 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Multi-View Stereo Methods for Photogrammetric 3D Reconstruction: From Traditional to Learning-Based Approaches
Apr 11, 2026Photogrammetric 3D reconstruction has long relied on traditional Structure-from-Motion (SfM) and Multi-View Stereo (MVS) methods, which provide high accuracy but face challenges in speed and scalability. Recently, learning-based MVS methods have emerged, aiming for faster and more efficient reconstruction. This work presents a comparative evaluation between a representative traditional MVS pipeline (COLMAP) and state-of-the-art learning-based approaches, including geometry-guided methods (MVSNet, PatchmatchNet, MVSAnywhere, MVSFormer++) and end-to-end frameworks (Stereo4D, FoundationStereo, DUSt3R, MASt3R, Fast3R, VGGT). Two experiments were conducted on different aerial scenarios. The first experiment used the MARS-LVIG dataset, where ground-truth 3D reconstruction was provided by LiDAR point clouds. The second experiment used a public scene from the Pix4D official website, with ground truth generated by Pix4Dmapper. We evaluated accuracy, coverage, and runtime across all methods. Experimental results show that although COLMAP can provide reliable and geometrically consistent reconstruction results, it requires more computation time. In cases where traditional methods fail in image registration, learning-based approaches exhibit stronger feature-matching capability and greater robustness. Geometry-guided methods usually require careful dataset preparation and often depend on camera pose or depth priors generated by COLMAP. End-to-end methods such as DUSt3R and VGGT achieve competitive accuracy and reasonable coverage while offering substantially faster reconstruction. However, they exhibit relatively large residuals in 3D reconstruction, particularly in challenging scenarios.
ZeD-MAP: Bundle Adjustment Guided Zero-Shot Depth Maps for Real-Time Aerial Imaging
Apr 06, 2026Real-time depth reconstruction from ultra-high-resolution UAV imagery is essential for time-critical geospatial tasks such as disaster response, yet remains challenging due to wide-baseline parallax, large image sizes, low-texture or specular surfaces, occlusions, and strict computational constraints. Recent zero-shot diffusion models offer fast per-image dense predictions without task-specific retraining, and require fewer labelled datasets than transformer-based predictors while avoiding the rigid capture geometry requirement of classical multi-view stereo. However, their probabilistic inference prevents reliable metric accuracy and temporal consistency across sequential frames and overlapping tiles. We present ZeD-MAP, a cluster-level framework that converts a test-time diffusion depth model into a metrically consistent, SLAM-like mapping pipeline by integrating incremental cluster-based bundle adjustment (BA). Streamed UAV frames are grouped into overlapping clusters; periodic BA produces metrically consistent poses and sparse 3D tie-points, which are reprojected into selected frames and used as metric guidance for diffusion-based depth estimation. Validation on ground-marker flights captured at approximately 50 m altitude (GSD is approximately 0.85 cm/px, corresponding to 2,650 square meters ground coverage per frame) with the DLR Modular Aerial Camera System (MACS) shows that our method achieves sub-meter accuracy, with approximately 0.87 m error in the horizontal (XY) plane and 0.12 m in the vertical (Z) direction, while maintaining per-image runtimes between 1.47 and 4.91 seconds. Results are subject to minor noise from manual point-cloud annotation. These findings show that BA-based metric guidance provides consistency comparable to classical photogrammetric methods while significantly accelerating processing, enabling real-time 3D map generation.
DriveVA: Video Action Models are Zero-Shot Drivers
Apr 05, 2026Generalization is a central challenge in autonomous driving, as real-world deployment requires robust performance under unseen scenarios, sensor domains, and environmental conditions. Recent world-model-based planning methods have shown strong capabilities in scene understanding and multi-modal future prediction, yet their generalization across datasets and sensor configurations remains limited. In addition, their loosely coupled planning paradigm often leads to poor video-trajectory consistency during visual imagination. To overcome these limitations, we propose DriveVA, a novel autonomous driving world model that jointly decodes future visual forecasts and action sequences in a shared latent generative process. DriveVA inherits rich priors on motion dynamics and physical plausibility from well-pretrained large-scale video generation models to capture continuous spatiotemporal evolution and causal interaction patterns. To this end, DriveVA employs a DiT-based decoder to jointly predict future action sequences (trajectories) and videos, enabling tighter alignment between planning and scene evolution. We also introduce a video continuation strategy to strengthen long-duration rollout consistency. DriveVA achieves an impressive closed-loop performance of 90.9 PDM score on the challenge NAVSIM. Extensive experiments also demonstrate the zero-shot capability and cross-domain generalization of DriveVA, which reduces average L2 error and collision rate by 78.9% and 83.3% on nuScenes and 52.5% and 52.4% on the Bench2drive built on CARLA v2 compared with the state-of-the-art world-model-based planner.
M2H-MX: Multi-Task Dense Visual Perception for Real-Time Monocular Spatial Understanding
Mar 31, 2026Monocular cameras are attractive for robotic perception due to their low cost and ease of deployment, yet achieving reliable real-time spatial understanding from a single image stream remains challenging. While recent multi-task dense prediction models have improved per-pixel depth and semantic estimation, translating these advances into stable monocular mapping systems is still non-trivial. This paper presents M2H-MX, a real-time multi-task perception model for monocular spatial understanding. The model preserves multi-scale feature representations while introducing register-gated global context and controlled cross-task interaction in a lightweight decoder, enabling depth and semantic predictions to reinforce each other under strict latency constraints. Its outputs integrate directly into an unmodified monocular SLAM pipeline through a compact perception-to-mapping interface. We evaluate both dense prediction accuracy and in-the-loop system performance. On NYUDv2, M2H-MX-L achieves state-of-the-art results, improving semantic mIoU by 6.6% and reducing depth RMSE by 9.4% over representative multi-task baselines. When deployed in a real-time monocular mapping system on ScanNet, M2H-MX reduces average trajectory error by 60.7% compared to a strong monocular SLAM baseline while producing cleaner metric-semantic maps. These results demonstrate that modern multi-task dense prediction can be reliably deployed for real-time monocular spatial perception in robotic systems.
4DSTR: Advancing Generative 4D Gaussians with Spatial-Temporal Rectification for High-Quality and Consistent 4D Generation
Nov 10, 2025Remarkable advances in recent 2D image and 3D shape generation have induced a significant focus on dynamic 4D content generation. However, previous 4D generation methods commonly struggle to maintain spatial-temporal consistency and adapt poorly to rapid temporal variations, due to the lack of effective spatial-temporal modeling. To address these problems, we propose a novel 4D generation network called 4DSTR, which modulates generative 4D Gaussian Splatting with spatial-temporal rectification. Specifically, temporal correlation across generated 4D sequences is designed to rectify deformable scales and rotations and guarantee temporal consistency. Furthermore, an adaptive spatial densification and pruning strategy is proposed to address significant temporal variations by dynamically adding or deleting Gaussian points with the awareness of their pre-frame movements. Extensive experiments demonstrate that our 4DSTR achieves state-of-the-art performance in video-to-4D generation, excelling in reconstruction quality, spatial-temporal consistency, and adaptation to rapid temporal movements.
Real-Time Bundle Adjustment for Ultra-High-Resolution UAV Imagery Using Adaptive Patch-Based Feature Tracking
Nov 08, 2025Real-time processing of UAV imagery is crucial for applications requiring urgent geospatial information, such as disaster response, where rapid decision-making and accurate spatial data are essential. However, processing high-resolution imagery in real time presents significant challenges due to the computational demands of feature extraction, matching, and bundle adjustment (BA). Conventional BA methods either downsample images, sacrificing important details, or require extensive processing time, making them unsuitable for time-critical missions. To overcome these limitations, we propose a novel real-time BA framework that operates directly on fullresolution UAV imagery without downsampling. Our lightweight, onboard-compatible approach divides each image into user-defined patches (e.g., NxN grids, default 150x150 pixels) and dynamically tracks them across frames using UAV GNSS/IMU data and a coarse, globally available digital surface model (DSM). This ensures spatial consistency for robust feature extraction and matching between patches. Overlapping relationships between images are determined in real time using UAV navigation system, enabling the rapid selection of relevant neighbouring images for localized BA. By limiting optimization to a sliding cluster of overlapping images, including those from adjacent flight strips, the method achieves real-time performance while preserving the accuracy of global BA. The proposed algorithm is designed for seamless integration into the DLR Modular Aerial Camera System (MACS), supporting largearea mapping in real time for disaster response, infrastructure monitoring, and coastal protection. Validation on MACS datasets with 50MP images demonstrates that the method maintains precise camera orientations and high-fidelity mapping across multiple strips, running full bundle adjustment in under 2 seconds without GPU acceleration.
TopoLiDM: Topology-Aware LiDAR Diffusion Models for Interpretable and Realistic LiDAR Point Cloud Generation
Jul 30, 2025LiDAR scene generation is critical for mitigating real-world LiDAR data collection costs and enhancing the robustness of downstream perception tasks in autonomous driving. However, existing methods commonly struggle to capture geometric realism and global topological consistency. Recent LiDAR Diffusion Models (LiDMs) predominantly embed LiDAR points into the latent space for improved generation efficiency, which limits their interpretable ability to model detailed geometric structures and preserve global topological consistency. To address these challenges, we propose TopoLiDM, a novel framework that integrates graph neural networks (GNNs) with diffusion models under topological regularization for high-fidelity LiDAR generation. Our approach first trains a topological-preserving VAE to extract latent graph representations by graph construction and multiple graph convolutional layers. Then we freeze the VAE and generate novel latent topological graphs through the latent diffusion models. We also introduce 0-dimensional persistent homology (PH) constraints, ensuring the generated LiDAR scenes adhere to real-world global topological structures. Extensive experiments on the KITTI-360 dataset demonstrate TopoLiDM's superiority over state-of-the-art methods, achieving improvements of 22.6% lower Frechet Range Image Distance (FRID) and 9.2% lower Minimum Matching Distance (MMD). Notably, our model also enables fast generation speed with an average inference time of 1.68 samples/s, showcasing its scalability for real-world applications. We will release the related codes at https://github.com/IRMVLab/TopoLiDM.
Channel-Aware Distillation Transformer for Depth Estimation on Nano Drones
Mar 18, 2023Autonomous navigation of drones using computer vision has achieved promising performance. Nano-sized drones based on edge computing platforms are lightweight, flexible, and cheap, thus suitable for exploring narrow spaces. However, due to their extremely limited computing power and storage, vision algorithms designed for high-performance GPU platforms cannot be used for nano drones. To address this issue this paper presents a lightweight CNN depth estimation network deployed on nano drones for obstacle avoidance. Inspired by Knowledge Distillation (KD), a Channel-Aware Distillation Transformer (CADiT) is proposed to facilitate the small network to learn knowledge from a larger network. The proposed method is validated on the KITTI dataset and tested on a nano drone Crazyflie, with an ultra-low power microprocessor GAP8.
Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation
Nov 23, 2022



Self-supervised monocular depth estimation that does not require ground-truth for training has attracted attention in recent years. It is of high interest to design lightweight but effective models, so that they can be deployed on edge devices. Many existing architectures benefit from using heavier backbones at the expense of model sizes. In this paper we achieve comparable results with a lightweight architecture. Specifically, we investigate the efficient combination of CNNs and Transformers, and design a hybrid architecture Lite-Mono. A Consecutive Dilated Convolutions (CDC) module and a Local-Global Features Interaction (LGFI) module are proposed. The former is used to extract rich multi-scale local features, and the latter takes advantage of the self-attention mechanism to encode long-range global information into the features. Experiments demonstrate that our full model outperforms Monodepth2 by a large margin in accuracy, with about 80% fewer trainable parameters.
Self-supervised monocular depth estimation from oblique UAV videos
Dec 19, 2020
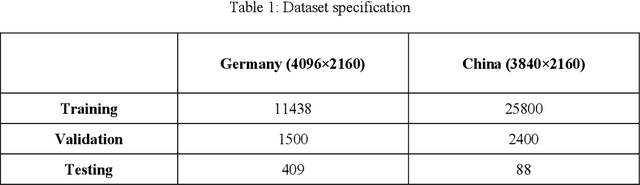
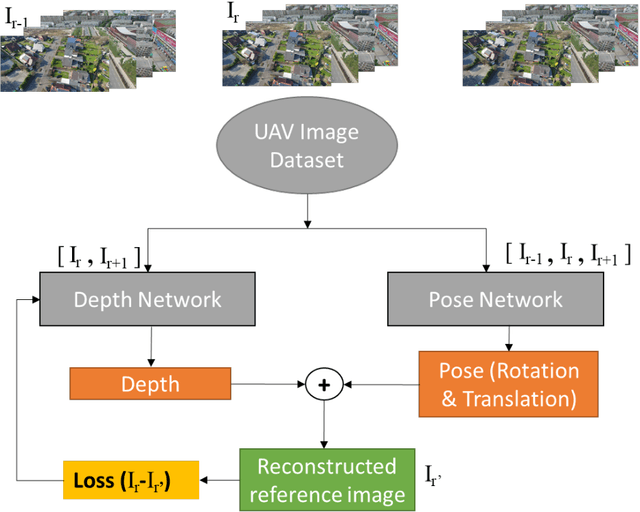
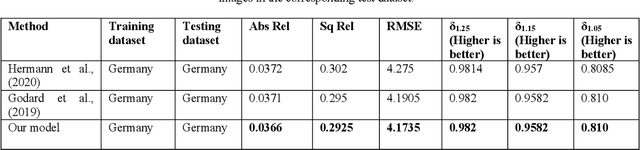
UAVs have become an essential photogrammetric measurement as they are affordable, easily accessible and versatile. Aerial images captured from UAVs have applications in small and large scale texture mapping, 3D modelling, object detection tasks, DTM and DSM generation etc. Photogrammetric techniques are routinely used for 3D reconstruction from UAV images where multiple images of the same scene are acquired. Developments in computer vision and deep learning techniques have made Single Image Depth Estimation (SIDE) a field of intense research. Using SIDE techniques on UAV images can overcome the need for multiple images for 3D reconstruction. This paper aims to estimate depth from a single UAV aerial image using deep learning. We follow a self-supervised learning approach, Self-Supervised Monocular Depth Estimation (SMDE), which does not need ground truth depth or any extra information other than images for learning to estimate depth. Monocular video frames are used for training the deep learning model which learns depth and pose information jointly through two different networks, one each for depth and pose. The predicted depth and pose are used to reconstruct one image from the viewpoint of another image utilising the temporal information from videos. We propose a novel architecture with two 2D CNN encoders and a 3D CNN decoder for extracting information from consecutive temporal frames. A contrastive loss term is introduced for improving the quality of image generation. Our experiments are carried out on the public UAVid video dataset. The experimental results demonstrate that our model outperforms the state-of-the-art methods in estimating the depths.