 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProteinZero: Self-Improving Protein Generation via Online Reinforcement Learning
Paper and Code
Jun 09, 2025
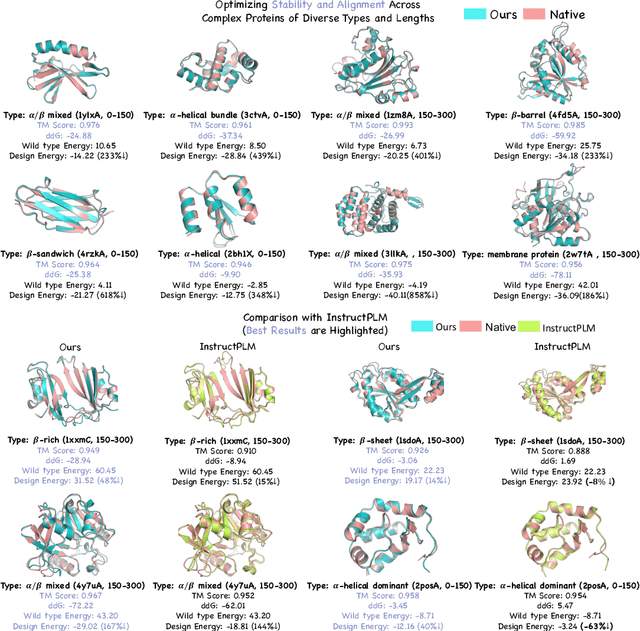
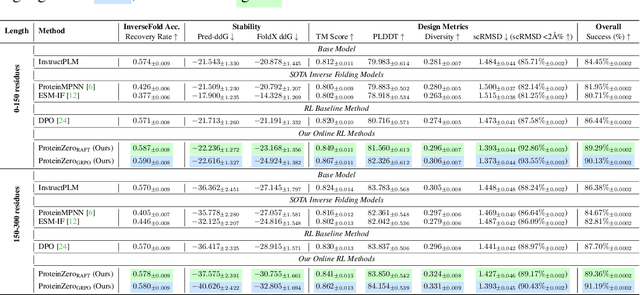

Protein generative models have shown remarkable promise in protein design but still face limitations in success rate, due to the scarcity of high-quality protein datasets for supervised pretraining. We present ProteinZero, a novel framework that enables scalable, automated, and continuous self-improvement of the inverse folding model through online reinforcement learning. To achieve computationally tractable online feedback, we introduce efficient proxy reward models based on ESM-fold and a novel rapid ddG predictor that significantly accelerates evaluation speed. ProteinZero employs a general RL framework balancing multi-reward maximization, KL-divergence from a reference model, and a novel protein-embedding level diversity regularization that prevents mode collapse while promoting higher sequence diversity. Through extensive experiments, we demonstrate that ProteinZero substantially outperforms existing methods across every key metric in protein design, achieving significant improvements in structural accuracy, designability, thermodynamic stability, and sequence diversity. Most impressively, ProteinZero reduces design failure rates by approximately 36% - 48% compared to widely-used methods like ProteinMPNN, ESM-IF and InstructPLM, consistently achieving success rates exceeding 90% across diverse and complex protein folds. Notably, the entire RL run on CATH-4.3 can be done with a single 8 X GPU node in under 3 days, including reward computation. Our work establishes a new paradigm for protein design where models evolve continuously from their own generated outputs, opening new possibilities for exploring the vast protein design space.