 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Task-Oriented Token Communication for AI-Native 6G Networks
Jun 12, 2026The integration of Foundation Models (FMs) and wireless communications is driving the evolution of image communication from bit-accurate transmission toward task-oriented transmission. However, existing task-oriented image communication methods still face three major challenges: insufficient task-oriented Token representation, inadequate collaboration between Visual Tokens and Task Tokens, and limited interpretability of task decisions. To address these challenges, we propose an Explainable Task-Oriented Token Communication (ET-TokenCom) framework. By treating Tokens as unified units for information representation and transmission, the proposed framework constructs an end-to-end communication link that spans visual perception, wireless transmission, and task reasoning. At the transmitter, the ET-TokenCom framework extracts Visual Tokens from images to preserve low-level visual information. Meanwhile, Task Tokens generated by the FM are introduced to represent the target information and decision intent required by the current task. A Cross-Modal Attention (CMA) fusion mechanism is further designed, enabling Task Tokens to explicitly guide the selection, weighting, and transmission of Visual Tokens. At the receiver, the framework integrates Token decoding with an explainable output mechanism, where attention heatmaps are generated to highlight critical perceptual regions under different task objectives and reveal the influence of Task Tokens on the outputs. Finally, simulation results validate the effectiveness and robustness of the proposed ET-TokenCom framework.
Recurrent Visual Feature Extraction and Stereo Attentions for CT Report Generation
Jun 24, 2025



Generating reports for computed tomography (CT) images is a challenging task, while similar to existing studies for medical image report generation, yet has its unique characteristics, such as spatial encoding of multiple images, alignment between image volume and texts, etc. Existing solutions typically use general 2D or 3D image processing techniques to extract features from a CT volume, where they firstly compress the volume and then divide the compressed CT slices into patches for visual encoding. These approaches do not explicitly account for the transformations among CT slices, nor do they effectively integrate multi-level image features, particularly those containing specific organ lesions, to instruct CT report generation (CTRG). In considering the strong correlation among consecutive slices in CT scans, in this paper, we propose a large language model (LLM) based CTRG method with recurrent visual feature extraction and stereo attentions for hierarchical feature modeling. Specifically, we use a vision Transformer to recurrently process each slice in a CT volume, and employ a set of attentions over the encoded slices from different perspectives to selectively obtain important visual information and align them with textual features, so as to better instruct an LLM for CTRG. Experiment results and further analysis on the benchmark M3D-Cap dataset show that our method outperforms strong baseline models and achieves state-of-the-art results, demonstrating its validity and effectiveness.
DNAZEN: Enhanced Gene Sequence Representations via Mixed Granularities of Coding Units
May 04, 2025



Genome modeling conventionally treats gene sequence as a language, reflecting its structured motifs and long-range dependencies analogous to linguistic units and organization principles such as words and syntax. Recent studies utilize advanced neural networks, ranging from convolutional and recurrent models to Transformer-based models, to capture contextual information of gene sequence, with the primary goal of obtaining effective gene sequence representations and thus enhance the models' understanding of various running gene samples. However, these approaches often directly apply language modeling techniques to gene sequences and do not fully consider the intrinsic information organization in them, where they do not consider how units at different granularities contribute to representation. In this paper, we propose DNAZEN, an enhanced genomic representation framework designed to learn from various granularities in gene sequences, including small polymers and G-grams that are combinations of several contiguous polymers. Specifically, we extract the G-grams from large-scale genomic corpora through an unsupervised approach to construct the G-gram vocabulary, which is used to provide G-grams in the learning process of DNA sequences through dynamically matching from running gene samples. A Transformer-based G-gram encoder is also proposed and the matched G-grams are fed into it to compute their representations and integrated into the encoder for basic unit (E4BU), which is responsible for encoding small units and maintaining the learning and inference process. To further enhance the learning process, we propose whole G-gram masking to train DNAZEN, where the model largely favors the selection of each entire G-gram to mask rather than an ordinary masking mechanism performed on basic units. Experiments on benchmark datasets demonstrate the effectiveness of DNAZEN on various downstream tasks.
Advancing Weight and Channel Sparsification with Enhanced Saliency
Feb 05, 2025



Pruning aims to accelerate and compress models by removing redundant parameters, identified by specifically designed importance scores which are usually imperfect. This removal is irreversible, often leading to subpar performance in pruned models. Dynamic sparse training, while attempting to adjust sparse structures during training for continual reassessment and refinement, has several limitations including criterion inconsistency between pruning and growth, unsuitability for structured sparsity, and short-sighted growth strategies. Our paper introduces an efficient, innovative paradigm to enhance a given importance criterion for either unstructured or structured sparsity. Our method separates the model into an active structure for exploitation and an exploration space for potential updates. During exploitation, we optimize the active structure, whereas in exploration, we reevaluate and reintegrate parameters from the exploration space through a pruning and growing step consistently guided by the same given importance criterion. To prepare for exploration, we briefly "reactivate" all parameters in the exploration space and train them for a few iterations while keeping the active part frozen, offering a preview of the potential performance gains from reintegrating these parameters. We show on various datasets and configurations that existing importance criterion even simple as magnitude can be enhanced with ours to achieve state-of-the-art performance and training cost reductions. Notably, on ImageNet with ResNet50, ours achieves an +1.3 increase in Top-1 accuracy over prior art at 90% ERK sparsity. Compared with the SOTA latency pruning method HALP, we reduced its training cost by over 70% while attaining a faster and more accurate pruned model.
Step Out and Seek Around: On Warm-Start Training with Incremental Data
Jun 06, 2024



Data often arrives in sequence over time in real-world deep learning applications such as autonomous driving. When new training data is available, training the model from scratch undermines the benefit of leveraging the learned knowledge, leading to significant training costs. Warm-starting from a previously trained checkpoint is the most intuitive way to retain knowledge and advance learning. However, existing literature suggests that this warm-starting degrades generalization. In this paper, we advocate for warm-starting but stepping out of the previous converging point, thus allowing a better adaptation to new data without compromising previous knowledge. We propose Knowledge Consolidation and Acquisition (CKCA), a continuous model improvement algorithm with two novel components. First, a novel feature regularization (FeatReg) to retain and refine knowledge from existing checkpoints; Second, we propose adaptive knowledge distillation (AdaKD), a novel approach to forget mitigation and knowledge transfer. We tested our method on ImageNet using multiple splits of the training data. Our approach achieves up to $8.39\%$ higher top1 accuracy than the vanilla warm-starting and consistently outperforms the prior art with a large margin.
Structural Pruning via Latency-Saliency Knapsack
Oct 18, 2022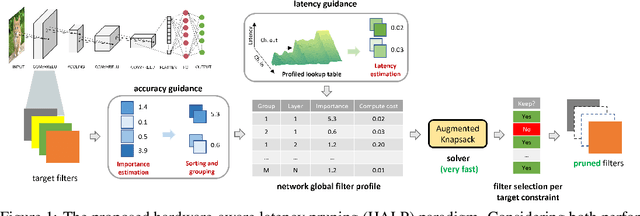
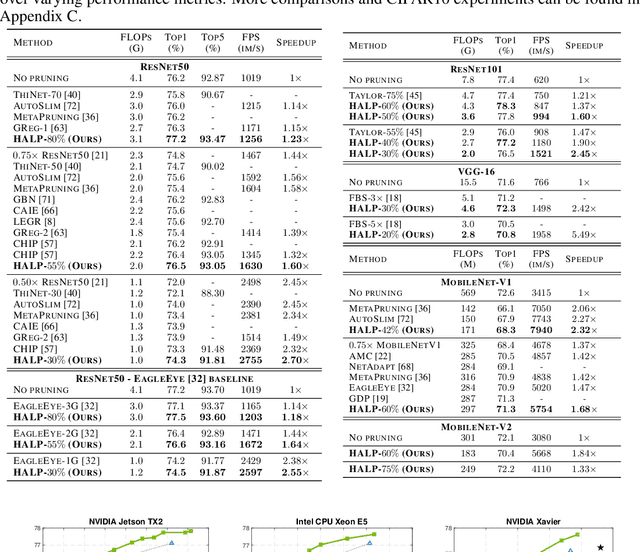
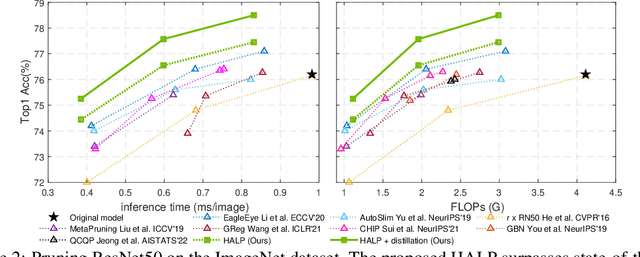
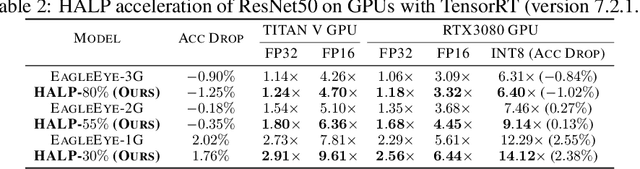
Structural pruning can simplify network architecture and improve inference speed. We propose Hardware-Aware Latency Pruning (HALP) that formulates structural pruning as a global resource allocation optimization problem, aiming at maximizing the accuracy while constraining latency under a predefined budget on targeting device. For filter importance ranking, HALP leverages latency lookup table to track latency reduction potential and global saliency score to gauge accuracy drop. Both metrics can be evaluated very efficiently during pruning, allowing us to reformulate global structural pruning under a reward maximization problem given target constraint. This makes the problem solvable via our augmented knapsack solver, enabling HALP to surpass prior work in pruning efficacy and accuracy-efficiency trade-off. We examine HALP on both classification and detection tasks, over varying networks, on ImageNet and VOC datasets, on different platforms. In particular, for ResNet-50/-101 pruning on ImageNet, HALP improves network throughput by $1.60\times$/$1.90\times$ with $+0.3\%$/$-0.2\%$ top-1 accuracy changes, respectively. For SSD pruning on VOC, HALP improves throughput by $1.94\times$ with only a $0.56$ mAP drop. HALP consistently outperforms prior art, sometimes by large margins. Project page at https://halp-neurips.github.io/.
Reinforcement Learning in Factored Action Spaces using Tensor Decompositions
Oct 27, 2021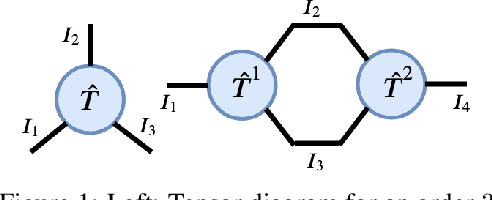
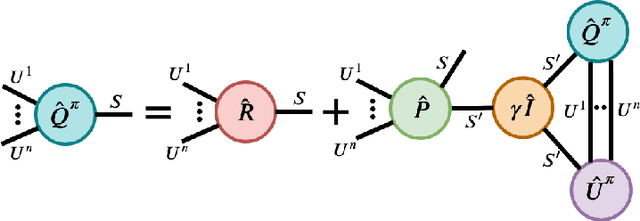
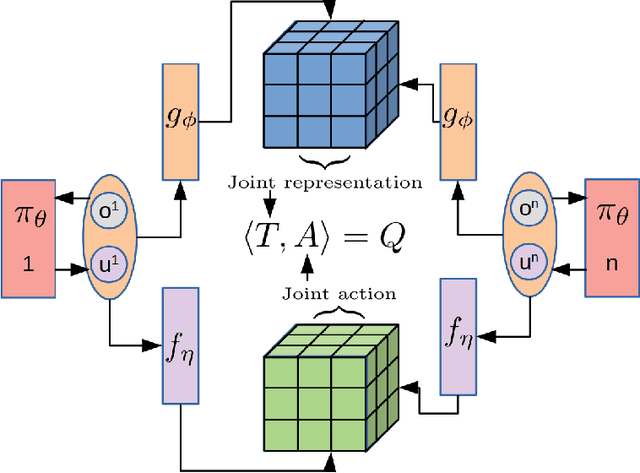
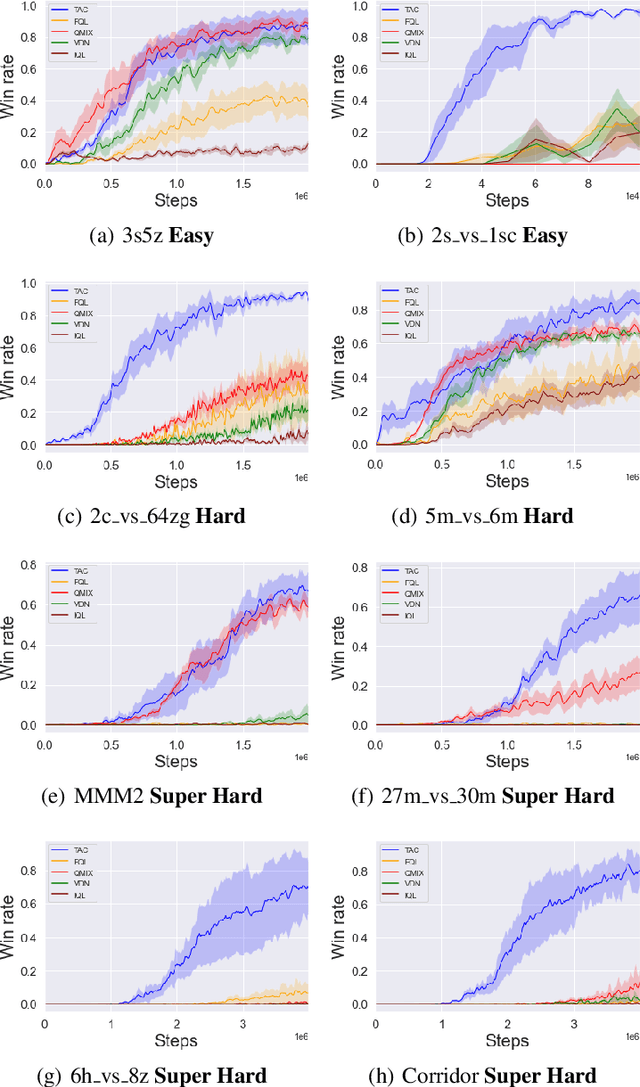
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.
HALP: Hardware-Aware Latency Pruning
Oct 20, 2021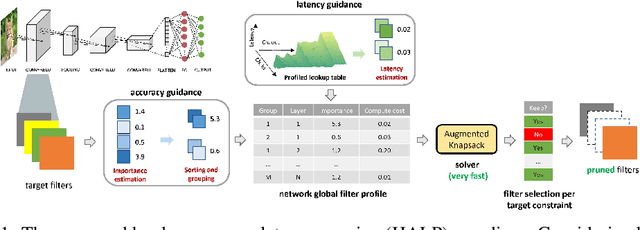
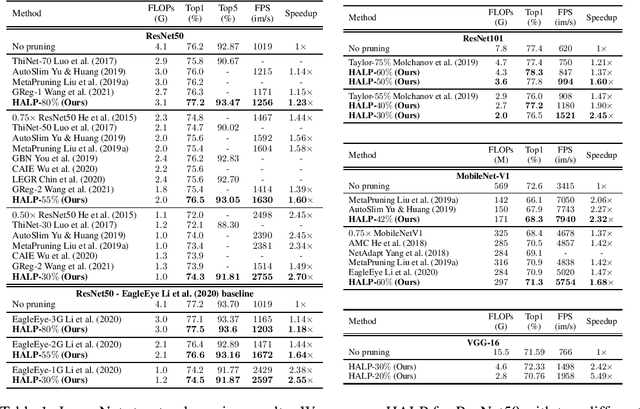
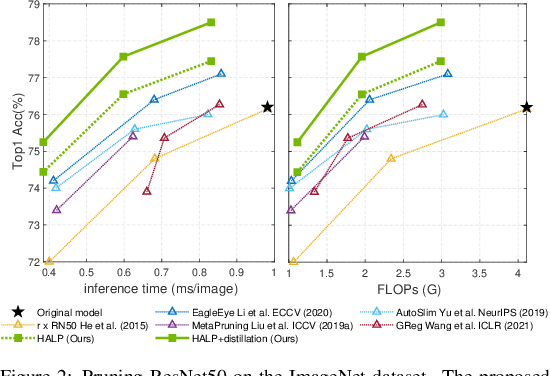
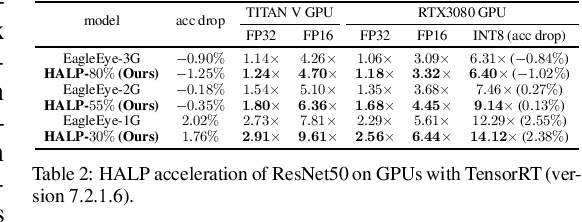
Structural pruning can simplify network architecture and improve inference speed. We propose Hardware-Aware Latency Pruning (HALP) that formulates structural pruning as a global resource allocation optimization problem, aiming at maximizing the accuracy while constraining latency under a predefined budget. For filter importance ranking, HALP leverages latency lookup table to track latency reduction potential and global saliency score to gauge accuracy drop. Both metrics can be evaluated very efficiently during pruning, allowing us to reformulate global structural pruning under a reward maximization problem given target constraint. This makes the problem solvable via our augmented knapsack solver, enabling HALP to surpass prior work in pruning efficacy and accuracy-efficiency trade-off. We examine HALP on both classification and detection tasks, over varying networks, on ImageNet and VOC datasets. In particular, for ResNet-50/-101 pruning on ImageNet, HALP improves network throughput by $1.60\times$/$1.90\times$ with $+0.3\%$/$-0.2\%$ top-1 accuracy changes, respectively. For SSD pruning on VOC, HALP improves throughput by $1.94\times$ with only a $0.56$ mAP drop. HALP consistently outperforms prior art, sometimes by large margins.
Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning
May 31, 2021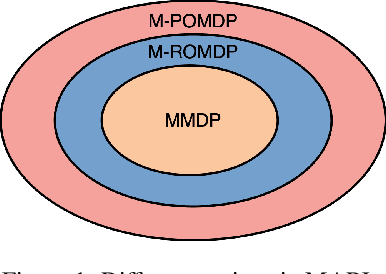
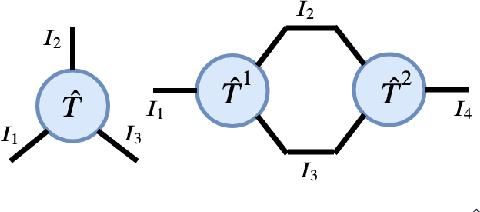
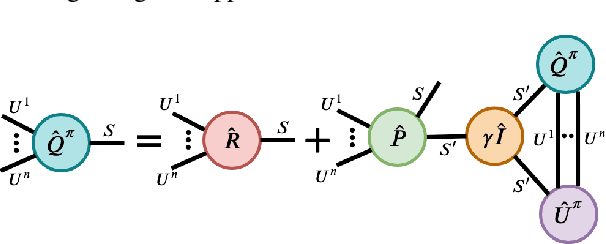
Reinforcement Learning in large action spaces is a challenging problem. Cooperative multi-agent reinforcement learning (MARL) exacerbates matters by imposing various constraints on communication and observability. In this work, we consider the fundamental hurdle affecting both value-based and policy-gradient approaches: an exponential blowup of the action space with the number of agents. For value-based methods, it poses challenges in accurately representing the optimal value function. For policy gradient methods, it makes training the critic difficult and exacerbates the problem of the lagging critic. We show that from a learning theory perspective, both problems can be addressed by accurately representing the associated action-value function with a low-complexity hypothesis class. This requires accurately modelling the agent interactions in a sample efficient way. To this end, we propose a novel tensorised formulation of the Bellman equation. This gives rise to our method Tesseract, which views the Q-function as a tensor whose modes correspond to the action spaces of different agents. Algorithms derived from Tesseract decompose the Q-tensor across agents and utilise low-rank tensor approximations to model agent interactions relevant to the task. We provide PAC analysis for Tesseract-based algorithms and highlight their relevance to the class of rich observation MDPs. Empirical results in different domains confirm Tesseract's gains in sample efficiency predicted by the theory.
Bongard-LOGO: A New Benchmark for Human-Level Concept Learning and Reasoning
Oct 02, 2020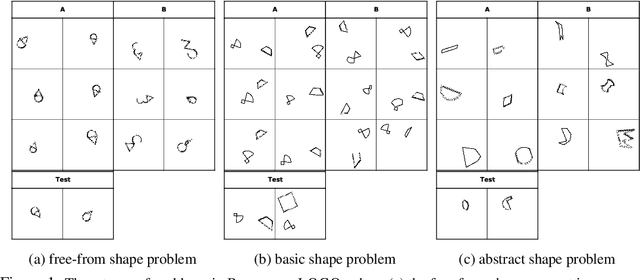
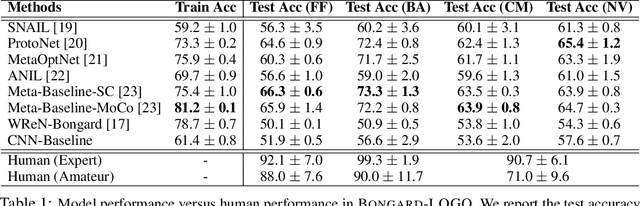
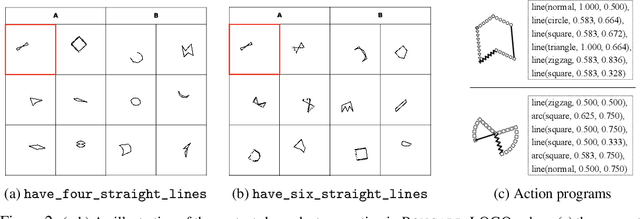
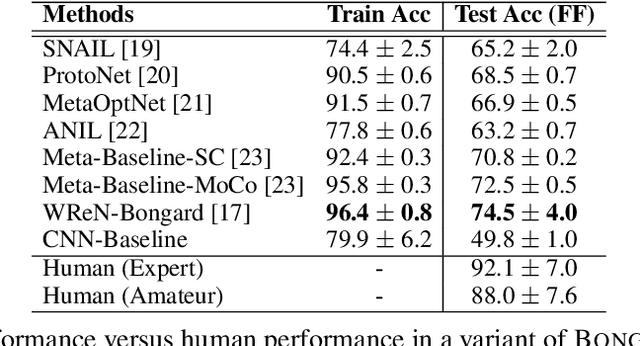
Humans have an inherent ability to learn novel concepts from only a few samples and generalize these concepts to different situations. Even though today's machine learning models excel with a plethora of training data on standard recognition tasks, a considerable gap exists between machine-level pattern recognition and human-level concept learning. To narrow this gap, the Bongard Problems (BPs) were introduced as an inspirational challenge for visual cognition in intelligent systems. Albeit new advances in representation learning and learning to learn, BPs remain a daunting challenge for modern AI. Inspired by the original one hundred BPs, we propose a new benchmark Bongard-LOGO for human-level concept learning and reasoning. We develop a program-guided generation technique to produce a large set of human-interpretable visual cognition problems in action-oriented LOGO language. Our benchmark captures three core properties of human cognition: 1) context-dependent perception, in which the same object may have disparate interpretations given different contexts; 2) analogy-making perception, in which some meaningful concepts are traded off for other meaningful concepts; and 3) perception with a few samples but infinite vocabulary. In experiments, we show that the state-of-the-art deep learning methods perform substantially worse than human subjects, implying that they fail to capture core human cognition properties. Finally, we discuss research directions towards a general architecture for visual reasoning to tackle this benchmark.