 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
iSeal: Encrypted Fingerprinting for Reliable LLM Ownership Verification
Nov 12, 2025Given the high cost of large language model (LLM) training from scratch, safeguarding LLM intellectual property (IP) has become increasingly crucial. As the standard paradigm for IP ownership verification, LLM fingerprinting thus plays a vital role in addressing this challenge. Existing LLM fingerprinting methods verify ownership by extracting or injecting model-specific features. However, they overlook potential attacks during the verification process, leaving them ineffective when the model thief fully controls the LLM's inference process. In such settings, attackers may share prompt-response pairs to enable fingerprint unlearning or manipulate outputs to evade exact-match verification. We propose iSeal, the first fingerprinting method designed for reliable verification when the model thief controls the suspected LLM in an end-to-end manner. It injects unique features into both the model and an external module, reinforced by an error-correction mechanism and a similarity-based verification strategy. These components are resistant to verification-time attacks, including collusion-based fingerprint unlearning and response manipulation, backed by both theoretical analysis and empirical results. iSeal achieves 100 percent Fingerprint Success Rate (FSR) on 12 LLMs against more than 10 attacks, while baselines fail under unlearning and response manipulations.
TiS-TSL: Image-Label Supervised Surgical Video Stereo Matching via Time-Switchable Teacher-Student Learning
Nov 12, 2025Stereo matching in minimally invasive surgery (MIS) is essential for next-generation navigation and augmented reality. Yet, dense disparity supervision is nearly impossible due to anatomical constraints, typically limiting annotations to only a few image-level labels acquired before the endoscope enters deep body cavities. Teacher-Student Learning (TSL) offers a promising solution by leveraging a teacher trained on sparse labels to generate pseudo labels and associated confidence maps from abundant unlabeled surgical videos. However, existing TSL methods are confined to image-level supervision, providing only spatial confidence and lacking temporal consistency estimation. This absence of spatio-temporal reliability results in unstable disparity predictions and severe flickering artifacts across video frames. To overcome these challenges, we propose TiS-TSL, a novel time-switchable teacher-student learning framework for video stereo matching under minimal supervision. At its core is a unified model that operates in three distinct modes: Image-Prediction (IP), Forward Video-Prediction (FVP), and Backward Video-Prediction (BVP), enabling flexible temporal modeling within a single architecture. Enabled by this unified model, TiS-TSL adopts a two-stage learning strategy. The Image-to-Video (I2V) stage transfers sparse image-level knowledge to initialize temporal modeling. The subsequent Video-to-Video (V2V) stage refines temporal disparity predictions by comparing forward and backward predictions to calculate bidirectional spatio-temporal consistency. This consistency identifies unreliable regions across frames, filters noisy video-level pseudo labels, and enforces temporal coherence. Experimental results on two public datasets demonstrate that TiS-TSL exceeds other image-based state-of-the-arts by improving TEPE and EPE by at least 2.11% and 4.54%, respectively.
Perceptual Quality Assessment of 3D Gaussian Splatting: A Subjective Dataset and Prediction Metric
Nov 11, 2025



With the rapid advancement of 3D visualization, 3D Gaussian Splatting (3DGS) has emerged as a leading technique for real-time, high-fidelity rendering. While prior research has emphasized algorithmic performance and visual fidelity, the perceptual quality of 3DGS-rendered content, especially under varying reconstruction conditions, remains largely underexplored. In practice, factors such as viewpoint sparsity, limited training iterations, point downsampling, noise, and color distortions can significantly degrade visual quality, yet their perceptual impact has not been systematically studied. To bridge this gap, we present 3DGS-QA, the first subjective quality assessment dataset for 3DGS. It comprises 225 degraded reconstructions across 15 object types, enabling a controlled investigation of common distortion factors. Based on this dataset, we introduce a no-reference quality prediction model that directly operates on native 3D Gaussian primitives, without requiring rendered images or ground-truth references. Our model extracts spatial and photometric cues from the Gaussian representation to estimate perceived quality in a structure-aware manner. We further benchmark existing quality assessment methods, spanning both traditional and learning-based approaches. Experimental results show that our method consistently achieves superior performance, highlighting its robustness and effectiveness for 3DGS content evaluation. The dataset and code are made publicly available at https://github.com/diaoyn/3DGSQA to facilitate future research in 3DGS quality assessment.
Using Vision Language Models as Closed-Loop Symbolic Planners for Robotic Applications: A Control-Theoretic Perspective
Nov 10, 2025Large Language Models (LLMs) and Vision Language Models (VLMs) have been widely used for embodied symbolic planning. Yet, how to effectively use these models for closed-loop symbolic planning remains largely unexplored. Because they operate as black boxes, LLMs and VLMs can produce unpredictable or costly errors, making their use in high-level robotic planning especially challenging. In this work, we investigate how to use VLMs as closed-loop symbolic planners for robotic applications from a control-theoretic perspective. Concretely, we study how the control horizon and warm-starting impact the performance of VLM symbolic planners. We design and conduct controlled experiments to gain insights that are broadly applicable to utilizing VLMs as closed-loop symbolic planners, and we discuss recommendations that can help improve the performance of VLM symbolic planners.
DeepAgent: A General Reasoning Agent with Scalable Toolsets
Oct 24, 2025Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow predefined workflows, which limit autonomous and global task completion. In this paper, we introduce DeepAgent, an end-to-end deep reasoning agent that performs autonomous thinking, tool discovery, and action execution within a single, coherent reasoning process. To address the challenges of long-horizon interactions, particularly the context length explosion from multiple tool calls and the accumulation of interaction history, we introduce an autonomous memory folding mechanism that compresses past interactions into structured episodic, working, and tool memories, reducing error accumulation while preserving critical information. To teach general-purpose tool use efficiently and stably, we develop an end-to-end reinforcement learning strategy, namely ToolPO, that leverages LLM-simulated APIs and applies tool-call advantage attribution to assign fine-grained credit to the tool invocation tokens. Extensive experiments on eight benchmarks, including general tool-use tasks (ToolBench, API-Bank, TMDB, Spotify, ToolHop) and downstream applications (ALFWorld, WebShop, GAIA, HLE), demonstrate that DeepAgent consistently outperforms baselines across both labeled-tool and open-set tool retrieval scenarios. This work takes a step toward more general and capable agents for real-world applications. The code and demo are available at https://github.com/RUC-NLPIR/DeepAgent.
EmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025



The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
FunAudio-ASR Technical Report
Sep 15, 2025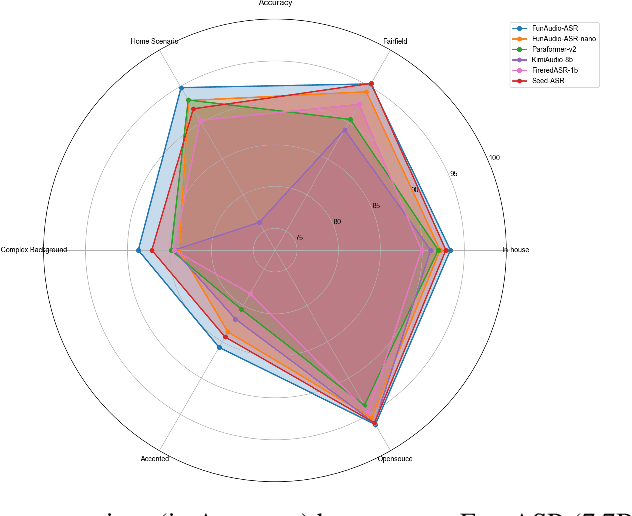
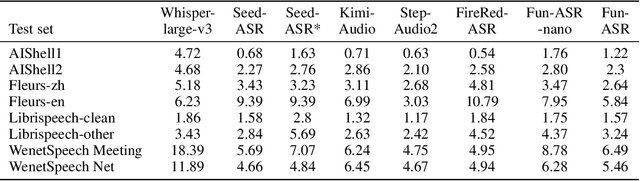
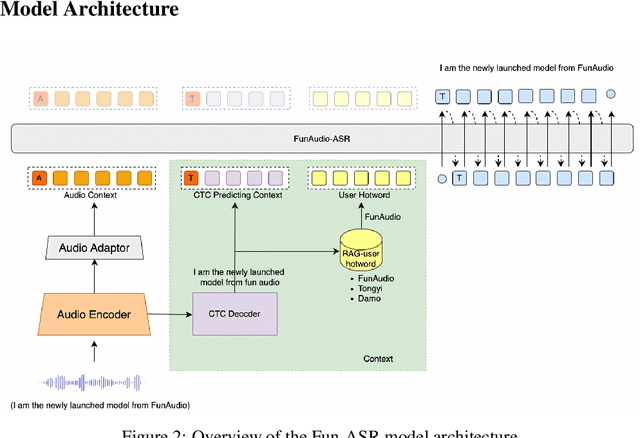
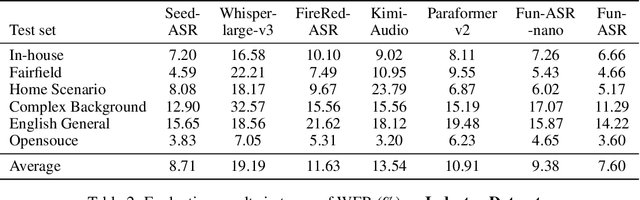
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.