 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DWG: 3D Weakly Supervised Visual Grounding via Category and Instance-Level Alignment
May 03, 2025The 3D weakly-supervised visual grounding task aims to localize oriented 3D boxes in point clouds based on natural language descriptions without requiring annotations to guide model learning. This setting presents two primary challenges: category-level ambiguity and instance-level complexity. Category-level ambiguity arises from representing objects of fine-grained categories in a highly sparse point cloud format, making category distinction challenging. Instance-level complexity stems from multiple instances of the same category coexisting in a scene, leading to distractions during grounding. To address these challenges, we propose a novel weakly-supervised grounding approach that explicitly differentiates between categories and instances. In the category-level branch, we utilize extensive category knowledge from a pre-trained external detector to align object proposal features with sentence-level category features, thereby enhancing category awareness. In the instance-level branch, we utilize spatial relationship descriptions from language queries to refine object proposal features, ensuring clear differentiation among objects. These designs enable our model to accurately identify target-category objects while distinguishing instances within the same category. Compared to previous methods, our approach achieves state-of-the-art performance on three widely used benchmarks: Nr3D, Sr3D, and ScanRef.
EmpathyAgent: Can Embodied Agents Conduct Empathetic Actions?
Mar 19, 2025Empathy is fundamental to human interactions, yet it remains unclear whether embodied agents can provide human-like empathetic support. Existing works have studied agents' tasks solving and social interactions abilities, but whether agents can understand empathetic needs and conduct empathetic behaviors remains overlooked. To address this, we introduce EmpathyAgent, the first benchmark to evaluate and enhance agents' empathetic actions across diverse scenarios. EmpathyAgent contains 10,000 multimodal samples with corresponding empathetic task plans and three different challenges. To systematically evaluate the agents' empathetic actions, we propose an empathy-specific evaluation suite that evaluates the agents' empathy process. We benchmark current models and found that exhibiting empathetic actions remains a significant challenge. Meanwhile, we train Llama3-8B using EmpathyAgent and find it can potentially enhance empathetic behavior. By establishing a standard benchmark for evaluating empathetic actions, we hope to advance research in empathetic embodied agents. Our code and data are publicly available at https://github.com/xinyan-cxy/EmpathyAgent.
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Mar 13, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods leverage large-scale pretrained knowledge, they disrupt the continuity of actions. Meanwhile, some VLA methods incorporate an additional diffusion head to predict continuous actions, relying solely on VLM-extracted features, which limits their reasoning capabilities. In this paper, we introduce HybridVLA, a unified framework that seamlessly integrates the strengths of both autoregressive and diffusion policies within a single large language model, rather than simply connecting them. To bridge the generation gap, a collaborative training recipe is proposed that injects the diffusion modeling directly into the next-token prediction. With this recipe, we find that these two forms of action prediction not only reinforce each other but also exhibit varying performance across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses these two predictions, leading to more robust control. In experiments, HybridVLA outperforms previous state-of-the-art VLA methods across various simulation and real-world tasks, including both single-arm and dual-arm robots, while demonstrating stable manipulation in previously unseen configurations.
EasyControl: Adding Efficient and Flexible Control for Diffusion Transformer
Mar 10, 2025

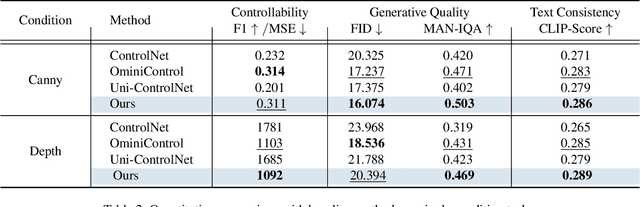

Recent advancements in Unet-based diffusion models, such as ControlNet and IP-Adapter, have introduced effective spatial and subject control mechanisms. However, the DiT (Diffusion Transformer) architecture still struggles with efficient and flexible control. To tackle this issue, we propose EasyControl, a novel framework designed to unify condition-guided diffusion transformers with high efficiency and flexibility. Our framework is built on three key innovations. First, we introduce a lightweight Condition Injection LoRA Module. This module processes conditional signals in isolation, acting as a plug-and-play solution. It avoids modifying the base model weights, ensuring compatibility with customized models and enabling the flexible injection of diverse conditions. Notably, this module also supports harmonious and robust zero-shot multi-condition generalization, even when trained only on single-condition data. Second, we propose a Position-Aware Training Paradigm. This approach standardizes input conditions to fixed resolutions, allowing the generation of images with arbitrary aspect ratios and flexible resolutions. At the same time, it optimizes computational efficiency, making the framework more practical for real-world applications. Third, we develop a Causal Attention Mechanism combined with the KV Cache technique, adapted for conditional generation tasks. This innovation significantly reduces the latency of image synthesis, improving the overall efficiency of the framework. Through extensive experiments, we demonstrate that EasyControl achieves exceptional performance across various application scenarios. These innovations collectively make our framework highly efficient, flexible, and suitable for a wide range of tasks.
Improving SAM for Camouflaged Object Detection via Dual Stream Adapters
Mar 08, 2025Segment anything model (SAM) has shown impressive general-purpose segmentation performance on natural images, but its performance on camouflaged object detection (COD) is unsatisfactory. In this paper, we propose SAM-COD that performs camouflaged object detection for RGB-D inputs. While keeping the SAM architecture intact, dual stream adapters are expanded on the image encoder to learn potential complementary information from RGB images and depth images, and fine-tune the mask decoder and its depth replica to perform dual-stream mask prediction. In practice, the dual stream adapters are embedded into the attention block of the image encoder in a parallel manner to facilitate the refinement and correction of the two types of image embeddings. To mitigate channel discrepancies arising from dual stream embeddings that do not directly interact with each other, we augment the association of dual stream embeddings using bidirectional knowledge distillation including a model distiller and a modal distiller. In addition, to predict the masks for RGB and depth attention maps, we hybridize the two types of image embeddings which are jointly learned with the prompt embeddings to update the initial prompt, and then feed them into the mask decoders to synchronize the consistency of image embeddings and prompt embeddings. Experimental results on four COD benchmarks show that our SAM-COD achieves excellent detection performance gains over SAM and achieves state-of-the-art results with a given fine-tuning paradigm.
RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
Feb 28, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: Planning Capability, which involves decomposing complex manipulation instructions into manageable sub-tasks; Affordance Perception, the ability to recognize and interpret the affordances of interactive objects; and Trajectory Prediction, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
PhotoDoodle: Learning Artistic Image Editing from Few-Shot Pairwise Data
Feb 23, 2025We introduce PhotoDoodle, a novel image editing framework designed to facilitate photo doodling by enabling artists to overlay decorative elements onto photographs. Photo doodling is challenging because the inserted elements must appear seamlessly integrated with the background, requiring realistic blending, perspective alignment, and contextual coherence. Additionally, the background must be preserved without distortion, and the artist's unique style must be captured efficiently from limited training data. These requirements are not addressed by previous methods that primarily focus on global style transfer or regional inpainting. The proposed method, PhotoDoodle, employs a two-stage training strategy. Initially, we train a general-purpose image editing model, OmniEditor, using large-scale data. Subsequently, we fine-tune this model with EditLoRA using a small, artist-curated dataset of before-and-after image pairs to capture distinct editing styles and techniques. To enhance consistency in the generated results, we introduce a positional encoding reuse mechanism. Additionally, we release a PhotoDoodle dataset featuring six high-quality styles. Extensive experiments demonstrate the advanced performance and robustness of our method in customized image editing, opening new possibilities for artistic creation.
CordViP: Correspondence-based Visuomotor Policy for Dexterous Manipulation in Real-World
Feb 12, 2025Achieving human-level dexterity in robots is a key objective in the field of robotic manipulation. Recent advancements in 3D-based imitation learning have shown promising results, providing an effective pathway to achieve this goal. However, obtaining high-quality 3D representations presents two key problems: (1) the quality of point clouds captured by a single-view camera is significantly affected by factors such as camera resolution, positioning, and occlusions caused by the dexterous hand; (2) the global point clouds lack crucial contact information and spatial correspondences, which are necessary for fine-grained dexterous manipulation tasks. To eliminate these limitations, we propose CordViP, a novel framework that constructs and learns correspondences by leveraging the robust 6D pose estimation of objects and robot proprioception. Specifically, we first introduce the interaction-aware point clouds, which establish correspondences between the object and the hand. These point clouds are then used for our pre-training policy, where we also incorporate object-centric contact maps and hand-arm coordination information, effectively capturing both spatial and temporal dynamics. Our method demonstrates exceptional dexterous manipulation capabilities with an average success rate of 90\% in four real-world tasks, surpassing other baselines by a large margin. Experimental results also highlight the superior generalization and robustness of CordViP to different objects, viewpoints, and scenarios. Code and videos are available on https://aureleopku.github.io/CordViP.
Any2AnyTryon: Leveraging Adaptive Position Embeddings for Versatile Virtual Clothing Tasks
Jan 27, 2025Image-based virtual try-on (VTON) aims to generate a virtual try-on result by transferring an input garment onto a target person's image. However, the scarcity of paired garment-model data makes it challenging for existing methods to achieve high generalization and quality in VTON. Also, it limits the ability to generate mask-free try-ons. To tackle the data scarcity problem, approaches such as Stable Garment and MMTryon use a synthetic data strategy, effectively increasing the amount of paired data on the model side. However, existing methods are typically limited to performing specific try-on tasks and lack user-friendliness. To enhance the generalization and controllability of VTON generation, we propose Any2AnyTryon, which can generate try-on results based on different textual instructions and model garment images to meet various needs, eliminating the reliance on masks, poses, or other conditions. Specifically, we first construct the virtual try-on dataset LAION-Garment, the largest known open-source garment try-on dataset. Then, we introduce adaptive position embedding, which enables the model to generate satisfactory outfitted model images or garment images based on input images of different sizes and categories, significantly enhancing the generalization and controllability of VTON generation. In our experiments, we demonstrate the effectiveness of our Any2AnyTryon and compare it with existing methods. The results show that Any2AnyTryon enables flexible, controllable, and high-quality image-based virtual try-on generation.https://logn-2024.github.io/Any2anyTryonProjectPage/
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024



Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.