. The model represents HELM monomers with structured chemical embeddings, generates each residue through context-conditioned diffusion in chemically informed latent space, predicts R-group-aware ring closures during autoregressive generation, and aligns the denoiser to affinity rewards using winner-protected diffusion-adapted preference optimization. In silico experiments demonstrate PepALD's generation quality and reward-optimization performance against representative peptide generation baselines.
M2I2HA: Multi-modal Object Detection Based on Intra- and Inter-Modal Hypergraph Attention
Jan 24, 2026Recent advances in multi-modal detection have significantly improved detection accuracy in challenging environments (e.g., low light, overexposure). By integrating RGB with modalities such as thermal and depth, multi-modal fusion increases data redundancy and system robustness. However, significant challenges remain in effectively extracting task-relevant information both within and across modalities, as well as in achieving precise cross-modal alignment. While CNNs excel at feature extraction, they are limited by constrained receptive fields, strong inductive biases, and difficulty in capturing long-range dependencies. Transformer-based models offer global context but suffer from quadratic computational complexity and are confined to pairwise correlation modeling. Mamba and other State Space Models (SSMs), on the other hand, are hindered by their sequential scanning mechanism, which flattens 2D spatial structures into 1D sequences, disrupting topological relationships and limiting the modeling of complex higher-order dependencies. To address these issues, we propose a multi-modal perception network based on hypergraph theory called M2I2HA. Our architecture includes an Intra-Hypergraph Enhancement module to capture global many-to-many high-order relationships within each modality, and an Inter-Hypergraph Fusion module to align, enhance, and fuse cross-modal features by bridging configuration and spatial gaps between data sources. We further introduce a M2-FullPAD module to enable adaptive multi-level fusion of multi-modal enhanced features within the network, meanwhile enhancing data distribution and flow across the architecture. Extensive object detection experiments on multiple public datasets against baselines demonstrate that M2I2HA achieves state-of-the-art performance in multi-modal object detection tasks.
M2I2HA: A Multi-modal Object Detection Method Based on Intra- and Inter-Modal Hypergraph Attention
Jan 21, 2026Recent advances in multi-modal detection have significantly improved detection accuracy in challenging environments (e.g., low light, overexposure). By integrating RGB with modalities such as thermal and depth, multi-modal fusion increases data redundancy and system robustness. However, significant challenges remain in effectively extracting task-relevant information both within and across modalities, as well as in achieving precise cross-modal alignment. While CNNs excel at feature extraction, they are limited by constrained receptive fields, strong inductive biases, and difficulty in capturing long-range dependencies. Transformer-based models offer global context but suffer from quadratic computational complexity and are confined to pairwise correlation modeling. Mamba and other State Space Models (SSMs), on the other hand, are hindered by their sequential scanning mechanism, which flattens 2D spatial structures into 1D sequences, disrupting topological relationships and limiting the modeling of complex higher-order dependencies. To address these issues, we propose a multi-modal perception network based on hypergraph theory called M2I2HA. Our architecture includes an Intra-Hypergraph Enhancement module to capture global many-to-many high-order relationships within each modality, and an Inter-Hypergraph Fusion module to align, enhance, and fuse cross-modal features by bridging configuration and spatial gaps between data sources. We further introduce a M2-FullPAD module to enable adaptive multi-level fusion of multi-modal enhanced features within the network, meanwhile enhancing data distribution and flow across the architecture. Extensive object detection experiments on multiple public datasets against baselines demonstrate that M2I2HA achieves state-of-the-art performance in multi-modal object detection tasks.
TAO-Net: Two-stage Adaptive OOD Classification Network for Fine-grained Encrypted Traffic Classification
Dec 11, 2025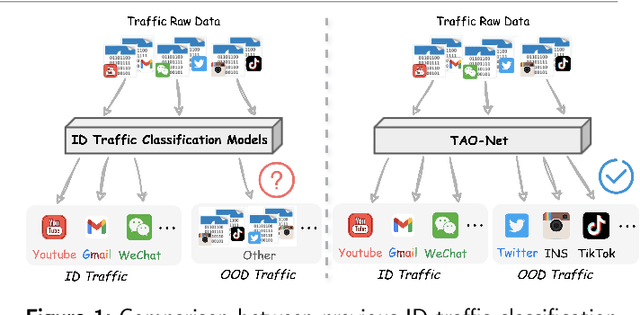

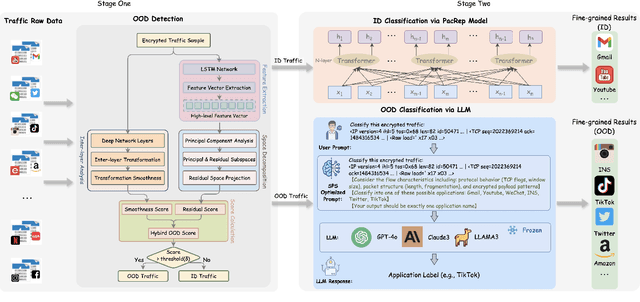
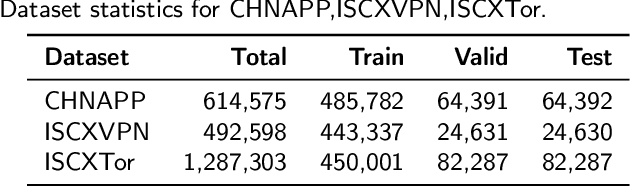
Encrypted traffic classification aims to identify applications or services by analyzing network traffic data. One of the critical challenges is the continuous emergence of new applications, which generates Out-of-Distribution (OOD) traffic patterns that deviate from known categories and are not well represented by predefined models. Current approaches rely on predefined categories, which limits their effectiveness in handling unknown traffic types. Although some methods mitigate this limitation by simply classifying unknown traffic into a single "Other" category, they fail to make a fine-grained classification. In this paper, we propose a Two-stage Adaptive OOD classification Network (TAO-Net) that achieves accurate classification for both In-Distribution (ID) and OOD encrypted traffic. The method incorporates an innovative two-stage design: the first stage employs a hybrid OOD detection mechanism that integrates transformer-based inter-layer transformation smoothness and feature analysis to effectively distinguish between ID and OOD traffic, while the second stage leverages large language models with a novel semantic-enhanced prompt strategy to transform OOD traffic classification into a generation task, enabling flexible fine-grained classification without relying on predefined labels. Experiments on three datasets demonstrate that TAO-Net achieves 96.81-97.70% macro-precision and 96.77-97.68% macro-F1, outperforming previous methods that only reach 44.73-86.30% macro-precision, particularly in identifying emerging network applications.
Design and Control of a Perching Drone Inspired by the Prey-Capturing Mechanism of Venus Flytrap
Sep 16, 2025
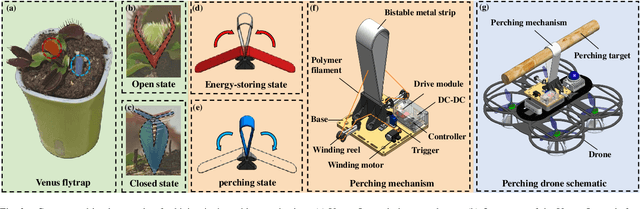
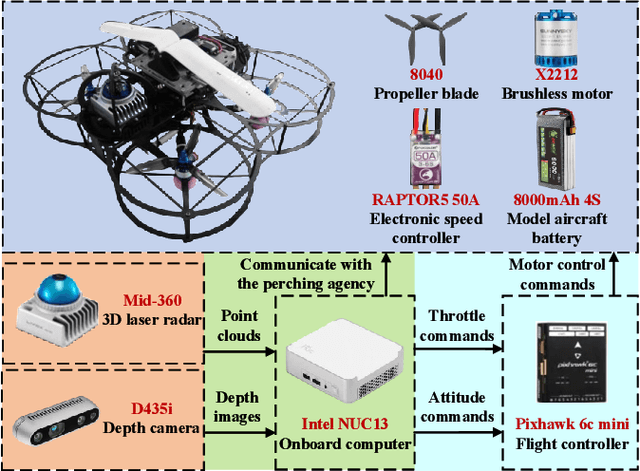
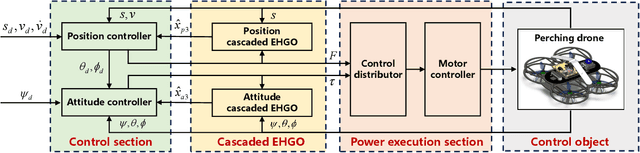
The endurance and energy efficiency of drones remain critical challenges in their design and operation. To extend mission duration, numerous studies explored perching mechanisms that enable drones to conserve energy by temporarily suspending flight. This paper presents a new perching drone that utilizes an active flexible perching mechanism inspired by the rapid predation mechanism of the Venus flytrap, achieving perching in less than 100 ms. The proposed system is designed for high-speed adaptability to the perching targets. The overall drone design is outlined, followed by the development and validation of the biomimetic perching structure. To enhance the system stability, a cascade extended high-gain observer (EHGO) based control method is developed, which can estimate and compensate for the external disturbance in real time. The experimental results demonstrate the adaptability of the perching structure and the superiority of the cascaded EHGO in resisting wind and perching disturbances.
FDC-Net: Rethinking the association between EEG artifact removal and multi-dimensional affective computing
Aug 07, 2025



Electroencephalogram (EEG)-based emotion recognition holds significant value in affective computing and brain-computer interfaces. However, in practical applications, EEG recordings are susceptible to the effects of various physiological artifacts. Current approaches typically treat denoising and emotion recognition as independent tasks using cascaded architectures, which not only leads to error accumulation, but also fails to exploit potential synergies between these tasks. Moreover, conventional EEG-based emotion recognition models often rely on the idealized assumption of "perfectly denoised data", lacking a systematic design for noise robustness. To address these challenges, a novel framework that deeply couples denoising and emotion recognition tasks is proposed for end-to-end noise-robust emotion recognition, termed as Feedback-Driven Collaborative Network for Denoising-Classification Nexus (FDC-Net). Our primary innovation lies in establishing a dynamic collaborative mechanism between artifact removal and emotion recognition through: (1) bidirectional gradient propagation with joint optimization strategies; (2) a gated attention mechanism integrated with frequency-adaptive Transformer using learnable band-position encoding. Two most popular EEG-based emotion datasets (DEAP and DREAMER) with multi-dimensional emotional labels were employed to compare the artifact removal and emotion recognition performance between ASLSL and nine state-of-the-art methods. In terms of the denoising task, FDC-Net obtains a maximum correlation coefficient (CC) value of 96.30% on DEAP and a maximum CC value of 90.31% on DREAMER. In terms of the emotion recognition task under physiological artifact interference, FDC-Net achieves emotion recognition accuracies of 82.3+7.1% on DEAP and 88.1+0.8% on DREAMER.
ADSEL: Adaptive dual self-expression learning for EEG feature selection via incomplete multi-dimensional emotional tagging
Aug 07, 2025EEG based multi-dimension emotion recognition has attracted substantial research interest in human computer interfaces. However, the high dimensionality of EEG features, coupled with limited sample sizes, frequently leads to classifier overfitting and high computational complexity. Feature selection constitutes a critical strategy for mitigating these challenges. Most existing EEG feature selection methods assume complete multi-dimensional emotion labels. In practice, open acquisition environment, and the inherent subjectivity of emotion perception often result in incomplete label data, which can compromise model generalization. Additionally, existing feature selection methods for handling incomplete multi-dimensional labels primarily focus on correlations among various dimensions during label recovery, neglecting the correlation between samples in the label space and their interaction with various dimensions. To address these issues, we propose a novel incomplete multi-dimensional feature selection algorithm for EEG-based emotion recognition. The proposed method integrates an adaptive dual self-expression learning (ADSEL) with least squares regression. ADSEL establishes a bidirectional pathway between sample-level and dimension-level self-expression learning processes within the label space. It could facilitate the cross-sharing of learned information between these processes, enabling the simultaneous exploitation of effective information across both samples and dimensions for label reconstruction. Consequently, ADSEL could enhances label recovery accuracy and effectively identifies the optimal EEG feature subset for multi-dimensional emotion recognition.
Hyperspherical Embedding for Point Cloud Completion
Jul 11, 2023Most real-world 3D measurements from depth sensors are incomplete, and to address this issue the point cloud completion task aims to predict the complete shapes of objects from partial observations. Previous works often adapt an encoder-decoder architecture, where the encoder is trained to extract embeddings that are used as inputs to generate predictions from the decoder. However, the learned embeddings have sparse distribution in the feature space, which leads to worse generalization results during testing. To address these problems, this paper proposes a hyperspherical module, which transforms and normalizes embeddings from the encoder to be on a unit hypersphere. With the proposed module, the magnitude and direction of the output hyperspherical embedding are decoupled and only the directional information is optimized. We theoretically analyze the hyperspherical embedding and show that it enables more stable training with a wider range of learning rates and more compact embedding distributions. Experiment results show consistent improvement of point cloud completion in both single-task and multi-task learning, which demonstrates the effectiveness of the proposed method.
Learning Rotation-Invariant Representations of Point Clouds Using Aligned Edge Convolutional Neural Networks
Jan 02, 2021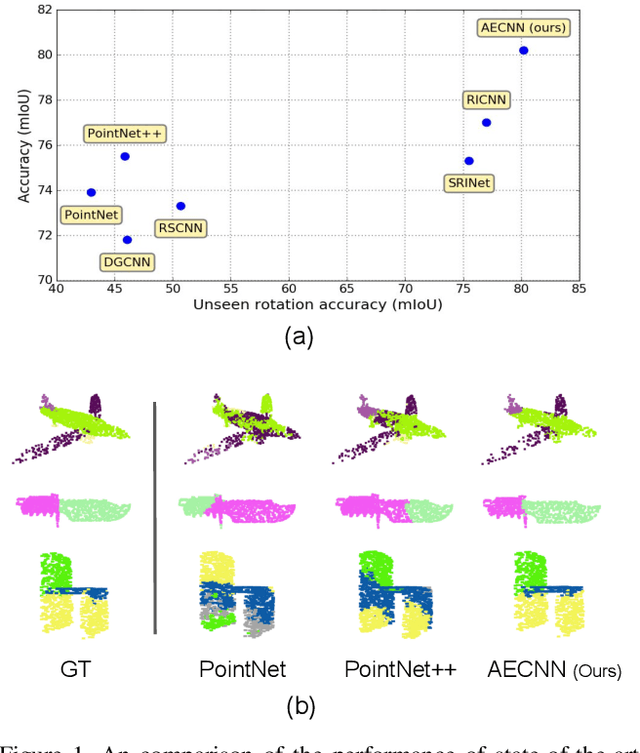
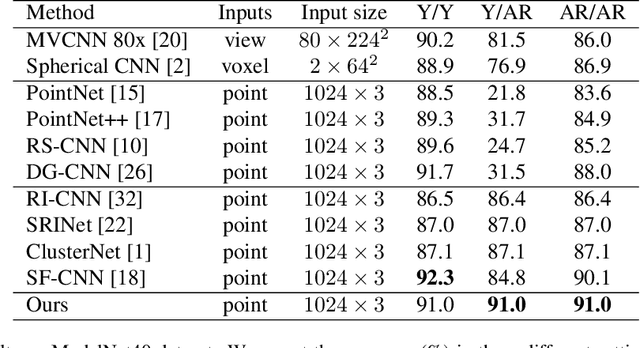
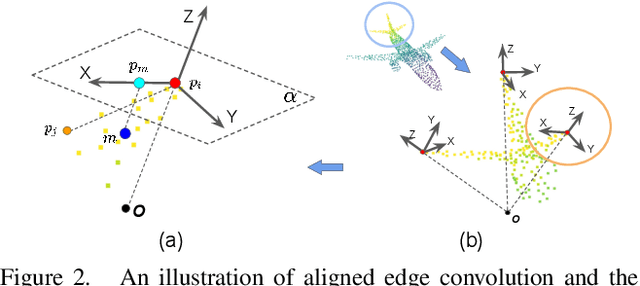
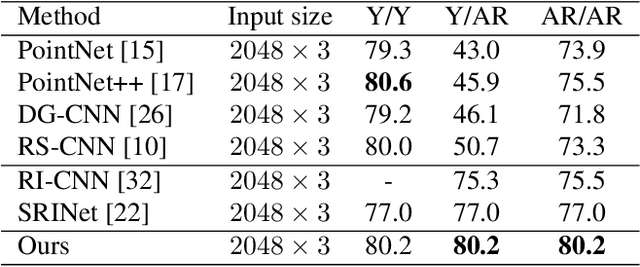
Point cloud analysis is an area of increasing interest due to the development of 3D sensors that are able to rapidly measure the depth of scenes accurately. Unfortunately, applying deep learning techniques to perform point cloud analysis is non-trivial due to the inability of these methods to generalize to unseen rotations. To address this limitation, one usually has to augment the training data, which can lead to extra computation and require larger model complexity. This paper proposes a new neural network called the Aligned Edge Convolutional Neural Network (AECNN) that learns a feature representation of point clouds relative to Local Reference Frames (LRFs) to ensure invariance to rotation. In particular, features are learned locally and aligned with respect to the LRF of an automatically computed reference point. The proposed approach is evaluated on point cloud classification and part segmentation tasks. This paper illustrates that the proposed technique outperforms a variety of state of the art approaches (even those trained on augmented datasets) in terms of robustness to rotation without requiring any additional data augmentation.
Point Set Voting for Partial Point Cloud Analysis
Jul 09, 2020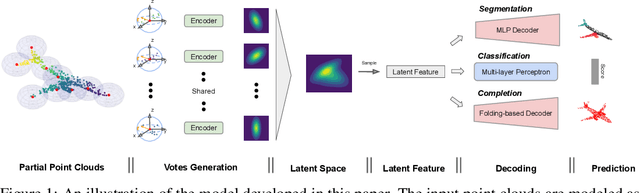
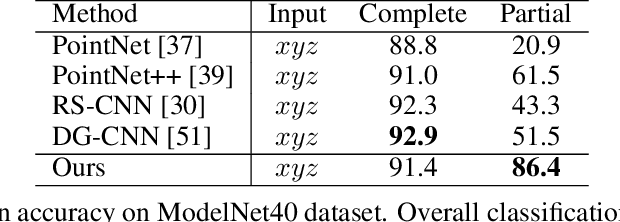
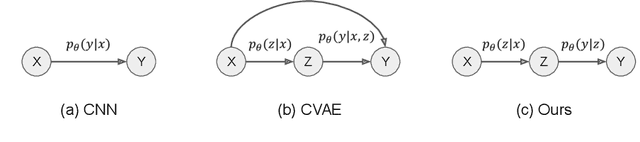
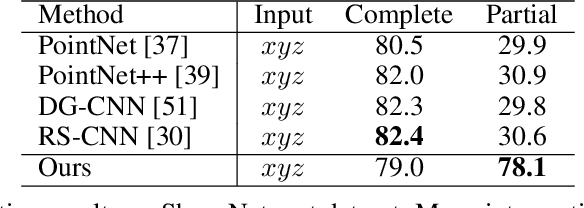
The continual improvement of 3D sensors has driven the development of algorithms to perform point cloud analysis. In fact, techniques for point cloud classification and segmentation have in recent years achieved incredible performance driven in part by leveraging large synthetic datasets. Unfortunately these same state-of-the-art approaches perform poorly when applied to incomplete point clouds. This limitation of existing algorithms is particularly concerning since point clouds generated by 3D sensors in the real world are usually incomplete due to perspective view or occlusion by other objects. This paper proposes a general model for partial point clouds analysis wherein the latent feature encoding a complete point clouds is inferred by applying a local point set voting strategy. In particular, each local point set constructs a vote that corresponds to a distribution in the latent space, and the optimal latent feature is the one with the highest probability. This approach ensures that any subsequent point cloud analysis is robust to partial observation while simultaneously guaranteeing that the proposed model is able to output multiple possible results. This paper illustrates that this proposed method achieves state-of-the-art performance on shape classification, part segmentation and point cloud completion.