 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElegantVLA: Learning When to Think for Efficient Vision-Language-Action Models
May 28, 2026Vision-Language-Action (VLA) models are a powerful paradigm for generalist robotic control. However, their high computational cost and limited control frequency hinder real-time robotic manipulation, especially when large vision-language backbones and iterative action heads run at every control step. Existing VLA acceleration methods often optimize individual components or rely on fixed acceleration rules, treating different control steps with largely fixed computation and overlooking the non-uniform reasoning demands of sequential embodied control. Inspired by human motor control, where cognitive and feedback resources concentrate on goal-sensitive stages, we argue that VLA models should learn when to invest full computation and when to reuse prior computation. We propose ElegantVLA, a plug-in phase-adaptive inference framework that accelerates VLA models through intra-model dynamic compute scheduling. ElegantVLA introduces a lightweight scheduler that observes temporal representation similarity, robot-motion cues, and episode progress to jointly allocate computation across the vision encoder, LLM, and action head. For perception-language reasoning, the scheduler selects a five-level Vision-LLM compute mode, from full recomputation to multi-step temporal reuse, based on visual-language representation stability. For action generation, it selects a three-level denoising mode, reusing intermediate denoising states during stable motion while preserving full refinement for goal-sensitive stages. By coordinating these decisions, ElegantVLA offers a general acceleration framework for modern VLA pipelines with explicit action-generation modules, without modifying or retraining the base model. Experiments on GR00T and CogACT achieve up to 2.55x and 3.77x speedup, and on six real-world GR00T tasks ElegantVLA cuts computation by 2.18x while raising control frequency from 13.8 Hz to 26.3 Hz.
Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
May 13, 2026Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized language models are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
Batched Contextual Reinforcement: A Task-Scaling Law for Efficient Reasoning
Apr 02, 2026Large Language Models employing Chain-of-Thought reasoning achieve strong performance but suffer from excessive token consumption that inflates inference costs. Existing efficiency methods such as explicit length penalties, difficulty estimators, or multi-stage curricula either degrade reasoning quality or require complex training pipelines. We introduce Batched Contextual Reinforcement, a minimalist, single-stage training paradigm that unlocks efficient reasoning through a simple structural modification: training the model to solve N problems simultaneously within a shared context window, rewarded purely by per-instance accuracy. This formulation creates an implicit token budget that yields several key findings: (1) We identify a novel task-scaling law: as the number of concurrent problems N increases during inference, per-problem token usage decreases monotonically while accuracy degrades far more gracefully than baselines, establishing N as a controllable throughput dimension. (2) BCR challenges the traditional accuracy-efficiency trade-off by demonstrating a "free lunch" phenomenon at standard single-problem inference. Across both 1.5B and 4B model families, BCR reduces token usage by 15.8% to 62.6% while consistently maintaining or improving accuracy across five major mathematical benchmarks. (3) Qualitative analyses reveal emergent self-regulated efficiency, where models autonomously eliminate redundant metacognitive loops without explicit length supervision. (4) Crucially, we empirically demonstrate that implicit budget constraints successfully circumvent the adversarial gradients and catastrophic optimization collapse inherent to explicit length penalties, offering a highly stable, constraint-based alternative for length control. These results prove BCR practical, showing simple structural incentives unlock latent high-density reasoning in LLMs.
M3: High-fidelity Text-to-Image Generation via Multi-Modal, Multi-Agent and Multi-Round Visual Reasoning
Feb 05, 2026Generative models have achieved impressive fidelity in text-to-image synthesis, yet struggle with complex compositional prompts involving multiple constraints. We introduce \textbf{M3 (Multi-Modal, Multi-Agent, Multi-Round)}, a training-free framework that systematically resolves these failures through iterative inference-time refinement. M3 orchestrates off-the-shelf foundation models in a robust multi-agent loop: a Planner decomposes prompts into verifiable checklists, while specialized Checker, Refiner, and Editor agents surgically correct constraints one at a time, with a Verifier ensuring monotonic improvement. Applied to open-source models, M3 achieves remarkable results on the challenging OneIG-EN benchmark, with our Qwen-Image+M3 surpassing commercial flagship systems including Imagen4 (0.515) and Seedream 3.0 (0.530), reaching state-of-the-art performance (0.532 overall). This demonstrates that intelligent multi-agent reasoning can elevate open-source models beyond proprietary alternatives. M3 also substantially improves GenEval compositional metrics, effectively doubling spatial reasoning performance on hardened test sets. As a plug-and-play module compatible with any pre-trained T2I model, M3 establishes a new paradigm for compositional generation without costly retraining.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Jun 15, 2025Vision-Language-Action (VLA) models have attracted increasing attention for their strong control capabilities. However, their high computational cost and low execution frequency hinder their suitability for real-time tasks such as robotic manipulation and autonomous navigation. Existing VLA acceleration methods primarily focus on structural optimization, overlooking the fact that these models operate in sequential decision-making environments. As a result, temporal redundancy in sequential action generation and spatial redundancy in visual input remain unaddressed. To this end, we propose SP-VLA, a unified framework that accelerates VLA models by jointly scheduling models and pruning tokens. Specifically, we design an action-aware model scheduling mechanism that reduces temporal redundancy by dynamically switching between VLA model and a lightweight generator. Inspired by the human motion pattern of focusing on key decision points while relying on intuition for other actions, we categorize VLA actions into deliberative and intuitive, assigning the former to the VLA model and the latter to the lightweight generator, enabling frequency-adaptive execution through collaborative model scheduling. To address spatial redundancy, we further develop a spatio-semantic dual-aware token pruning method. Tokens are classified into spatial and semantic types and pruned based on their dual-aware importance to accelerate VLA inference. These two mechanisms work jointly to guide the VLA in focusing on critical actions and salient visual information, achieving effective acceleration while maintaining high accuracy. Experimental results demonstrate that our method achieves up to 1.5$\times$ acceleration with less than 3% drop in accuracy, outperforming existing approaches in multiple tasks.
ProteinZero: Self-Improving Protein Generation via Online Reinforcement Learning
Jun 09, 2025
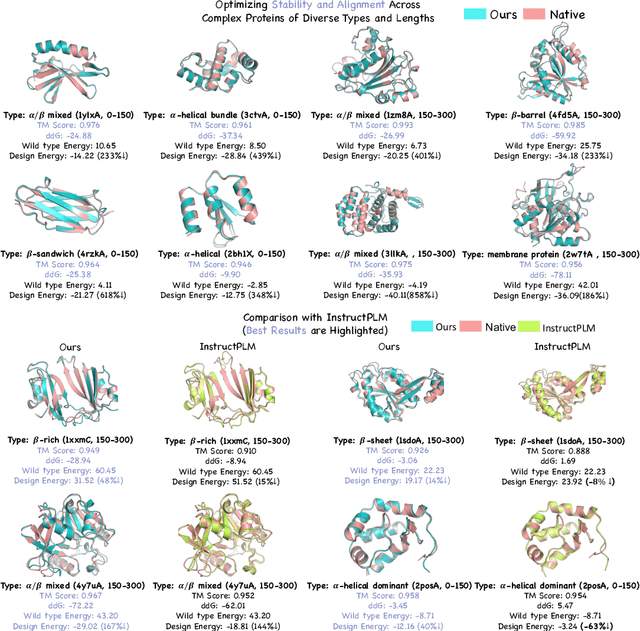
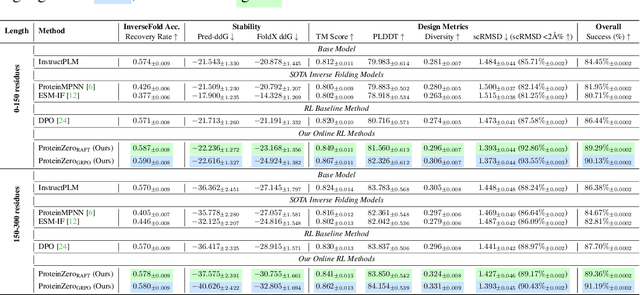

Protein generative models have shown remarkable promise in protein design but still face limitations in success rate, due to the scarcity of high-quality protein datasets for supervised pretraining. We present ProteinZero, a novel framework that enables scalable, automated, and continuous self-improvement of the inverse folding model through online reinforcement learning. To achieve computationally tractable online feedback, we introduce efficient proxy reward models based on ESM-fold and a novel rapid ddG predictor that significantly accelerates evaluation speed. ProteinZero employs a general RL framework balancing multi-reward maximization, KL-divergence from a reference model, and a novel protein-embedding level diversity regularization that prevents mode collapse while promoting higher sequence diversity. Through extensive experiments, we demonstrate that ProteinZero substantially outperforms existing methods across every key metric in protein design, achieving significant improvements in structural accuracy, designability, thermodynamic stability, and sequence diversity. Most impressively, ProteinZero reduces design failure rates by approximately 36% - 48% compared to widely-used methods like ProteinMPNN, ESM-IF and InstructPLM, consistently achieving success rates exceeding 90% across diverse and complex protein folds. Notably, the entire RL run on CATH-4.3 can be done with a single 8 X GPU node in under 3 days, including reward computation. Our work establishes a new paradigm for protein design where models evolve continuously from their own generated outputs, opening new possibilities for exploring the vast protein design space.
Variational Supervised Contrastive Learning
Jun 09, 2025Contrastive learning has proven to be highly efficient and adaptable in shaping representation spaces across diverse modalities by pulling similar samples together and pushing dissimilar ones apart. However, two key limitations persist: (1) Without explicit regulation of the embedding distribution, semantically related instances can inadvertently be pushed apart unless complementary signals guide pair selection, and (2) excessive reliance on large in-batch negatives and tailored augmentations hinders generalization. To address these limitations, we propose Variational Supervised Contrastive Learning (VarCon), which reformulates supervised contrastive learning as variational inference over latent class variables and maximizes a posterior-weighted evidence lower bound (ELBO) that replaces exhaustive pair-wise comparisons for efficient class-aware matching and grants fine-grained control over intra-class dispersion in the embedding space. Trained exclusively on image data, our experiments on CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K show that VarCon (1) achieves state-of-the-art performance for contrastive learning frameworks, reaching 79.36% Top-1 accuracy on ImageNet-1K and 78.29% on CIFAR-100 with a ResNet-50 encoder while converging in just 200 epochs; (2) yields substantially clearer decision boundaries and semantic organization in the embedding space, as evidenced by KNN classification, hierarchical clustering results, and transfer-learning assessments; and (3) demonstrates superior performance in few-shot learning than supervised baseline and superior robustness across various augmentation strategies.
$α$-Flow: A Unified Framework for Continuous-State Discrete Flow Matching Models
Apr 14, 2025Recent efforts have extended the flow-matching framework to discrete generative modeling. One strand of models directly works with the continuous probabilities instead of discrete tokens, which we colloquially refer to as Continuous-State Discrete Flow Matching (CS-DFM). Existing CS-DFM models differ significantly in their representations and geometric assumptions. This work presents a unified framework for CS-DFM models, under which the existing variants can be understood as operating on different $\alpha$-representations of probabilities. Building upon the theory of information geometry, we introduce $\alpha$-Flow, a family of CS-DFM models that adheres to the canonical $\alpha$-geometry of the statistical manifold, and demonstrate its optimality in minimizing the generalized kinetic energy. Theoretically, we show that the flow matching loss for $\alpha$-flow establishes a unified variational bound for the discrete negative log-likelihood. We comprehensively evaluate different instantiations of $\alpha$-flow on various discrete generation domains to demonstrate their effectiveness in discrete generative modeling, including intermediate values whose geometries have never been explored before. $\alpha$-flow significantly outperforms its discrete-state counterpart in image and protein sequence generation and better captures the entropy in language modeling.
Online Reward-Weighted Fine-Tuning of Flow Matching with Wasserstein Regularization
Feb 09, 2025



Recent advancements in reinforcement learning (RL) have achieved great success in fine-tuning diffusion-based generative models. However, fine-tuning continuous flow-based generative models to align with arbitrary user-defined reward functions remains challenging, particularly due to issues such as policy collapse from overoptimization and the prohibitively high computational cost of likelihoods in continuous-time flows. In this paper, we propose an easy-to-use and theoretically sound RL fine-tuning method, which we term Online Reward-Weighted Conditional Flow Matching with Wasserstein-2 Regularization (ORW-CFM-W2). Our method integrates RL into the flow matching framework to fine-tune generative models with arbitrary reward functions, without relying on gradients of rewards or filtered datasets. By introducing an online reward-weighting mechanism, our approach guides the model to prioritize high-reward regions in the data manifold. To prevent policy collapse and maintain diversity, we incorporate Wasserstein-2 (W2) distance regularization into our method and derive a tractable upper bound for it in flow matching, effectively balancing exploration and exploitation of policy optimization. We provide theoretical analyses to demonstrate the convergence properties and induced data distributions of our method, establishing connections with traditional RL algorithms featuring Kullback-Leibler (KL) regularization and offering a more comprehensive understanding of the underlying mechanisms and learning behavior of our approach. Extensive experiments on tasks including target image generation, image compression, and text-image alignment demonstrate the effectiveness of our method, where our method achieves optimal policy convergence while allowing controllable trade-offs between reward maximization and diversity preservation.