 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025



Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
Oct 31, 2025Underwater exploration offers critical insights into our planet and attracts increasing attention for its broader applications in resource exploration, national security, etc. We study the underwater scene understanding methods, which aim to achieve automated underwater exploration. The underwater scene understanding task demands multi-task perceptions from multiple granularities. However, the absence of large-scale underwater multi-task instruction-tuning datasets hinders the progress of this research. To bridge this gap, we construct NautData, a dataset containing 1.45 M image-text pairs supporting eight underwater scene understanding tasks. It enables the development and thorough evaluation of the underwater scene understanding models. Underwater image degradation is a widely recognized challenge that interferes with underwater tasks. To improve the robustness of underwater scene understanding, we introduce physical priors derived from underwater imaging models and propose a plug-and-play vision feature enhancement (VFE) module, which explicitly restores clear underwater information. We integrate this module into renowned baselines LLaVA-1.5 and Qwen2.5-VL and build our underwater LMM, NAUTILUS. Experiments conducted on the NautData and public underwater datasets demonstrate the effectiveness of the VFE module, consistently improving the performance of both baselines on the majority of supported tasks, thus ensuring the superiority of NAUTILUS in the underwater scene understanding area. Data and models are available at https://github.com/H-EmbodVis/NAUTILUS.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025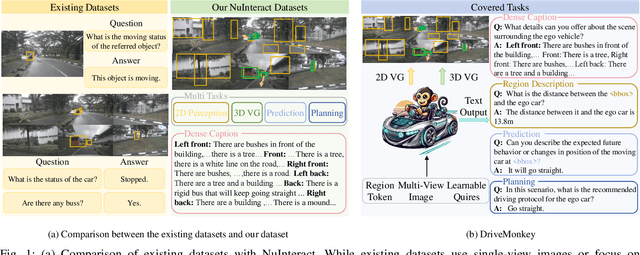

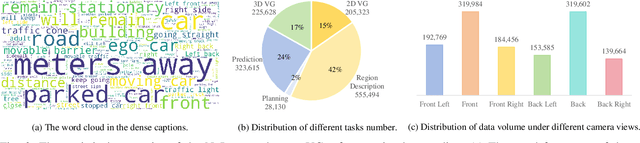
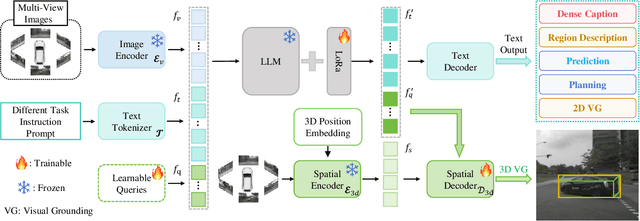
The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.