 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Adaptive SwiGLU for Mixture-of-Experts
May 30, 2026SwiGLU has become a standard gated activation in modern Transformer MLPs, yet its gate sharpness -- the smoothness and selectivity of the gating function -- is typically fixed throughout training. In this work, we propose Confidence-Aware SwiGLU ($κ$-SwiGLU), a variant of SwiGLU for Mixture-of-Experts (MoE) models that adjusts expert gate sharpness according to token-level routing confidence. Specifically, $κ$-SwiGLU parameterizes the SiLU gate sharpness coefficient as a learnable function of the router logit, enabling each expert gate unit to interpolate between smooth, broadly active gating and sharp, selective gating. We evaluate $κ$-SwiGLU on the FineWeb-Edu dataset across MoE Transformer models ranging from 8 to 28 layers. Across these settings, $κ$-SwiGLU improves mean CORE performance while adding negligible parameters and incurring only a small computational overhead, demonstrating that confidence-aware gate sharpness is a promising mechanism for improving MoE MLPs. The code is available at https://github.com/askerlee/kappa-swiglu.
Knowdit: Agentic Smart Contract Vulnerability Detection with Auditing Knowledge Summarization
Mar 27, 2026Smart contracts govern billions of dollars in decentralized finance (DeFi), yet automated vulnerability detection remains challenging because many vulnerabilities are tightly coupled with project-specific business logic. We observe that recurring vulnerabilities across diverse DeFi business models often share the same underlying economic mechanisms, which we term DeFi semantics, and that capturing these shared abstractions can enable more systematic auditing. Building on this insight, we propose Knowdit, a knowledge-driven, agentic framework for smart contract vulnerability detection. Knowdit first constructs an auditing knowledge graph from historical human audit reports, linking fine-grained DeFi semantics with recurring vulnerability patterns. Given a new project, a multi-agent framework leverages this knowledge through an iterative loop of specification generation, harness synthesis, fuzz execution, and finding reflection, driven by a shared working memory for continuous refinement. We evaluate Knowdit on 12 recent Code4rena projects with 75 ground-truth vulnerabilities. Knowdit detects all 14 high-severity and 77\% of medium-severity vulnerabilities with only 2 false positives, significantly outperforming all baselines. Applied to six real-world projects, Knowdit further discovers 12 high- and 10 medium-severity previously unknown vulnerabilities, proving its outstanding performance.
Agentic Harness for Real-World Compilers
Mar 20, 2026Compilers are critical to modern computing, yet fixing compiler bugs is difficult. While recent large language model (LLM) advancements enable automated bug repair, compiler bugs pose unique challenges due to their complexity, deep cross-domain expertise requirements, and sparse, non-descriptive bug reports, necessitating compiler-specific tools. To bridge the gap, we introduce llvm-autofix, the first agentic harness designed to assist LLM agents in understanding and fixing compiler bugs. Our focus is on LLVM, one of the most widely used compiler infrastructures. Central to llvm-autofix are agent-friendly LLVM tools, a benchmark llvm-bench of reproducible LLVM bugs, and a tailored minimal agent llvm-autofix-mini for fixing LLVM bugs. Our evaluation demonstrates a performance decline of 60% in frontier models when tackling compiler bugs compared with common software bugs. Our minimal agent llvm-autofix-mini also outperforms the state-of-the-art by approximately 22%. This emphasizes the necessity for specialized harnesses like ours to close the loop between LLMs and compiler engineering. We believe this work establishes a foundation for advancing LLM capabilities in complex systems like compilers. GitHub: https://github.com/dtcxzyw/llvm-autofix
Structured Semantic Cloaking for Jailbreak Attacks on Large Language Models
Mar 17, 2026Modern LLMs employ safety mechanisms that extend beyond surface-level input filtering to latent semantic representations and generation-time reasoning, enabling them to recover obfuscated malicious intent during inference and refuse accordingly, and rendering many surface-level obfuscation jailbreak attacks ineffective. We propose Structured Semantic Cloaking (S2C), a novel multi-dimensional jailbreak attack framework that manipulates how malicious semantic intent is reconstructed during model inference. S2C strategically distributes and reshapes semantic cues such that full intent consolidation requires multi-step inference and long-range co-reference resolution within deeper latent representations. The framework comprises three complementary mechanisms: (1) Contextual Reframing, which embeds the request within a plausible high-stakes scenario to bias the model toward compliance; (2) Content Fragmentation, which disperses the semantic signature of the request across disjoint prompt segments; and (3) Clue-Guided Camouflage, which disguises residual semantic cues while embedding recoverable markers that guide output generation. By delaying and restructuring semantic consolidation, S2C degrades safety triggers that depend on coherent or explicitly reconstructed malicious intent at decoding time, while preserving sufficient instruction recoverability for functional output generation. We evaluate S2C across multiple open-source and proprietary LLMs using HarmBench and JBB-Behaviors, where it improves Attack Success Rate (ASR) by 12.4% and 9.7%, respectively, over the current SOTA. Notably, S2C achieves substantial gains on GPT-5-mini, outperforming the strongest baseline by 26% on JBB-Behaviors. We also analyse which combinations perform best against broad families of models, and characterise the trade-off between the extent of obfuscation versus input recoverability on jailbreak success.
Is Your Benchmark (Still) Useful? Dynamic Benchmarking for Code Language Models
Mar 09, 2025In this paper, we tackle a critical challenge in model evaluation: how to keep code benchmarks useful when models might have already seen them during training. We introduce a novel solution, dynamic benchmarking framework, to address this challenge. Given a code understanding or reasoning benchmark, our framework dynamically transforms each input, i.e., programs, with various semantic-preserving mutations to build a syntactically new while semantically identical benchmark. We evaluated ten popular language models on our dynamic benchmarks. Our evaluation reveals several interesting or surprising findings: (1) all models perform significantly worse than before, (2) the ranking between some models shifts dramatically, and (3) our dynamic benchmarks can resist against the data contamination problem.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024



This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
Diffusion-EXR: Controllable Review Generation for Explainable Recommendation via Diffusion Models
Dec 24, 2023



Denoising Diffusion Probabilistic Model (DDPM) has shown great competence in image and audio generation tasks. However, there exist few attempts to employ DDPM in the text generation, especially review generation under recommendation systems. Fueled by the predicted reviews explainability that justifies recommendations could assist users better understand the recommended items and increase the transparency of recommendation system, we propose a Diffusion Model-based Review Generation towards EXplainable Recommendation named Diffusion-EXR. Diffusion-EXR corrupts the sequence of review embeddings by incrementally introducing varied levels of Gaussian noise to the sequence of word embeddings and learns to reconstruct the original word representations in the reverse process. The nature of DDPM enables our lightweight Transformer backbone to perform excellently in the recommendation review generation task. Extensive experimental results have demonstrated that Diffusion-EXR can achieve state-of-the-art review generation for recommendation on two publicly available benchmark datasets.
Integrating Large Pre-trained Models into Multimodal Named Entity Recognition with Evidential Fusion
Jun 29, 2023Multimodal Named Entity Recognition (MNER) is a crucial task for information extraction from social media platforms such as Twitter. Most current methods rely on attention weights to extract information from both text and images but are often unreliable and lack interpretability. To address this problem, we propose incorporating uncertainty estimation into the MNER task, producing trustworthy predictions. Our proposed algorithm models the distribution of each modality as a Normal-inverse Gamma distribution, and fuses them into a unified distribution with an evidential fusion mechanism, enabling hierarchical characterization of uncertainties and promotion of prediction accuracy and trustworthiness. Additionally, we explore the potential of pre-trained large foundation models in MNER and propose an efficient fusion approach that leverages their robust feature representations. Experiments on two datasets demonstrate that our proposed method outperforms the baselines and achieves new state-of-the-art performance.
Localizing Anatomical Landmarks in Ocular Images using Zoom-In Attentive Networks
Sep 25, 2022Localizing anatomical landmarks are important tasks in medical image analysis. However, the landmarks to be localized often lack prominent visual features. Their locations are elusive and easily confused with the background, and thus precise localization highly depends on the context formed by their surrounding areas. In addition, the required precision is usually higher than segmentation and object detection tasks. Therefore, localization has its unique challenges different from segmentation or detection. In this paper, we propose a zoom-in attentive network (ZIAN) for anatomical landmark localization in ocular images. First, a coarse-to-fine, or "zoom-in" strategy is utilized to learn the contextualized features in different scales. Then, an attentive fusion module is adopted to aggregate multi-scale features, which consists of 1) a co-attention network with a multiple regions-of-interest (ROIs) scheme that learns complementary features from the multiple ROIs, 2) an attention-based fusion module which integrates the multi-ROIs features and non-ROI features. We evaluated ZIAN on two open challenge tasks, i.e., the fovea localization in fundus images and scleral spur localization in AS-OCT images. Experiments show that ZIAN achieves promising performances and outperforms state-of-the-art localization methods. The source code and trained models of ZIAN are available at https://github.com/leixiaofeng-astar/OMIA9-ZIAN.
CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
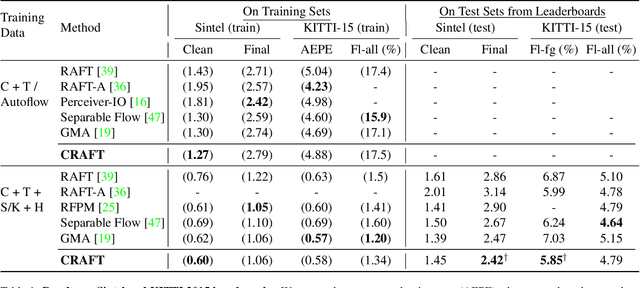
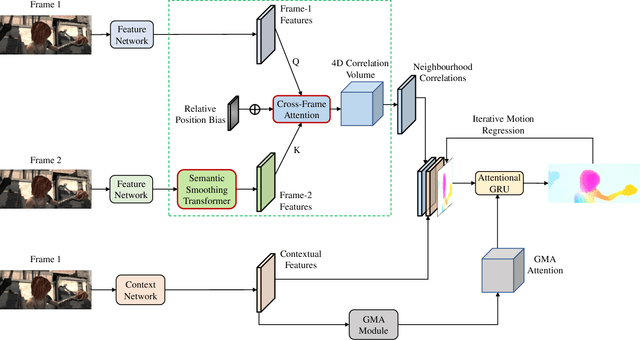
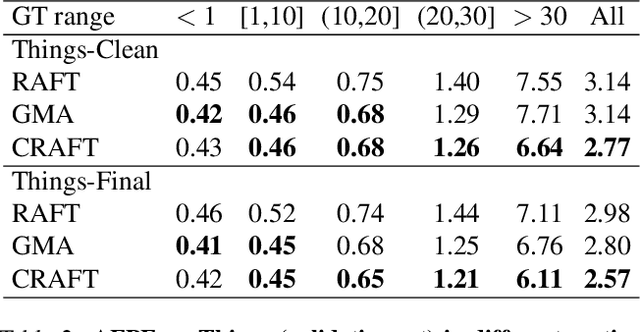
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.