 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
Nov 18, 2022We present a novel bird's-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones. Existing state-of-the-art BEV detectors are often tied to certain depth pre-trained backbones like VoVNet, hindering the synergy between booming image backbones and BEV detectors. To address this limitation, we prioritize easing the optimization of BEV detectors by introducing perspective space supervision. To this end, we propose a two-stage BEV detector, where proposals from the perspective head are fed into the bird's-eye-view head for final predictions. To evaluate the effectiveness of our model, we conduct extensive ablation studies focusing on the form of supervision and the generality of the proposed detector. The proposed method is verified with a wide spectrum of traditional and modern image backbones and achieves new SoTA results on the large-scale nuScenes dataset. The code shall be released soon.
Extreme Generative Image Compression by Learning Text Embedding from Diffusion Models
Nov 14, 2022



Transferring large amount of high resolution images over limited bandwidth is an important but very challenging task. Compressing images using extremely low bitrates (<0.1 bpp) has been studied but it often results in low quality images of heavy artifacts due to the strong constraint in the number of bits available for the compressed data. It is often said that a picture is worth a thousand words but on the other hand, language is very powerful in capturing the essence of an image using short descriptions. With the recent success of diffusion models for text-to-image generation, we propose a generative image compression method that demonstrates the potential of saving an image as a short text embedding which in turn can be used to generate high-fidelity images which is equivalent to the original one perceptually. For a given image, its corresponding text embedding is learned using the same optimization process as the text-to-image diffusion model itself, using a learnable text embedding as input after bypassing the original transformer. The optimization is applied together with a learning compression model to achieve extreme compression of low bitrates <0.1 bpp. Based on our experiments measured by a comprehensive set of image quality metrics, our method outperforms the other state-of-the-art deep learning methods in terms of both perceptual quality and diversity.
Arbitrary Style Guidance for Enhanced Diffusion-Based Text-to-Image Generation
Nov 14, 2022



Diffusion-based text-to-image generation models like GLIDE and DALLE-2 have gained wide success recently for their superior performance in turning complex text inputs into images of high quality and wide diversity. In particular, they are proven to be very powerful in creating graphic arts of various formats and styles. Although current models supported specifying style formats like oil painting or pencil drawing, fine-grained style features like color distributions and brush strokes are hard to specify as they are randomly picked from a conditional distribution based on the given text input. Here we propose a novel style guidance method to support generating images using arbitrary style guided by a reference image. The generation method does not require a separate style transfer model to generate desired styles while maintaining image quality in generated content as controlled by the text input. Additionally, the guidance method can be applied without a style reference, denoted as self style guidance, to generate images of more diverse styles. Comprehensive experiments prove that the proposed method remains robust and effective in a wide range of conditions, including diverse graphic art forms, image content types and diffusion models.
ERNIE-UniX2: A Unified Cross-lingual Cross-modal Framework for Understanding and Generation
Nov 09, 2022



Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022



Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022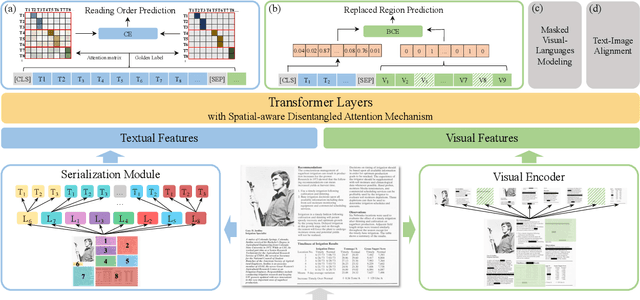
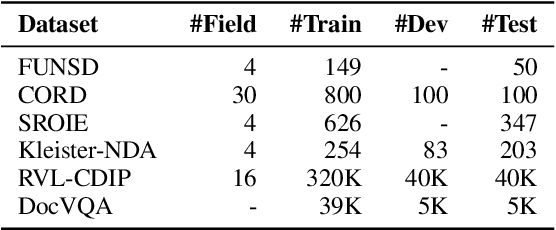
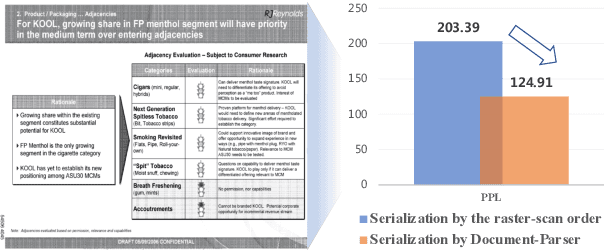
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022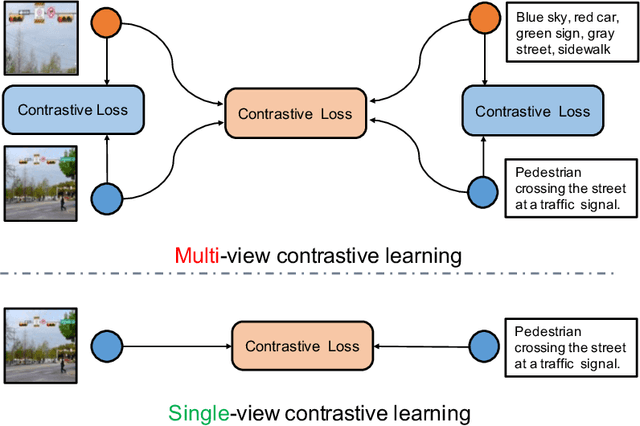
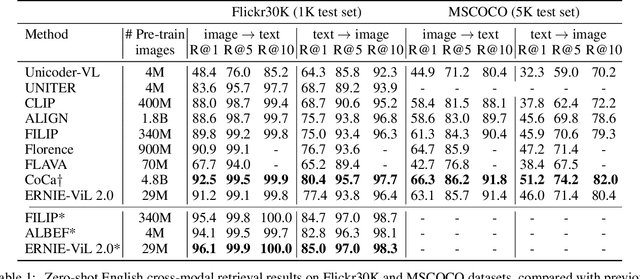
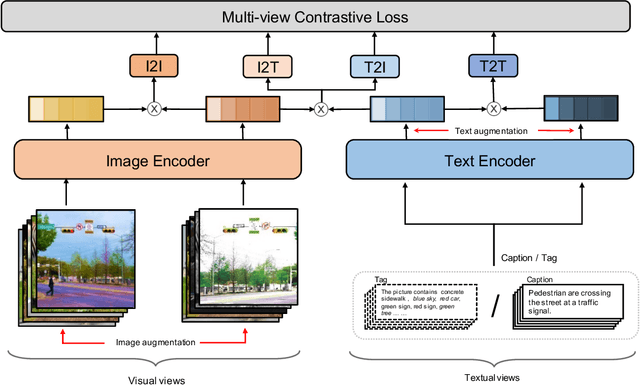
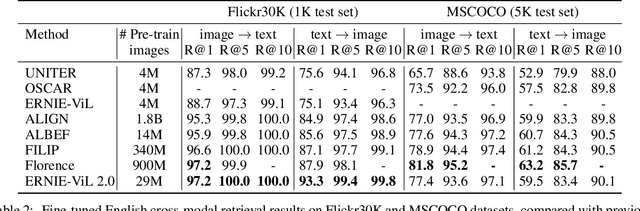
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022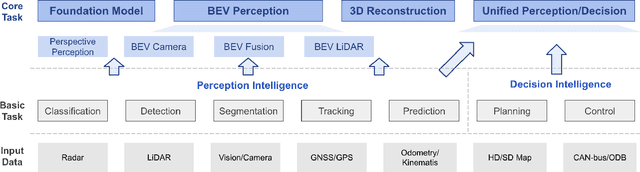
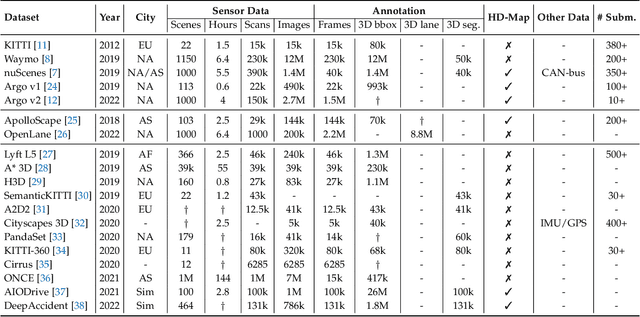
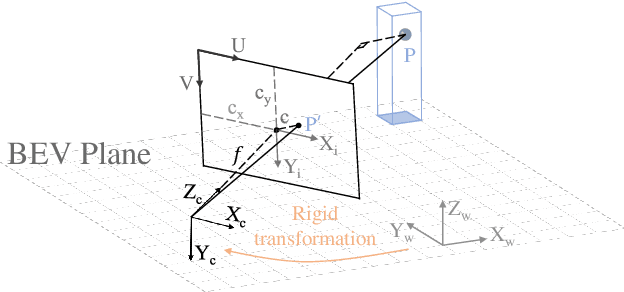
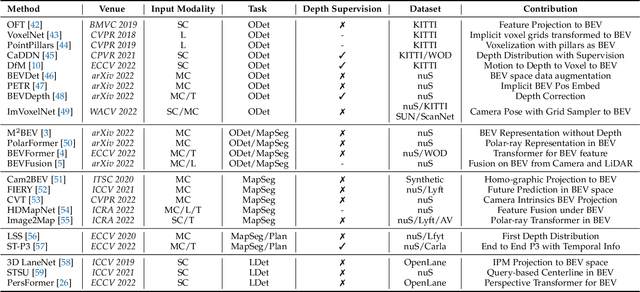
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
Graph Kernels Based on Multi-scale Graph Embeddings
Jun 02, 2022
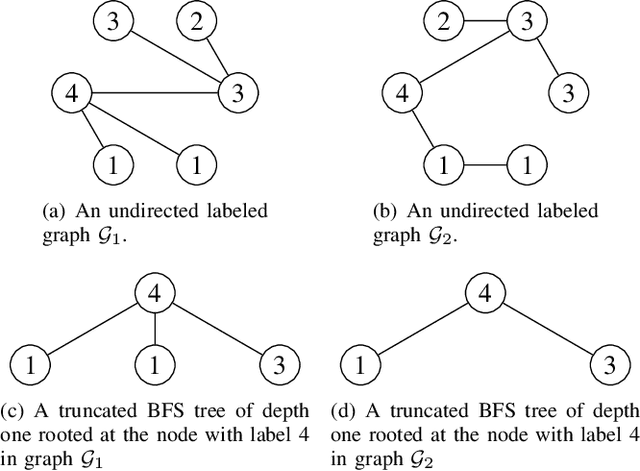
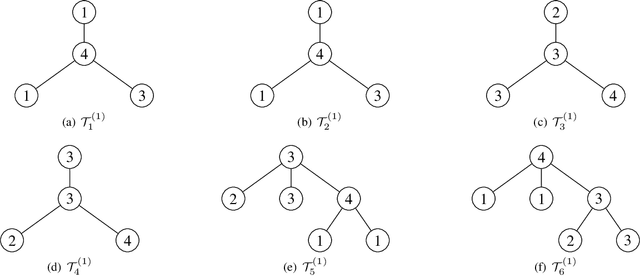
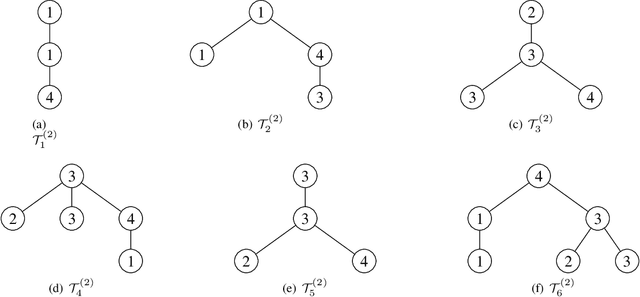
Graph kernels are conventional methods for computing graph similarities. However, most of the R-convolution graph kernels face two challenges: 1) They cannot compare graphs at multiple different scales, and 2) they do not consider the distributions of substructures when computing the kernel matrix. These two challenges limit their performances. To mitigate the two challenges, we propose a novel graph kernel called the Multi-scale Path-pattern Graph kernel (MPG), at the heart of which is the multi-scale path-pattern node feature map. Each element of the path-pattern node feature map is the number of occurrences of a path-pattern around a node. A path-pattern is constructed by the concatenation of all the node labels in a path of a truncated BFS tree rooted at each node. Since the path-pattern node feature map can only compare graphs at local scales, we incorporate into it the multiple different scales of the graph structure, which are captured by the truncated BFS trees of different depth. We use the Wasserstein distance to compute the similarity between the multi-scale path-pattern node feature maps of two graphs, considering the distributions of substructures. We empirically validate MPG on various benchmark graph datasets and demonstrate that it achieves state-of-the-art performance.
ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
May 18, 2022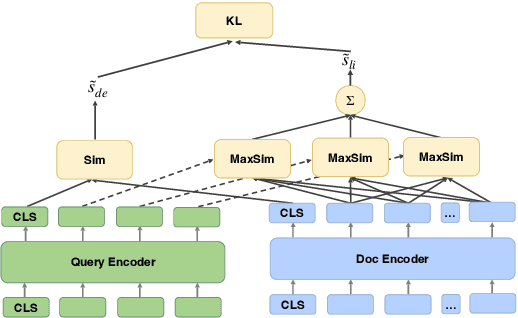

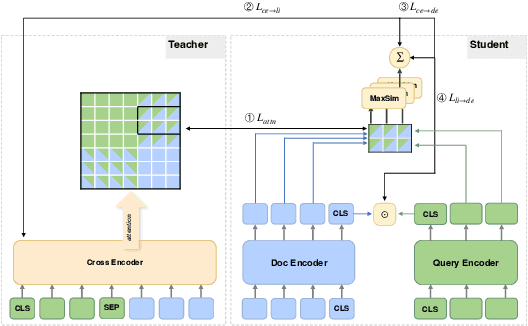
Neural retrievers based on pre-trained language models (PLMs), such as dual-encoders, have achieved promising performance on the task of open-domain question answering (QA). Their effectiveness can further reach new state-of-the-arts by incorporating cross-architecture knowledge distillation. However, most of the existing studies just directly apply conventional distillation methods. They fail to consider the particular situation where the teacher and student have different structures. In this paper, we propose a novel distillation method that significantly advances cross-architecture distillation for dual-encoders. Our method 1) introduces a self on-the-fly distillation method that can effectively distill late interaction (i.e., ColBERT) to vanilla dual-encoder, and 2) incorporates a cascade distillation process to further improve the performance with a cross-encoder teacher. Extensive experiments are conducted to validate that our proposed solution outperforms strong baselines and establish a new state-of-the-art on open-domain QA benchmarks.