 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUserBench: An Interactive Gym Environment for User-Centric Agents
Jul 29, 2025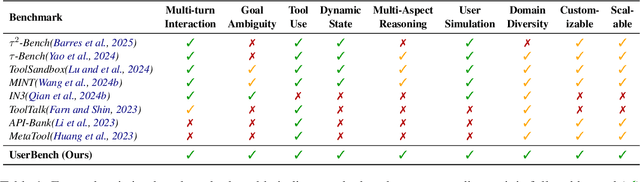


Large Language Models (LLMs)-based agents have made impressive progress in reasoning and tool use, enabling them to solve complex tasks. However, their ability to proactively collaborate with users, especially when goals are vague, evolving, or indirectly expressed, remains underexplored. To address this gap, we introduce UserBench, a user-centric benchmark designed to evaluate agents in multi-turn, preference-driven interactions. UserBench features simulated users who start with underspecified goals and reveal preferences incrementally, requiring agents to proactively clarify intent and make grounded decisions with tools. Our evaluation of leading open- and closed-source LLMs reveals a significant disconnect between task completion and user alignment. For instance, models provide answers that fully align with all user intents only 20% of the time on average, and even the most advanced models uncover fewer than 30% of all user preferences through active interaction. These results highlight the challenges of building agents that are not just capable task executors, but true collaborative partners. UserBench offers an interactive environment to measure and advance this critical capability.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025



Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
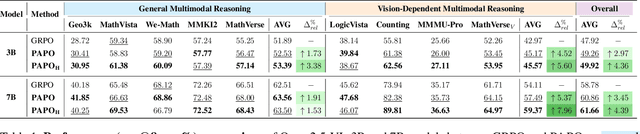
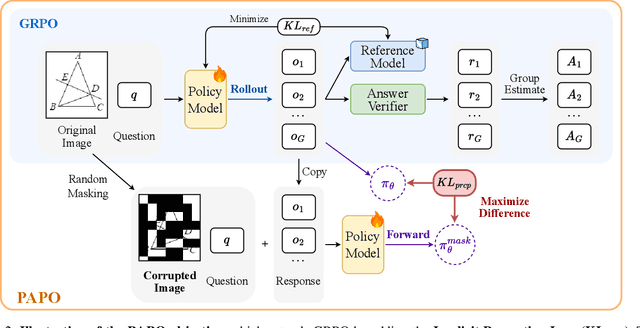
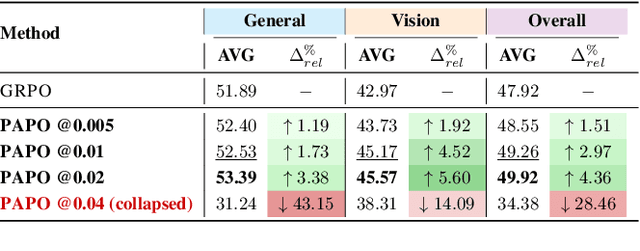
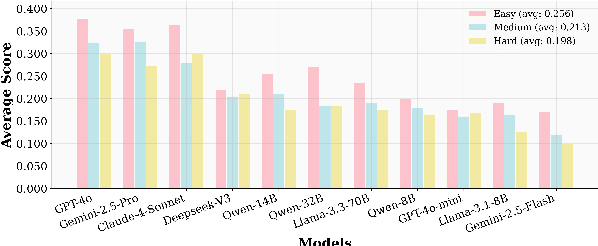
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025



Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
Beyond Reactive Safety: Risk-Aware LLM Alignment via Long-Horizon Simulation
Jun 26, 2025Given the growing influence of language model-based agents on high-stakes societal decisions, from public policy to healthcare, ensuring their beneficial impact requires understanding the far-reaching implications of their suggestions. We propose a proof-of-concept framework that projects how model-generated advice could propagate through societal systems on a macroscopic scale over time, enabling more robust alignment. To assess the long-term safety awareness of language models, we also introduce a dataset of 100 indirect harm scenarios, testing models' ability to foresee adverse, non-obvious outcomes from seemingly harmless user prompts. Our approach achieves not only over 20% improvement on the new dataset but also an average win rate exceeding 70% against strong baselines on existing safety benchmarks (AdvBench, SafeRLHF, WildGuardMix), suggesting a promising direction for safer agents.
ProteinZero: Self-Improving Protein Generation via Online Reinforcement Learning
Jun 09, 2025
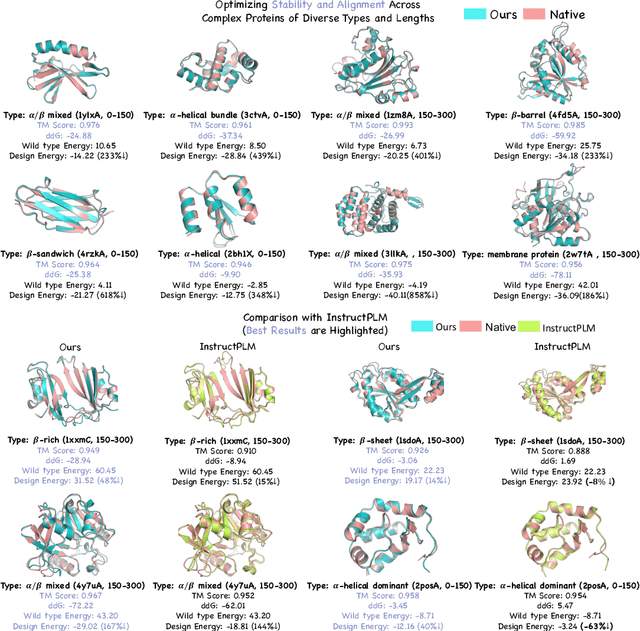
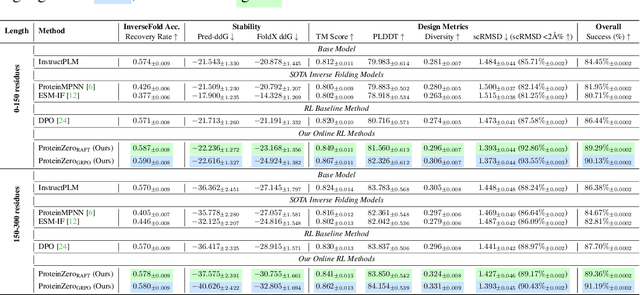

Protein generative models have shown remarkable promise in protein design but still face limitations in success rate, due to the scarcity of high-quality protein datasets for supervised pretraining. We present ProteinZero, a novel framework that enables scalable, automated, and continuous self-improvement of the inverse folding model through online reinforcement learning. To achieve computationally tractable online feedback, we introduce efficient proxy reward models based on ESM-fold and a novel rapid ddG predictor that significantly accelerates evaluation speed. ProteinZero employs a general RL framework balancing multi-reward maximization, KL-divergence from a reference model, and a novel protein-embedding level diversity regularization that prevents mode collapse while promoting higher sequence diversity. Through extensive experiments, we demonstrate that ProteinZero substantially outperforms existing methods across every key metric in protein design, achieving significant improvements in structural accuracy, designability, thermodynamic stability, and sequence diversity. Most impressively, ProteinZero reduces design failure rates by approximately 36% - 48% compared to widely-used methods like ProteinMPNN, ESM-IF and InstructPLM, consistently achieving success rates exceeding 90% across diverse and complex protein folds. Notably, the entire RL run on CATH-4.3 can be done with a single 8 X GPU node in under 3 days, including reward computation. Our work establishes a new paradigm for protein design where models evolve continuously from their own generated outputs, opening new possibilities for exploring the vast protein design space.
Variational Supervised Contrastive Learning
Jun 09, 2025Contrastive learning has proven to be highly efficient and adaptable in shaping representation spaces across diverse modalities by pulling similar samples together and pushing dissimilar ones apart. However, two key limitations persist: (1) Without explicit regulation of the embedding distribution, semantically related instances can inadvertently be pushed apart unless complementary signals guide pair selection, and (2) excessive reliance on large in-batch negatives and tailored augmentations hinders generalization. To address these limitations, we propose Variational Supervised Contrastive Learning (VarCon), which reformulates supervised contrastive learning as variational inference over latent class variables and maximizes a posterior-weighted evidence lower bound (ELBO) that replaces exhaustive pair-wise comparisons for efficient class-aware matching and grants fine-grained control over intra-class dispersion in the embedding space. Trained exclusively on image data, our experiments on CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K show that VarCon (1) achieves state-of-the-art performance for contrastive learning frameworks, reaching 79.36% Top-1 accuracy on ImageNet-1K and 78.29% on CIFAR-100 with a ResNet-50 encoder while converging in just 200 epochs; (2) yields substantially clearer decision boundaries and semantic organization in the embedding space, as evidenced by KNN classification, hierarchical clustering results, and transfer-learning assessments; and (3) demonstrates superior performance in few-shot learning than supervised baseline and superior robustness across various augmentation strategies.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
DecisionFlow: Advancing Large Language Model as Principled Decision Maker
May 27, 2025In high-stakes domains such as healthcare and finance, effective decision-making demands not just accurate outcomes but transparent and explainable reasoning. However, current language models often lack the structured deliberation needed for such tasks, instead generating decisions and justifications in a disconnected, post-hoc manner. To address this, we propose DecisionFlow, a novel decision modeling framework that guides models to reason over structured representations of actions, attributes, and constraints. Rather than predicting answers directly from prompts, DecisionFlow builds a semantically grounded decision space and infers a latent utility function to evaluate trade-offs in a transparent, utility-driven manner. This process produces decisions tightly coupled with interpretable rationales reflecting the model's reasoning. Empirical results on two high-stakes benchmarks show that DecisionFlow not only achieves up to 30% accuracy gains over strong prompting baselines but also enhances alignment in outcomes. Our work is a critical step toward integrating symbolic reasoning with LLMs, enabling more accountable, explainable, and reliable LLM decision support systems. We release the data and code at https://github.com/xiusic/DecisionFlow.
PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding
May 27, 2025Real-world objects are composed of distinctive, object-specific parts. Identifying these parts is key to performing fine-grained, compositional reasoning-yet, large multimodal models (LMMs) struggle to perform this seemingly straightforward task. In this work, we introduce PARTONOMY, an LMM benchmark designed for pixel-level part grounding. We construct PARTONOMY from existing part datasets and our own rigorously annotated set of images, encompassing 862 part labels and 534 object labels for evaluation. Unlike existing datasets that simply ask models to identify generic parts, PARTONOMY uses specialized concepts (e.g., agricultural airplane), and challenges models to compare objects' parts, consider part-whole relationships, and justify textual predictions with visual segmentations. Our experiments demonstrate significant limitations in state-of-the-art LMMs (e.g., LISA-13B achieves only 5.9% gIoU), highlighting a critical gap in their part grounding abilities. We note that existing segmentation-enabled LMMs (segmenting LMMs) have two key architectural shortcomings: they use special [SEG] tokens not seen during pretraining which induce distribution shift, and they discard predicted segmentations instead of using past predictions to guide future ones. To address these deficiencies, we train several part-centric LMMs and propose PLUM, a novel segmenting LMM that uses span tagging instead of segmentation tokens and that conditions on prior predictions in a feedback loop. We find that pretrained PLUM outperforms existing segmenting LMMs on reasoning segmentation, VQA, and visual hallucination benchmarks. In addition, PLUM finetuned on our proposed Explanatory Part Segmentation task is competitive with segmenting LMMs trained on significantly more segmentation data. Our work opens up new avenues towards enabling fine-grained, grounded visual understanding in LMMs.