 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongsheng Li
Parameter is Not All You Need: Starting from Non-Parametric Networks for 3D Point Cloud Analysis
Mar 14, 2023
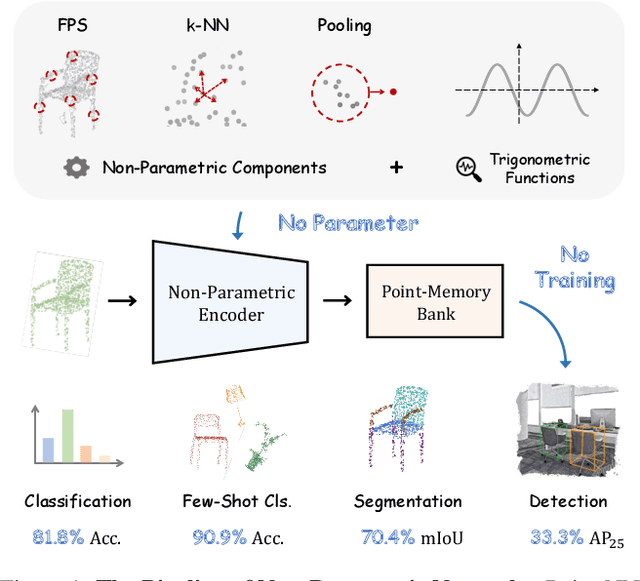
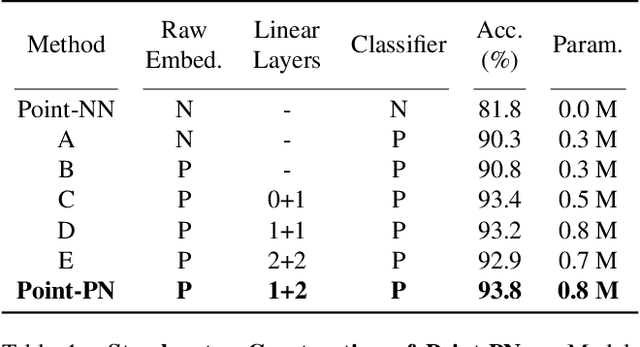
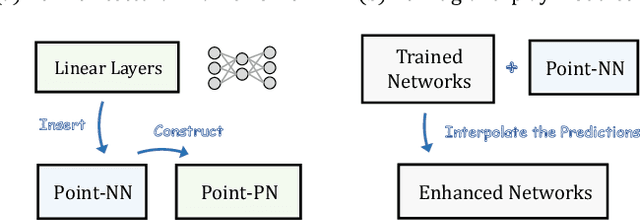
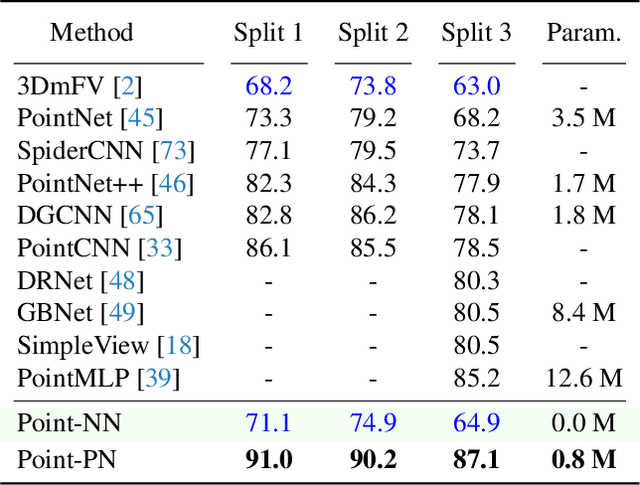
We present a Non-parametric Network for 3D point cloud analysis, Point-NN, which consists of purely non-learnable components: farthest point sampling (FPS), k-nearest neighbors (k-NN), and pooling operations, with trigonometric functions. Surprisingly, it performs well on various 3D tasks, requiring no parameters or training, and even surpasses existing fully trained models. Starting from this basic non-parametric model, we propose two extensions. First, Point-NN can serve as a base architectural framework to construct Parametric Networks by simply inserting linear layers on top. Given the superior non-parametric foundation, the derived Point-PN exhibits a high performance-efficiency trade-off with only a few learnable parameters. Second, Point-NN can be regarded as a plug-and-play module for the already trained 3D models during inference. Point-NN captures the complementary geometric knowledge and enhances existing methods for different 3D benchmarks without re-training. We hope our work may cast a light on the community for understanding 3D point clouds with non-parametric methods. Code is available at https://github.com/ZrrSkywalker/Point-NN.
BlinkFlow: A Dataset to Push the Limits of Event-based Optical Flow Estimation
Mar 14, 2023


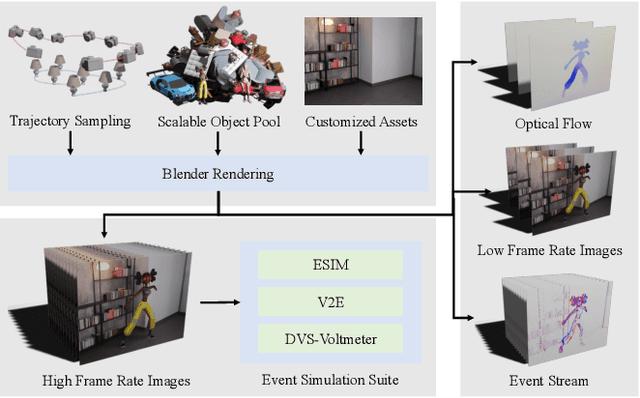
Event cameras provide high temporal precision, low data rates, and high dynamic range visual perception, which are well-suited for optical flow estimation. While data-driven optical flow estimation has obtained great success in RGB cameras, its generalization performance is seriously hindered in event cameras mainly due to the limited and biased training data. In this paper, we present a novel simulator, BlinkSim, for the fast generation of large-scale data for event-based optical flow. BlinkSim consists of a configurable rendering engine and a flexible engine for event data simulation. By leveraging the wealth of current 3D assets, the rendering engine enables us to automatically build up thousands of scenes with different objects, textures, and motion patterns and render very high-frequency images for realistic event data simulation. Based on BlinkSim, we construct a large training dataset and evaluation benchmark BlinkFlow that contains sufficient, diversiform, and challenging event data with optical flow ground truth. Experiments show that BlinkFlow improves the generalization performance of state-of-the-art methods by more than 40% on average and up to 90%. Moreover, we further propose an Event optical Flow transFormer (E-FlowFormer) architecture. Powered by our BlinkFlow, E-FlowFormer outperforms the SOTA methods by up to 91% on MVSEC dataset and 14% on DSEC dataset and presents the best generalization performance.
PATS: Patch Area Transportation with Subdivision for Local Feature Matching
Mar 14, 2023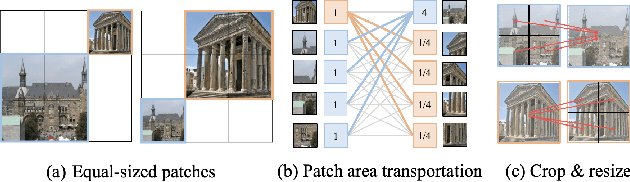

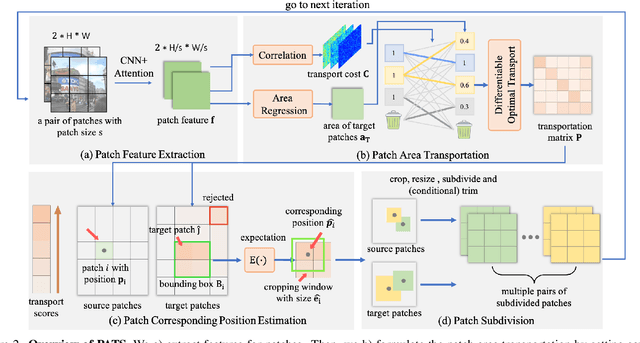
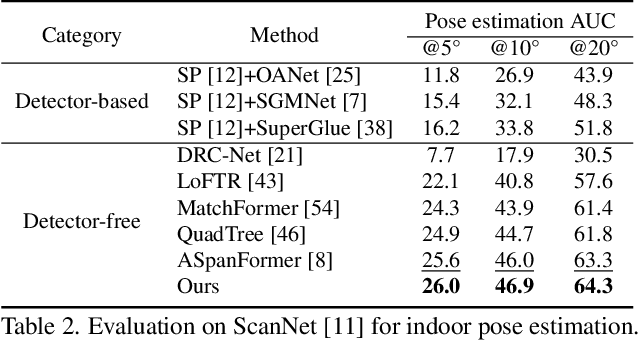
Local feature matching aims at establishing sparse correspondences between a pair of images. Recently, detectorfree methods present generally better performance but are not satisfactory in image pairs with large scale differences. In this paper, we propose Patch Area Transportation with Subdivision (PATS) to tackle this issue. Instead of building an expensive image pyramid, we start by splitting the original image pair into equal-sized patches and gradually resizing and subdividing them into smaller patches with the same scale. However, estimating scale differences between these patches is non-trivial since the scale differences are determined by both relative camera poses and scene structures, and thus spatially varying over image pairs. Moreover, it is hard to obtain the ground truth for real scenes. To this end, we propose patch area transportation, which enables learning scale differences in a self-supervised manner. In contrast to bipartite graph matching, which only handles one-to-one matching, our patch area transportation can deal with many-to-many relationships. PATS improves both matching accuracy and coverage, and shows superior performance in downstream tasks, such as relative pose estimation, visual localization, and optical flow estimation. The source code will be released to benefit the community.
Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Mar 09, 2023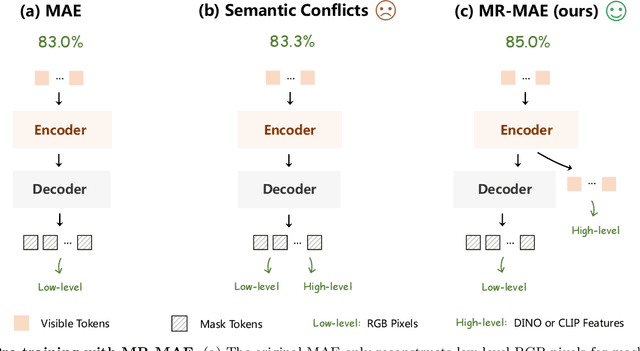
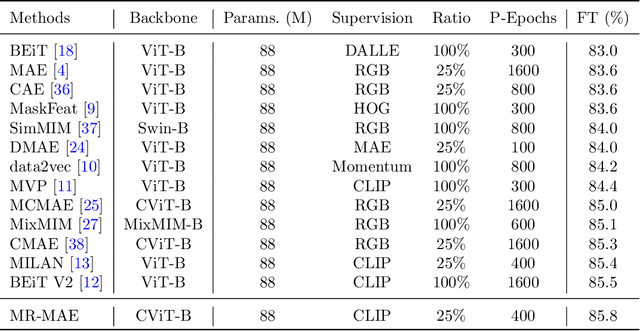
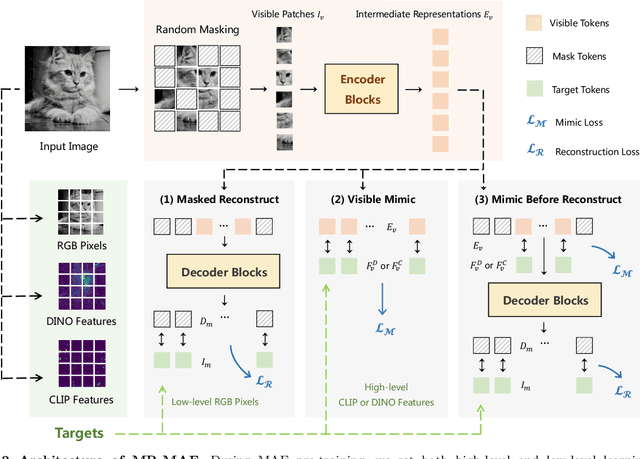
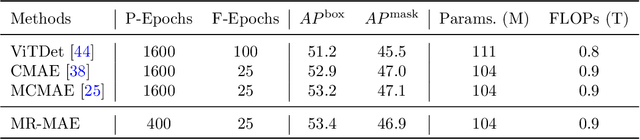
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by +2.2% and the previous state-of-the-art BEiT V2 base by +0.3%. Code and pre-trained models will be released at https://github.com/Alpha-VL/ConvMAE.
KBNet: Kernel Basis Network for Image Restoration
Mar 06, 2023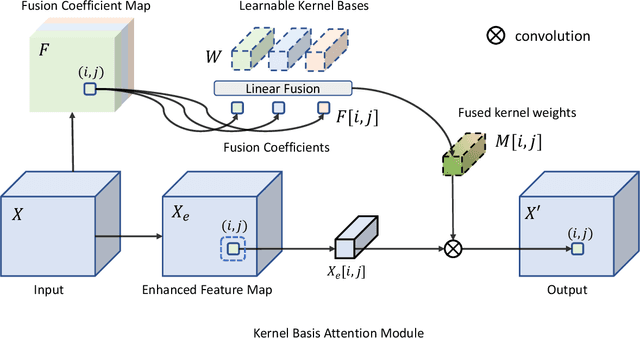
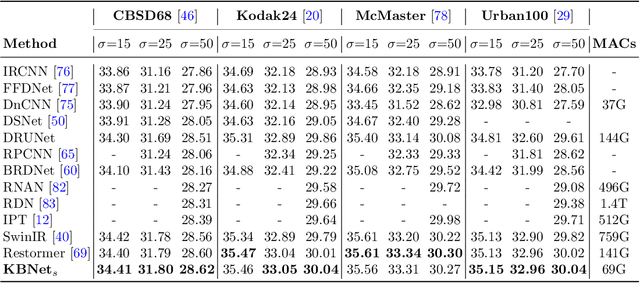
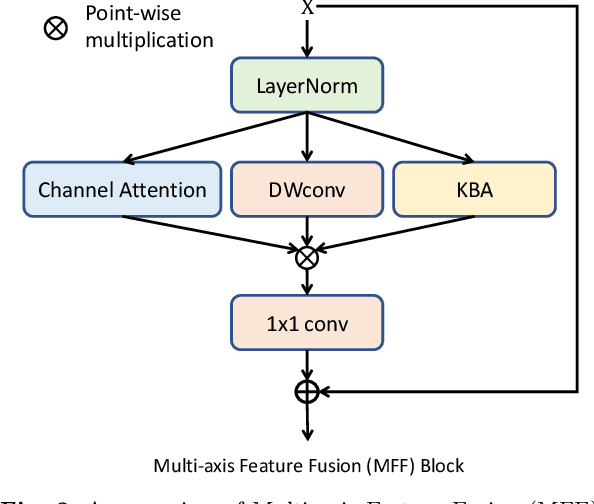
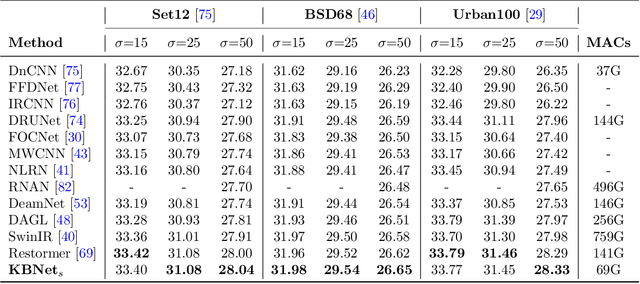
How to aggregate spatial information plays an essential role in learning-based image restoration. Most existing CNN-based networks adopt static convolutional kernels to encode spatial information, which cannot aggregate spatial information adaptively. Recent transformer-based architectures achieve adaptive spatial aggregation. But they lack desirable inductive biases of convolutions and require heavy computational costs. In this paper, we propose a kernel basis attention (KBA) module, which introduces learnable kernel bases to model representative image patterns for spatial information aggregation. Different kernel bases are trained to model different local structures. At each spatial location, they are linearly and adaptively fused by predicted pixel-wise coefficients to obtain aggregation weights. Based on the KBA module, we further design a multi-axis feature fusion (MFF) block to encode and fuse channel-wise, spatial-invariant, and pixel-adaptive features for image restoration. Our model, named kernel basis network (KBNet), achieves state-of-the-art performances on more than ten benchmarks over image denoising, deraining, and deblurring tasks while requiring less computational cost than previous SOTA methods.
Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
Mar 03, 2023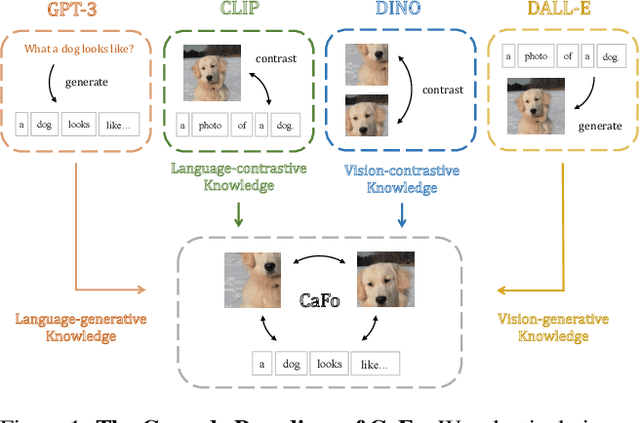
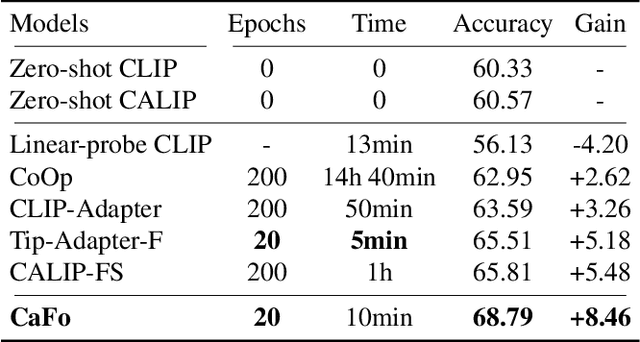
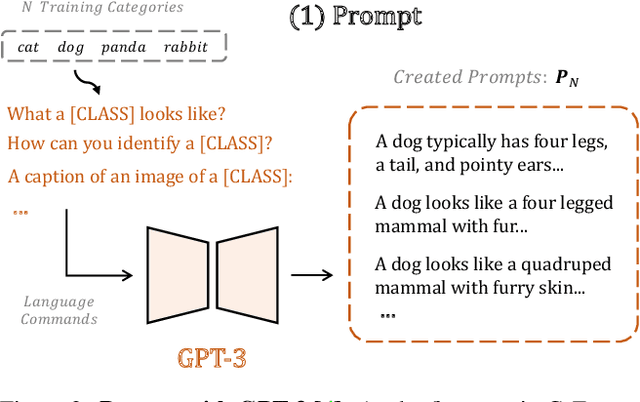
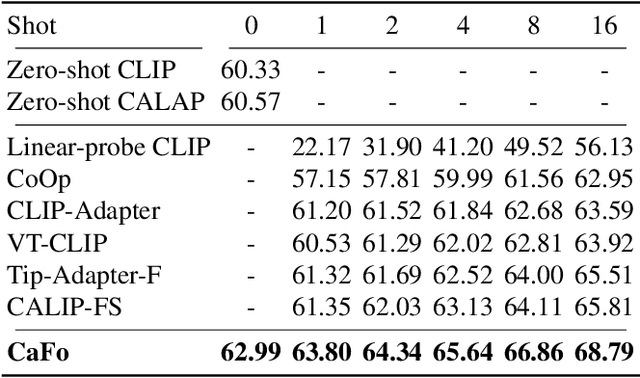
Visual recognition in low-data regimes requires deep neural networks to learn generalized representations from limited training samples. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. We then question, if the more diverse pre-training knowledge can be cascaded to further assist few-shot representation learning. In this paper, we propose CaFo, a Cascade of Foundation models that incorporates diverse prior knowledge of various pre-training paradigms for better few-shot learning. Our CaFo incorporates CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, DALL-E's vision-generative knowledge, and GPT-3's language-generative knowledge. Specifically, CaFo works by 'Prompt, Generate, then Cache'. Firstly, we leverage GPT-3 to produce textual inputs for prompting CLIP with rich downstream linguistic semantics. Then, we generate synthetic images via DALL-E to expand the few-shot training data without any manpower. At last, we introduce a learnable cache model to adaptively blend the predictions from CLIP and DINO. By such collaboration, CaFo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. Code is available at https://github.com/ZrrSkywalker/CaFo.
FeatAug-DETR: Enriching One-to-Many Matching for DETRs with Feature Augmentation
Mar 02, 2023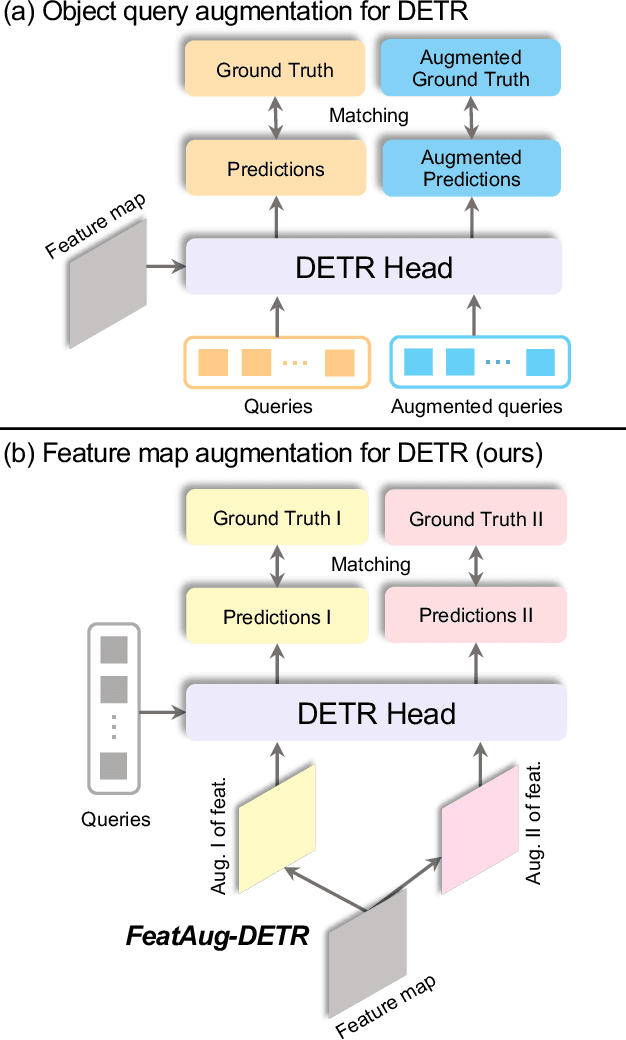
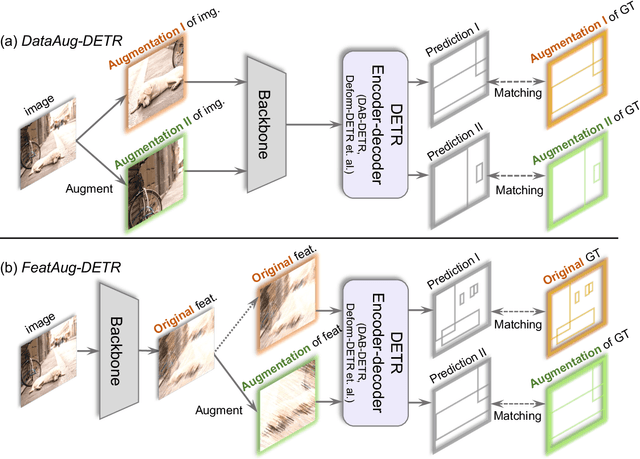
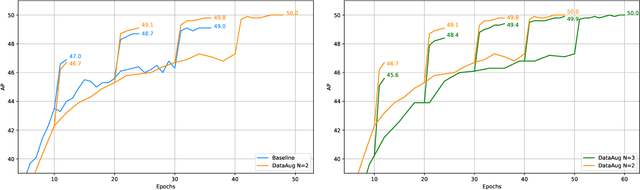
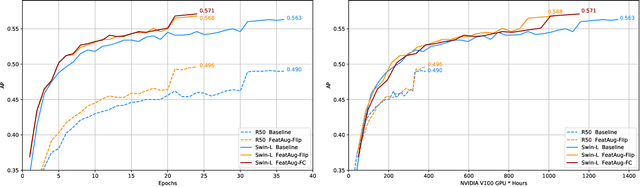
One-to-one matching is a crucial design in DETR-like object detection frameworks. It enables the DETR to perform end-to-end detection. However, it also faces challenges of lacking positive sample supervision and slow convergence speed. Several recent works proposed the one-to-many matching mechanism to accelerate training and boost detection performance. We revisit these methods and model them in a unified format of augmenting the object queries. In this paper, we propose two methods that realize one-to-many matching from a different perspective of augmenting images or image features. The first method is One-to-many Matching via Data Augmentation (denoted as DataAug-DETR). It spatially transforms the images and includes multiple augmented versions of each image in the same training batch. Such a simple augmentation strategy already achieves one-to-many matching and surprisingly improves DETR's performance. The second method is One-to-many matching via Feature Augmentation (denoted as FeatAug-DETR). Unlike DataAug-DETR, it augments the image features instead of the original images and includes multiple augmented features in the same batch to realize one-to-many matching. FeatAug-DETR significantly accelerates DETR training and boosts detection performance while keeping the inference speed unchanged. We conduct extensive experiments to evaluate the effectiveness of the proposed approach on DETR variants, including DAB-DETR, Deformable-DETR, and H-Deformable-DETR. Without extra training data, FeatAug-DETR shortens the training convergence periods of Deformable-DETR to 24 epochs and achieves 58.3 AP on COCO val2017 set with Swin-L as the backbone.
FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation
Mar 02, 2023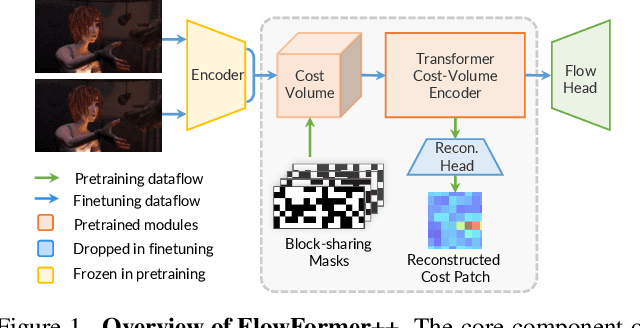
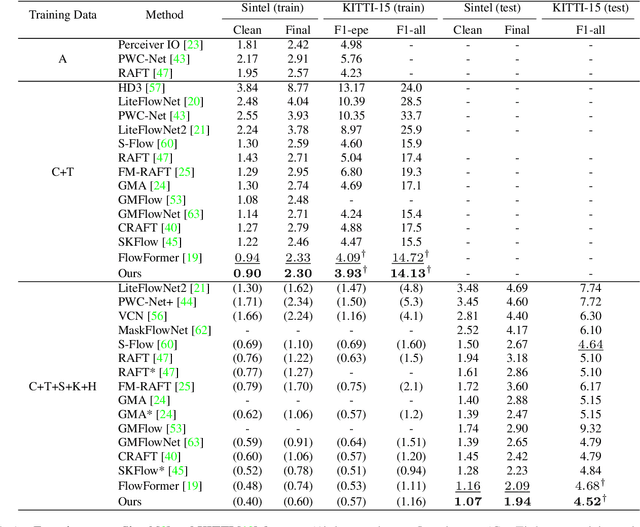
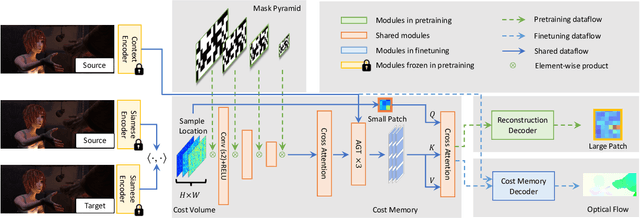
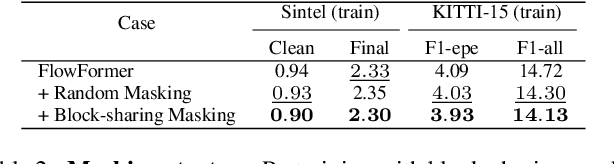
FlowFormer introduces a transformer architecture into optical flow estimation and achieves state-of-the-art performance. The core component of FlowFormer is the transformer-based cost-volume encoder. Inspired by the recent success of masked autoencoding (MAE) pretraining in unleashing transformers' capacity of encoding visual representation, we propose Masked Cost Volume Autoencoding (MCVA) to enhance FlowFormer by pretraining the cost-volume encoder with a novel MAE scheme. Firstly, we introduce a block-sharing masking strategy to prevent masked information leakage, as the cost maps of neighboring source pixels are highly correlated. Secondly, we propose a novel pre-text reconstruction task, which encourages the cost-volume encoder to aggregate long-range information and ensures pretraining-finetuning consistency. We also show how to modify the FlowFormer architecture to accommodate masks during pretraining. Pretrained with MCVA, FlowFormer++ ranks 1st among published methods on both Sintel and KITTI-2015 benchmarks. Specifically, FlowFormer++ achieves 1.07 and 1.94 average end-point error (AEPE) on the clean and final pass of Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer. FlowFormer++ obtains 4.52 F1-all on the KITTI-2015 test set, improving FlowFormer by 0.16.
ConQueR: Query Contrast Voxel-DETR for 3D Object Detection
Dec 14, 2022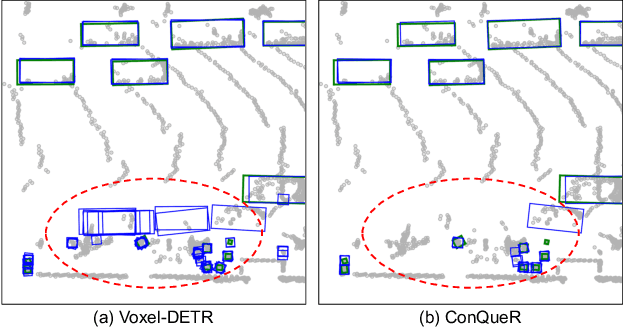
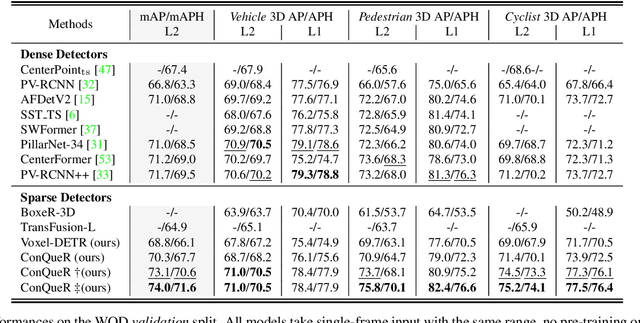
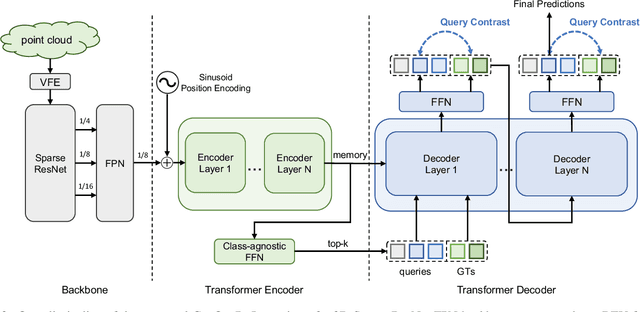
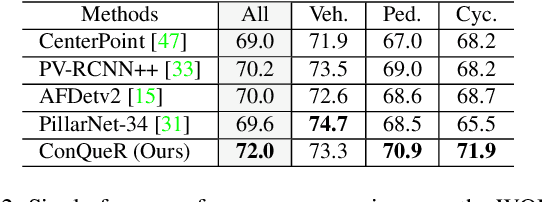
Although DETR-based 3D detectors can simplify the detection pipeline and achieve direct sparse predictions, their performance still lags behind dense detectors with post-processing for 3D object detection from point clouds. DETRs usually adopt a larger number of queries than GTs (e.g., 300 queries v.s. 40 objects in Waymo) in a scene, which inevitably incur many false positives during inference. In this paper, we propose a simple yet effective sparse 3D detector, named Query Contrast Voxel-DETR (ConQueR), to eliminate the challenging false positives, and achieve more accurate and sparser predictions. We observe that most false positives are highly overlapping in local regions, caused by the lack of explicit supervision to discriminate locally similar queries. We thus propose a Query Contrast mechanism to explicitly enhance queries towards their best-matched GTs over all unmatched query predictions. This is achieved by the construction of positive and negative GT-query pairs for each GT, and a contrastive loss to enhance positive GT-query pairs against negative ones based on feature similarities. ConQueR closes the gap of sparse and dense 3D detectors, and reduces up to ~60% false positives. Our single-frame ConQueR achieves new state-of-the-art (sota) 71.6 mAPH/L2 on the challenging Waymo Open Dataset validation set, outperforming previous sota methods (e.g., PV-RCNN++) by over 2.0 mAPH/L2.
Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Dec 13, 2022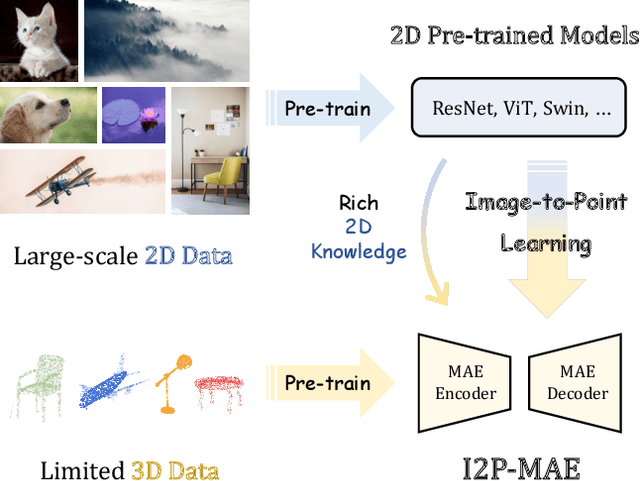
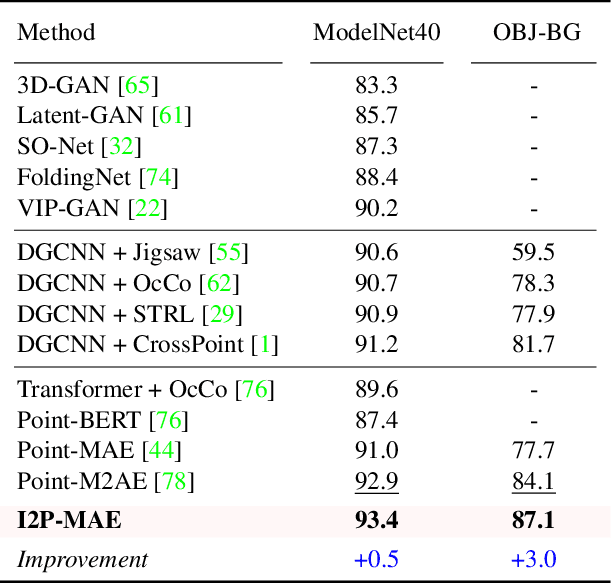
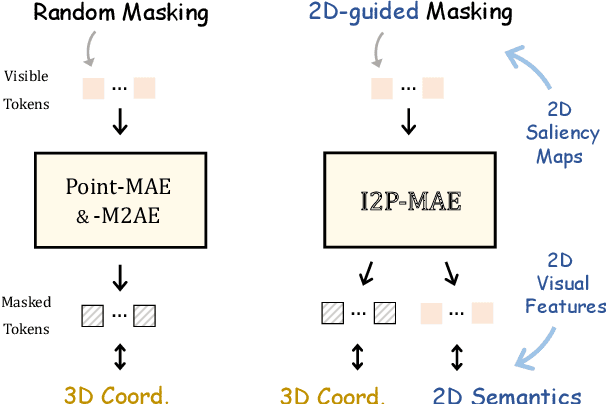
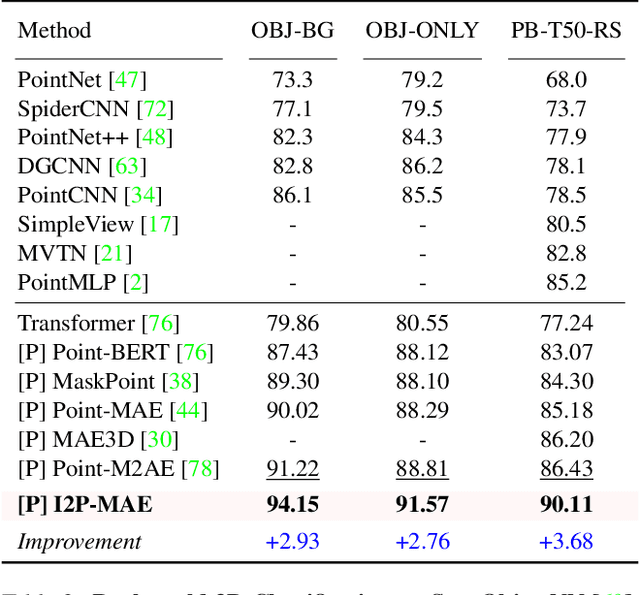
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.