 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-and-Local Collaborative Learning for Co-Salient Object Detection
Apr 19, 2022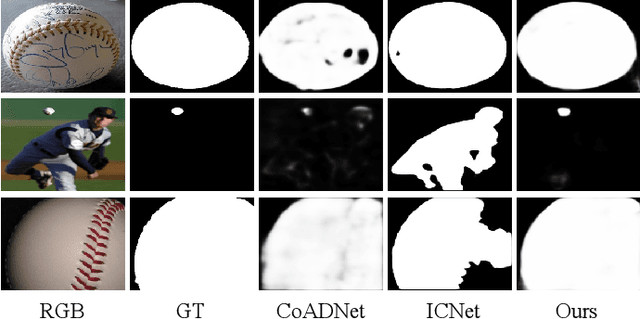
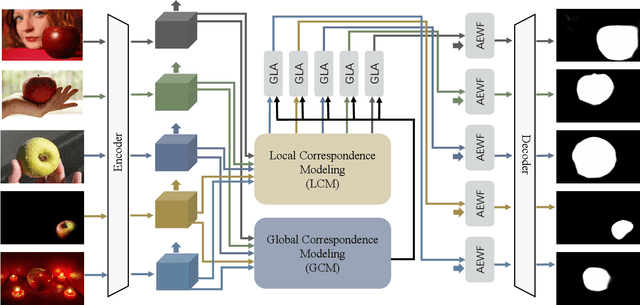
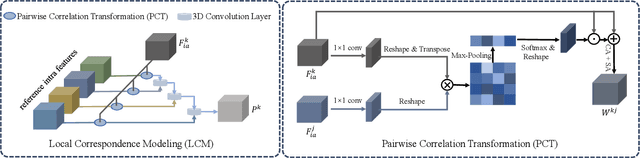

The goal of co-salient object detection (CoSOD) is to discover salient objects that commonly appear in a query group containing two or more relevant images. Therefore, how to effectively extract inter-image correspondence is crucial for the CoSOD task. In this paper, we propose a global-and-local collaborative learning architecture, which includes a global correspondence modeling (GCM) and a local correspondence modeling (LCM) to capture comprehensive inter-image corresponding relationship among different images from the global and local perspectives. Firstly, we treat different images as different time slices and use 3D convolution to integrate all intra features intuitively, which can more fully extract the global group semantics. Secondly, we design a pairwise correlation transformation (PCT) to explore similarity correspondence between pairwise images and combine the multiple local pairwise correspondences to generate the local inter-image relationship. Thirdly, the inter-image relationships of the GCM and LCM are integrated through a global-and-local correspondence aggregation (GLA) module to explore more comprehensive inter-image collaboration cues. Finally, the intra- and inter-features are adaptively integrated by an intra-and-inter weighting fusion (AEWF) module to learn co-saliency features and predict the co-saliency map. The proposed GLNet is evaluated on three prevailing CoSOD benchmark datasets, demonstrating that our model trained on a small dataset (about 3k images) still outperforms eleven state-of-the-art competitors trained on some large datasets (about 8k-200k images).
Video Polyp Segmentation: A Deep Learning Perspective
Mar 27, 2022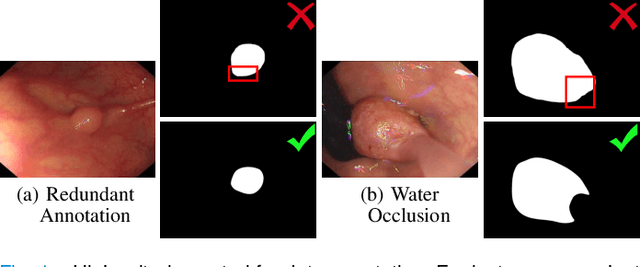
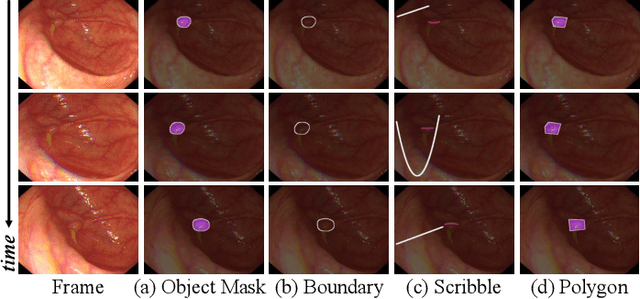
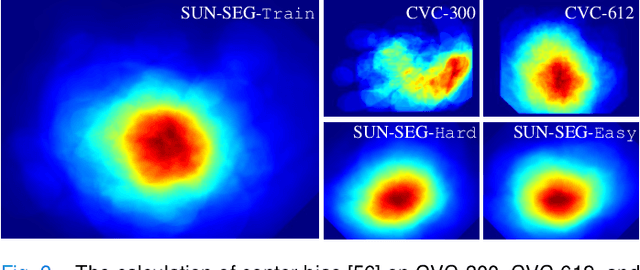
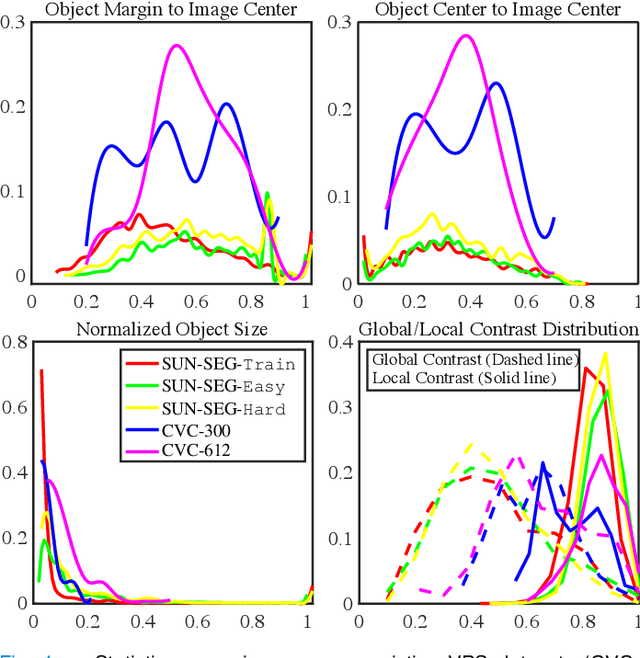
In the deep learning era, we present the first comprehensive video polyp segmentation (VPS) study. Over the years, developments in VPS are not moving forward with ease due to the lack of large-scale fine-grained segmentation annotations. To tackle this issue, we first introduce a high-quality per-frame annotated VPS dataset, named SUN-SEG, which includes 158,690 frames from the famous SUN dataset. We provide additional annotations with diverse types, i.e., attribute, object mask, boundary, scribble, and polygon. Second, we design a simple but efficient baseline, dubbed PNS+, consisting of a global encoder, a local encoder, and normalized self-attention (NS) blocks. The global and local encoders receive an anchor frame and multiple successive frames to extract long-term and short-term feature representations, which are then progressively updated by two NS blocks. Extensive experiments show that PNS+ achieves the best performance and real-time inference speed (170fps), making it a promising solution for the VPS task. Third, we extensively evaluate 13 representative polyp/object segmentation models on our SUN-SEG dataset and provide attribute-based comparisons. Benchmark results are available at https: //github.com/GewelsJI/VPS.
RSCFed: Random Sampling Consensus Federated Semi-supervised Learning
Mar 26, 2022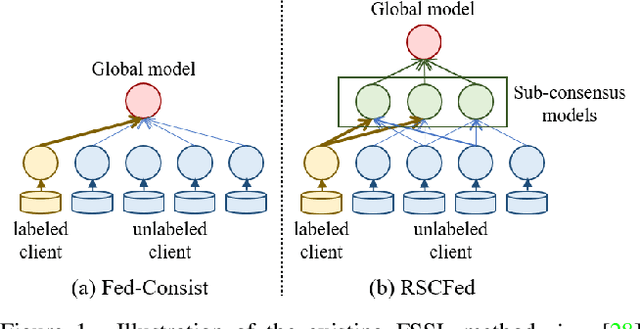
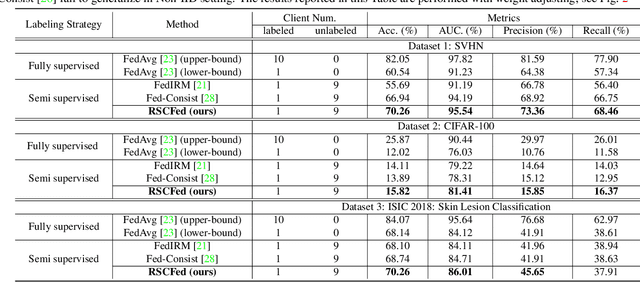
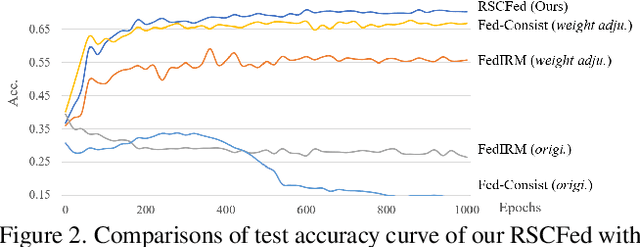
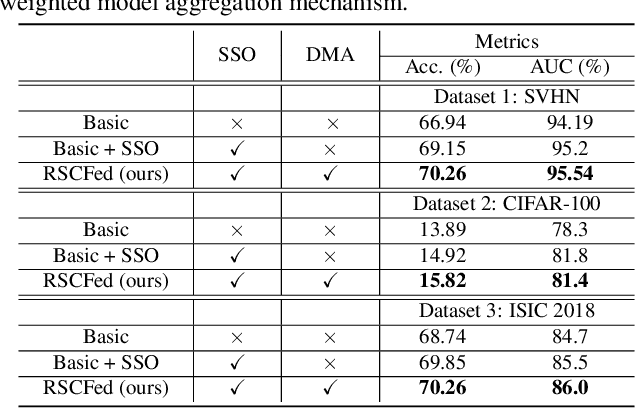
Federated semi-supervised learning (FSSL) aims to derive a global model by training fully-labeled and fully-unlabeled clients or training partially labeled clients. The existing approaches work well when local clients have independent and identically distributed (IID) data but fail to generalize to a more practical FSSL setting, i.e., Non-IID setting. In this paper, we present a Random Sampling Consensus Federated learning, namely RSCFed, by considering the uneven reliability among models from fully-labeled clients, fully-unlabeled clients or partially labeled clients. Our key motivation is that given models with large deviations from either labeled clients or unlabeled clients, the consensus could be reached by performing random sub-sampling over clients. To achieve it, instead of directly aggregating local models, we first distill several sub-consensus models by random sub-sampling over clients and then aggregating the sub-consensus models to the global model. To enhance the robustness of sub-consensus models, we also develop a novel distance-reweighted model aggregation method. Experimental results show that our method outperforms state-of-the-art methods on three benchmarked datasets, including both natural and medical images. The code is available at https://github.com/XMed-Lab/RSCFed.
FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction
Mar 22, 2022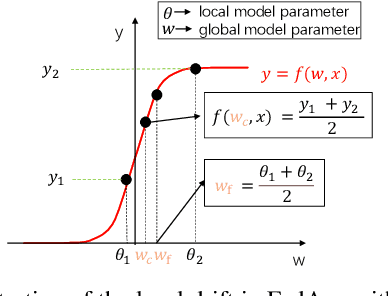
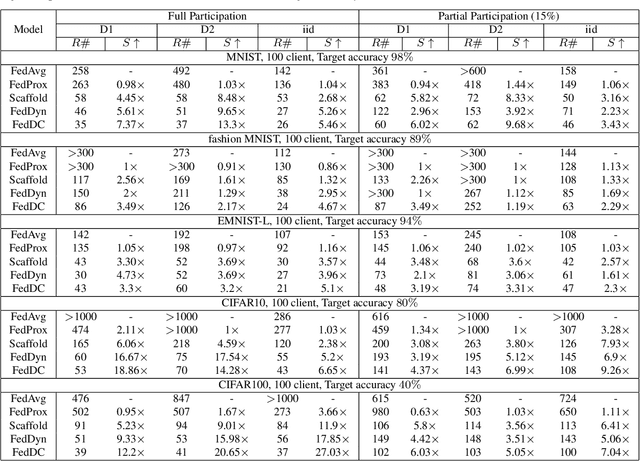
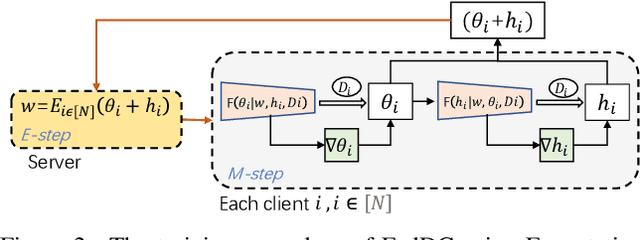
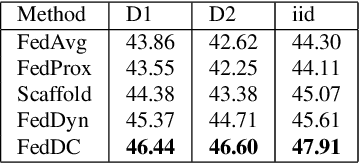
Federated learning (FL) allows multiple clients to collectively train a high-performance global model without sharing their private data. However, the key challenge in federated learning is that the clients have significant statistical heterogeneity among their local data distributions, which would cause inconsistent optimized local models on the client-side. To address this fundamental dilemma, we propose a novel federated learning algorithm with local drift decoupling and correction (FedDC). Our FedDC only introduces lightweight modifications in the local training phase, in which each client utilizes an auxiliary local drift variable to track the gap between the local model parameter and the global model parameters. The key idea of FedDC is to utilize this learned local drift variable to bridge the gap, i.e., conducting consistency in parameter-level. The experiment results and analysis demonstrate that FedDC yields expediting convergence and better performance on various image classification tasks, robust in partial participation settings, non-iid data, and heterogeneous clients.
An Annotation-free Restoration Network for Cataractous Fundus Images
Mar 15, 2022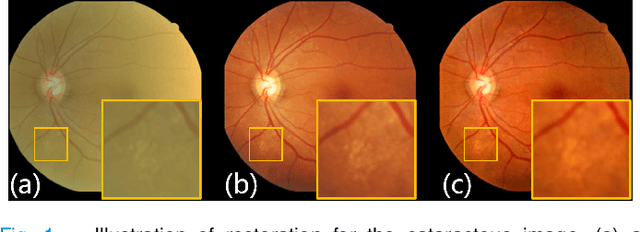
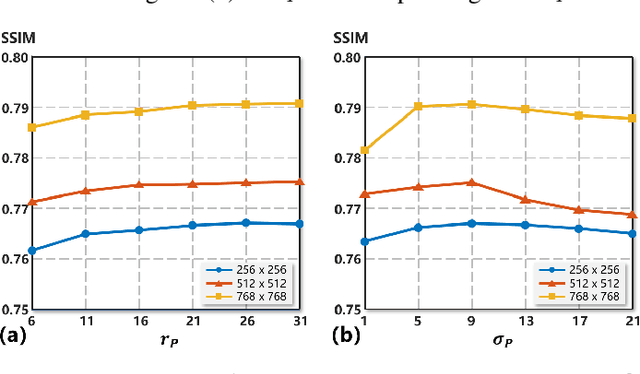
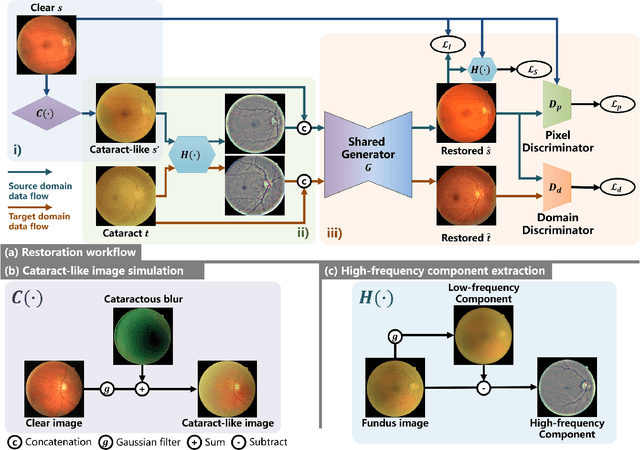
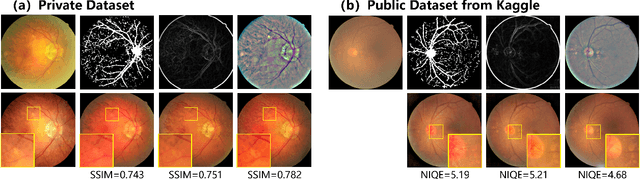
Cataracts are the leading cause of vision loss worldwide. Restoration algorithms are developed to improve the readability of cataract fundus images in order to increase the certainty in diagnosis and treatment for cataract patients. Unfortunately, the requirement of annotation limits the application of these algorithms in clinics. This paper proposes a network to annotation-freely restore cataractous fundus images (ArcNet) so as to boost the clinical practicability of restoration. Annotations are unnecessary in ArcNet, where the high-frequency component is extracted from fundus images to replace segmentation in the preservation of retinal structures. The restoration model is learned from the synthesized images and adapted to real cataract images. Extensive experiments are implemented to verify the performance and effectiveness of ArcNet. Favorable performance is achieved using ArcNet against state-of-the-art algorithms, and the diagnosis of ocular fundus diseases in cataract patients is promoted by ArcNet. The capability of properly restoring cataractous images in the absence of annotated data promises the proposed algorithm outstanding clinical practicability.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022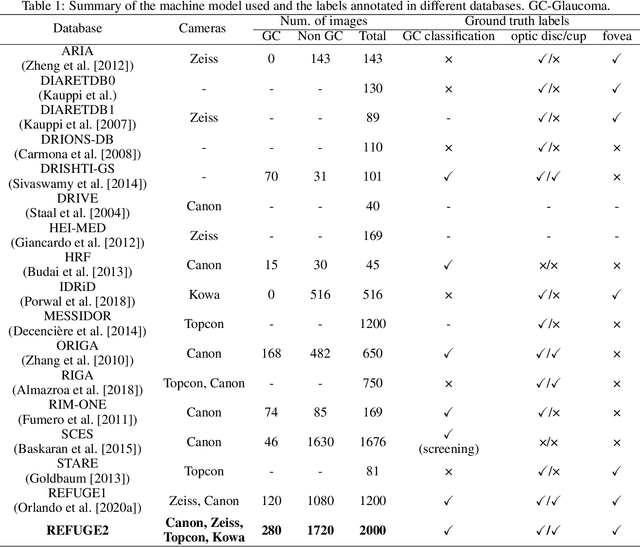
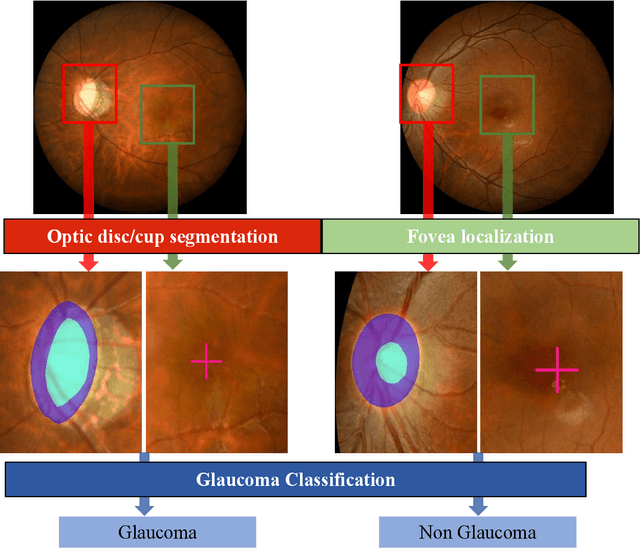
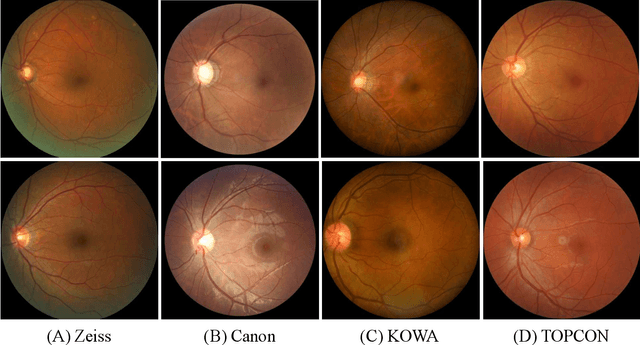
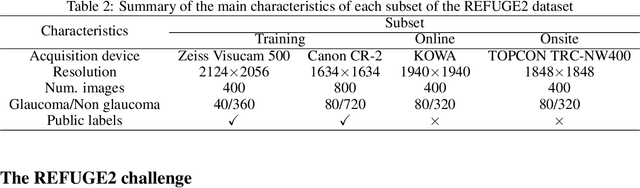
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022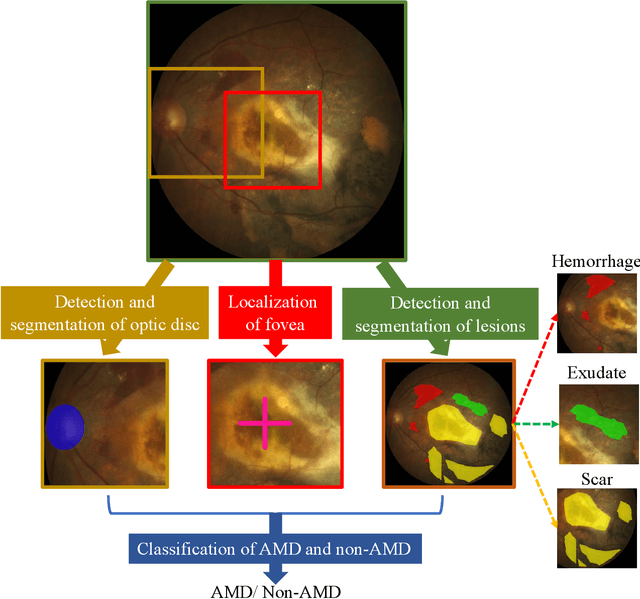

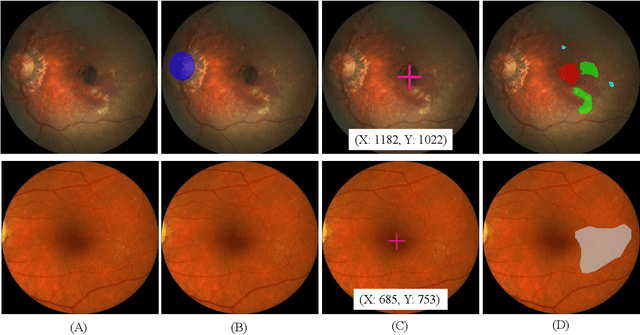
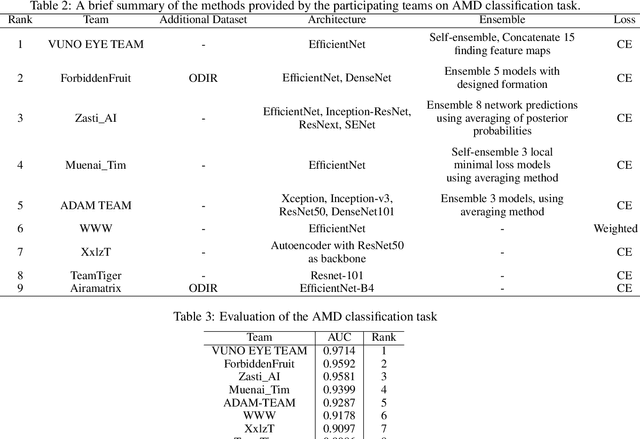
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022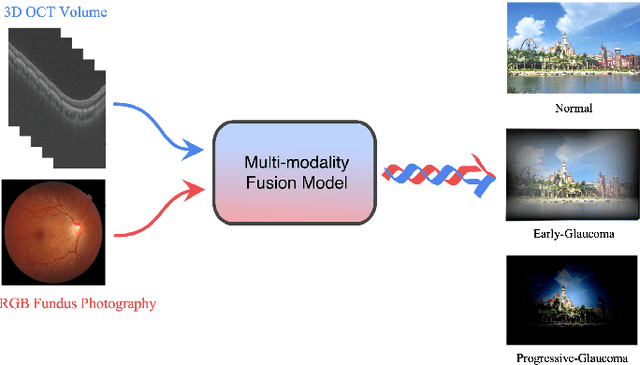
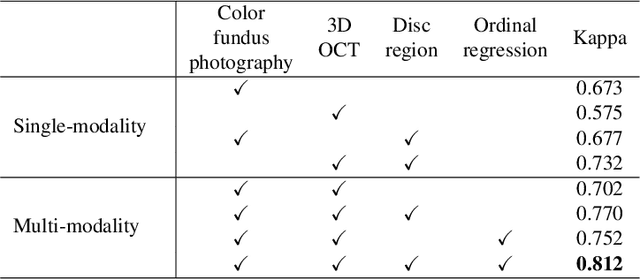
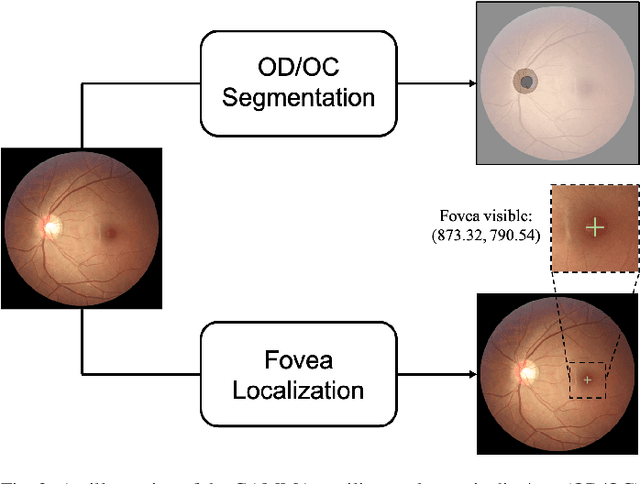
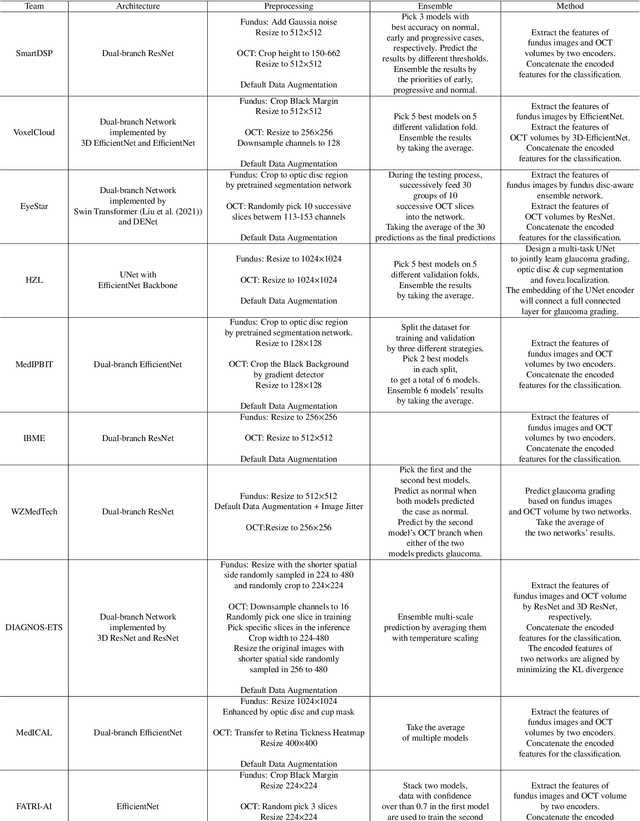
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022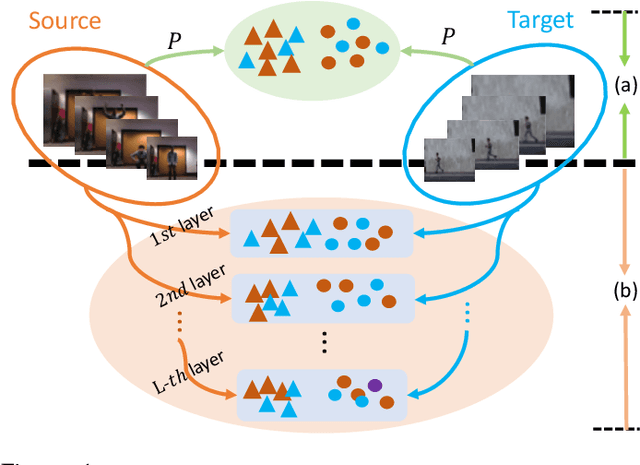

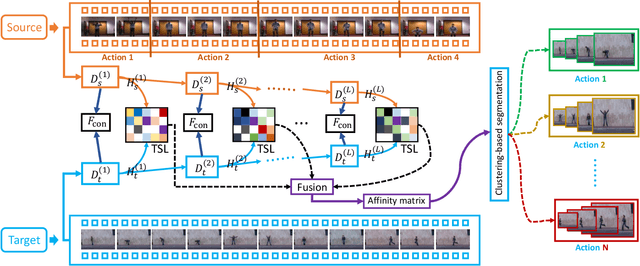
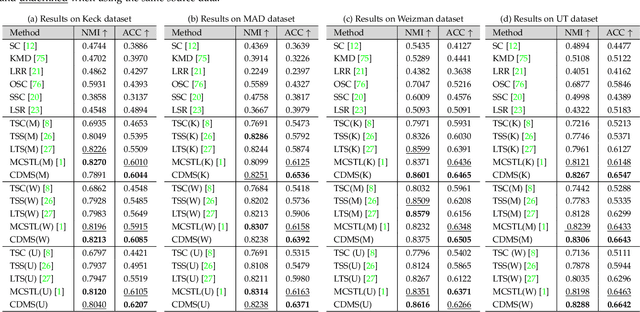
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.
Transformers in Medical Imaging: A Survey
Jan 24, 2022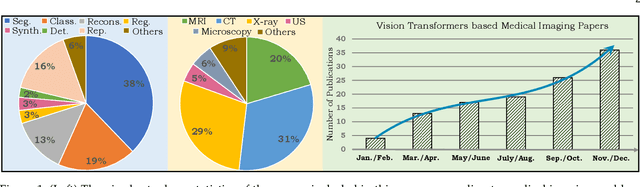
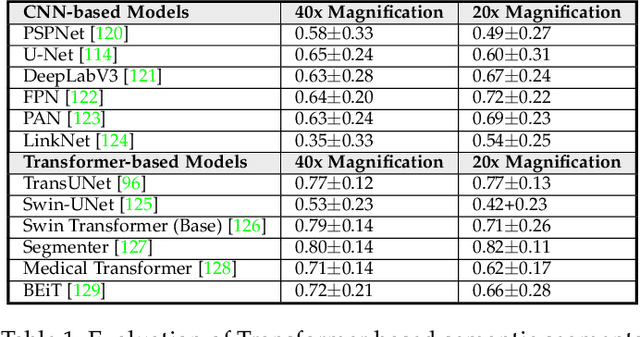
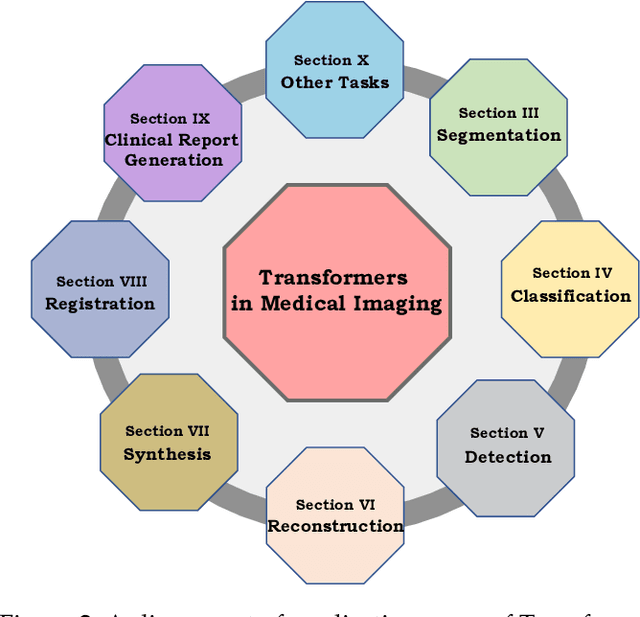
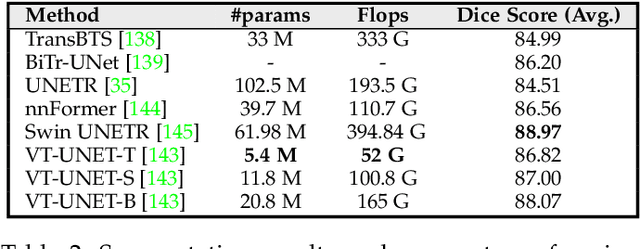
Following unprecedented success on the natural language tasks, Transformers have been successfully applied to several computer vision problems, achieving state-of-the-art results and prompting researchers to reconsider the supremacy of convolutional neural networks (CNNs) as {de facto} operators. Capitalizing on these advances in computer vision, the medical imaging field has also witnessed growing interest for Transformers that can capture global context compared to CNNs with local receptive fields. Inspired from this transition, in this survey, we attempt to provide a comprehensive review of the applications of Transformers in medical imaging covering various aspects, ranging from recently proposed architectural designs to unsolved issues. Specifically, we survey the use of Transformers in medical image segmentation, detection, classification, reconstruction, synthesis, registration, clinical report generation, and other tasks. In particular, for each of these applications, we develop taxonomy, identify application-specific challenges as well as provide insights to solve them, and highlight recent trends. Further, we provide a critical discussion of the field's current state as a whole, including the identification of key challenges, open problems, and outlining promising future directions. We hope this survey will ignite further interest in the community and provide researchers with an up-to-date reference regarding applications of Transformer models in medical imaging. Finally, to cope with the rapid development in this field, we intend to regularly update the relevant latest papers and their open-source implementations at \url{https://github.com/fahadshamshad/awesome-transformers-in-medical-imaging}.