 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSplit: A Comprehensive Benchmark Dataset and Evaluation Approach for Document Packet Recognition and Splitting
Feb 17, 2026Document understanding in real-world applications often requires processing heterogeneous, multi-page document packets containing multiple documents stitched together. Despite recent advances in visual document understanding, the fundamental task of document packet splitting, which involves separating a document packet into individual units, remains largely unaddressed. We present the first comprehensive benchmark dataset, DocSplit, along with novel evaluation metrics for assessing the document packet splitting capabilities of large language models. DocSplit comprises five datasets of varying complexity, covering diverse document types, layouts, and multimodal settings. We formalize the DocSplit task, which requires models to identify document boundaries, classify document types, and maintain correct page ordering within a document packet. The benchmark addresses real-world challenges, including out-of-order pages, interleaved documents, and documents lacking clear demarcations. We conduct extensive experiments evaluating multimodal LLMs on our datasets, revealing significant performance gaps in current models' ability to handle complex document splitting tasks. The DocSplit benchmark datasets and proposed novel evaluation metrics provide a systematic framework for advancing document understanding capabilities essential for legal, financial, healthcare, and other document-intensive domains. We release the datasets to facilitate future research in document packet processing.
MathMist: A Parallel Multilingual Benchmark Dataset for Mathematical Problem Solving and Reasoning
Oct 16, 2025Mathematical reasoning remains one of the most challenging domains for large language models (LLMs), requiring not only linguistic understanding but also structured logical deduction and numerical precision. While recent LLMs demonstrate strong general-purpose reasoning abilities, their mathematical competence across diverse languages remains underexplored. Existing benchmarks primarily focus on English or a narrow subset of high-resource languages, leaving significant gaps in assessing multilingual and cross-lingual mathematical reasoning. To address this, we introduce MathMist, a parallel multilingual benchmark for mathematical problem solving and reasoning. MathMist encompasses over 21K aligned question-answer pairs across seven languages, representing a balanced coverage of high-, medium-, and low-resource linguistic settings. The dataset captures linguistic variety, multiple types of problem settings, and solution synthesizing capabilities. We systematically evaluate a diverse suite of models, including open-source small and medium LLMs, proprietary systems, and multilingual-reasoning-focused models, under zero-shot, chain-of-thought (CoT), and code-switched reasoning paradigms. Our results reveal persistent deficiencies in LLMs' ability to perform consistent and interpretable mathematical reasoning across languages, with pronounced degradation in low-resource settings. All the codes and data are available at GitHub: https://github.com/mahbubhimel/MathMist
Ready to Translate, Not to Represent? Bias and Performance Gaps in Multilingual LLMs Across Language Families and Domains
Oct 09, 2025The rise of Large Language Models (LLMs) has redefined Machine Translation (MT), enabling context-aware and fluent translations across hundreds of languages and textual domains. Despite their remarkable capabilities, LLMs often exhibit uneven performance across language families and specialized domains. Moreover, recent evidence reveals that these models can encode and amplify different biases present in their training data, posing serious concerns for fairness, especially in low-resource languages. To address these gaps, we introduce Translation Tangles, a unified framework and dataset for evaluating the translation quality and fairness of open-source LLMs. Our approach benchmarks 24 bidirectional language pairs across multiple domains using different metrics. We further propose a hybrid bias detection pipeline that integrates rule-based heuristics, semantic similarity filtering, and LLM-based validation. We also introduce a high-quality, bias-annotated dataset based on human evaluations of 1,439 translation-reference pairs. The code and dataset are accessible on GitHub: https://github.com/faiyazabdullah/TranslationTangles
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025



Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
DM-Codec: Distilling Multimodal Representations for Speech Tokenization
Oct 19, 2024



Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset. The code, samples, and model checkpoints are available at https://github.com/mubtasimahasan/DM-Codec.
Cognitively Inspired Energy-Based World Models
Jun 13, 2024One of the predominant methods for training world models is autoregressive prediction in the output space of the next element of a sequence. In Natural Language Processing (NLP), this takes the form of Large Language Models (LLMs) predicting the next token; in Computer Vision (CV), this takes the form of autoregressive models predicting the next frame/token/pixel. However, this approach differs from human cognition in several respects. First, human predictions about the future actively influence internal cognitive processes. Second, humans naturally evaluate the plausibility of predictions regarding future states. Based on this capability, and third, by assessing when predictions are sufficient, humans allocate a dynamic amount of time to make a prediction. This adaptive process is analogous to System 2 thinking in psychology. All these capabilities are fundamental to the success of humans at high-level reasoning and planning. Therefore, to address the limitations of traditional autoregressive models lacking these human-like capabilities, we introduce Energy-Based World Models (EBWM). EBWM involves training an Energy-Based Model (EBM) to predict the compatibility of a given context and a predicted future state. In doing so, EBWM enables models to achieve all three facets of human cognition described. Moreover, we developed a variant of the traditional autoregressive transformer tailored for Energy-Based models, termed the Energy-Based Transformer (EBT). Our results demonstrate that EBWM scales better with data and GPU Hours than traditional autoregressive transformers in CV, and that EBWM offers promising early scaling in NLP. Consequently, this approach offers an exciting path toward training future models capable of System 2 thinking and intelligently searching across state spaces.
Breaking Down the Defenses: A Comparative Survey of Attacks on Large Language Models
Mar 03, 2024

Large Language Models (LLMs) have become a cornerstone in the field of Natural Language Processing (NLP), offering transformative capabilities in understanding and generating human-like text. However, with their rising prominence, the security and vulnerability aspects of these models have garnered significant attention. This paper presents a comprehensive survey of the various forms of attacks targeting LLMs, discussing the nature and mechanisms of these attacks, their potential impacts, and current defense strategies. We delve into topics such as adversarial attacks that aim to manipulate model outputs, data poisoning that affects model training, and privacy concerns related to training data exploitation. The paper also explores the effectiveness of different attack methodologies, the resilience of LLMs against these attacks, and the implications for model integrity and user trust. By examining the latest research, we provide insights into the current landscape of LLM vulnerabilities and defense mechanisms. Our objective is to offer a nuanced understanding of LLM attacks, foster awareness within the AI community, and inspire robust solutions to mitigate these risks in future developments.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022



Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
A Vocabulary-Free Multilingual Neural Tokenizer for End-to-End Task Learning
Apr 22, 2022
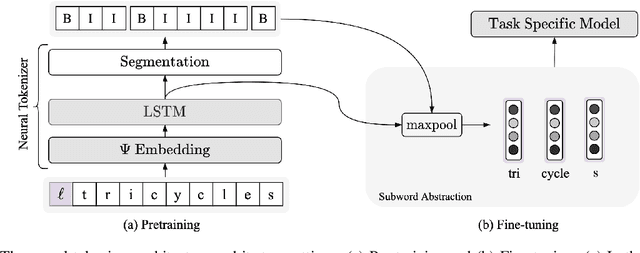
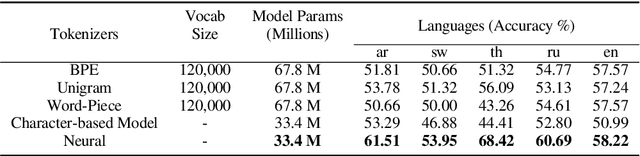

Subword tokenization is a commonly used input pre-processing step in most recent NLP models. However, it limits the models' ability to leverage end-to-end task learning. Its frequency-based vocabulary creation compromises tokenization in low-resource languages, leading models to produce suboptimal representations. Additionally, the dependency on a fixed vocabulary limits the subword models' adaptability across languages and domains. In this work, we propose a vocabulary-free neural tokenizer by distilling segmentation information from heuristic-based subword tokenization. We pre-train our character-based tokenizer by processing unique words from multilingual corpus, thereby extensively increasing word diversity across languages. Unlike the predefined and fixed vocabularies in subword methods, our tokenizer allows end-to-end task learning, resulting in optimal task-specific tokenization. The experimental results show that replacing the subword tokenizer with our neural tokenizer consistently improves performance on multilingual (NLI) and code-switching (sentiment analysis) tasks, with larger gains in low-resource languages. Additionally, our neural tokenizer exhibits a robust performance on downstream tasks when adversarial noise is present (typos and misspelling), further increasing the initial improvements over statistical subword tokenizers.
HAMLET: A Hierarchical Multimodal Attention-based Human Activity Recognition Algorithm
Aug 03, 2020
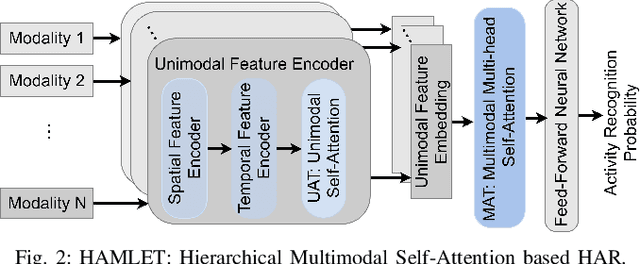
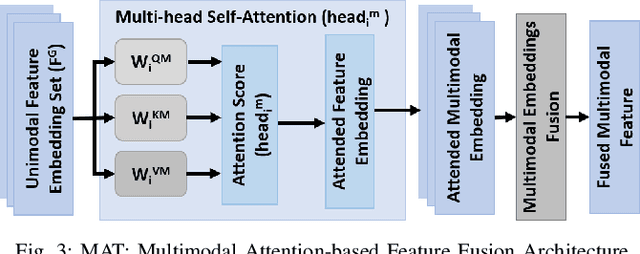
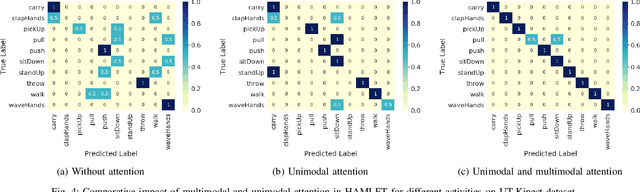
To fluently collaborate with people, robots need the ability to recognize human activities accurately. Although modern robots are equipped with various sensors, robust human activity recognition (HAR) still remains a challenging task for robots due to difficulties related to multimodal data fusion. To address these challenges, in this work, we introduce a deep neural network-based multimodal HAR algorithm, HAMLET. HAMLET incorporates a hierarchical architecture, where the lower layer encodes spatio-temporal features from unimodal data by adopting a multi-head self-attention mechanism. We develop a novel multimodal attention mechanism for disentangling and fusing the salient unimodal features to compute the multimodal features in the upper layer. Finally, multimodal features are used in a fully connect neural-network to recognize human activities. We evaluated our algorithm by comparing its performance to several state-of-the-art activity recognition algorithms on three human activity datasets. The results suggest that HAMLET outperformed all other evaluated baselines across all datasets and metrics tested, with the highest top-1 accuracy of 95.12% and 97.45% on the UTD-MHAD [1] and the UT-Kinect [2] datasets respectively, and F1-score of 81.52% on the UCSD-MIT [3] dataset. We further visualize the unimodal and multimodal attention maps, which provide us with a tool to interpret the impact of attention mechanisms concerning HAR.