 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer
Oct 30, 2024
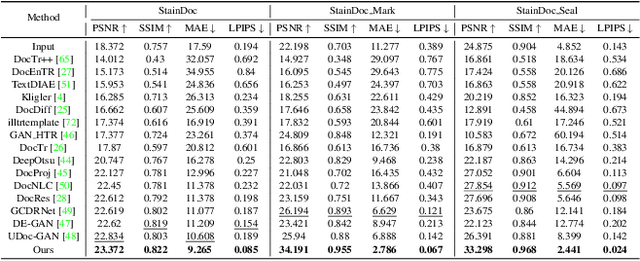


Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution ($2145\times2245$) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer's superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc\_Mark and StainDoc\_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
P$^2$C$^2$Net: PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics
Oct 29, 2024



When solving partial differential equations (PDEs), classical numerical methods often require fine mesh grids and small time stepping to meet stability, consistency, and convergence conditions, leading to high computational cost. Recently, machine learning has been increasingly utilized to solve PDE problems, but they often encounter challenges related to interpretability, generalizability, and strong dependency on rich labeled data. Hence, we introduce a new PDE-Preserved Coarse Correction Network (P$^2$C$^2$Net) to efficiently solve spatiotemporal PDE problems on coarse mesh grids in small data regimes. The model consists of two synergistic modules: (1) a trainable PDE block that learns to update the coarse solution (i.e., the system state), based on a high-order numerical scheme with boundary condition encoding, and (2) a neural network block that consistently corrects the solution on the fly. In particular, we propose a learnable symmetric Conv filter, with weights shared over the entire model, to accurately estimate the spatial derivatives of PDE based on the neural-corrected system state. The resulting physics-encoded model is capable of handling limited training data (e.g., 3--5 trajectories) and accelerates the prediction of PDE solutions on coarse spatiotemporal grids while maintaining a high accuracy. P$^2$C$^2$Net achieves consistent state-of-the-art performance with over 50\% gain (e.g., in terms of relative prediction error) across four datasets covering complex reaction-diffusion processes and turbulent flows.
Cross-model Control: Improving Multiple Large Language Models in One-time Training
Oct 23, 2024



The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC.
SemSim: Revisiting Weak-to-Strong Consistency from a Semantic Similarity Perspective for Semi-supervised Medical Image Segmentation
Oct 17, 2024



Semi-supervised learning (SSL) for medical image segmentation is a challenging yet highly practical task, which reduces reliance on large-scale labeled dataset by leveraging unlabeled samples. Among SSL techniques, the weak-to-strong consistency framework, popularized by FixMatch, has emerged as a state-of-the-art method in classification tasks. Notably, such a simple pipeline has also shown competitive performance in medical image segmentation. However, two key limitations still persist, impeding its efficient adaptation: (1) the neglect of contextual dependencies results in inconsistent predictions for similar semantic features, leading to incomplete object segmentation; (2) the lack of exploitation of semantic similarity between labeled and unlabeled data induces considerable class-distribution discrepancy. To address these limitations, we propose a novel semi-supervised framework based on FixMatch, named SemSim, powered by two appealing designs from semantic similarity perspective: (1) rectifying pixel-wise prediction by reasoning about the intra-image pair-wise affinity map, thus integrating contextual dependencies explicitly into the final prediction; (2) bridging labeled and unlabeled data via a feature querying mechanism for compact class representation learning, which fully considers cross-image anatomical similarities. As the reliable semantic similarity extraction depends on robust features, we further introduce an effective spatial-aware fusion module (SFM) to explore distinctive information from multiple scales. Extensive experiments show that SemSim yields consistent improvements over the state-of-the-art methods across three public segmentation benchmarks.
AdaSwitch: Adaptive Switching between Small and Large Agents for Effective Cloud-Local Collaborative Learning
Oct 17, 2024



Recent advancements in large language models (LLMs) have been remarkable. Users face a choice between using cloud-based LLMs for generation quality and deploying local-based LLMs for lower computational cost. The former option is typically costly and inefficient, while the latter usually fails to deliver satisfactory performance for reasoning steps requiring deliberate thought processes. In this work, we propose a novel LLM utilization paradigm that facilitates the collaborative operation of large cloud-based LLMs and smaller local-deployed LLMs. Our framework comprises two primary modules: the local agent instantiated with a relatively smaller LLM, handling less complex reasoning steps, and the cloud agent equipped with a larger LLM, managing more intricate reasoning steps. This collaborative processing is enabled through an adaptive mechanism where the local agent introspectively identifies errors and proactively seeks assistance from the cloud agent, thereby effectively integrating the strengths of both locally-deployed and cloud-based LLMs, resulting in significant enhancements in task completion performance and efficiency. We evaluate AdaSwitch across 7 benchmarks, ranging from mathematical reasoning and complex question answering, using various types of LLMs to instantiate the local and cloud agents. The empirical results show that AdaSwitch effectively improves the performance of the local agent, and sometimes achieves competitive results compared to the cloud agent while utilizing much less computational overhead.
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning
Oct 15, 2024



Parameter-efficient fine-tuning (PEFT) has been widely employed for domain adaptation, with LoRA being one of the most prominent methods due to its simplicity and effectiveness. However, in multi-task learning (MTL) scenarios, LoRA tends to obscure the distinction between tasks by projecting sparse high-dimensional features from different tasks into the same dense low-dimensional intrinsic space. This leads to task interference and suboptimal performance for LoRA and its variants. To tackle this challenge, we propose MTL-LoRA, which retains the advantages of low-rank adaptation while significantly enhancing multi-task learning capabilities. MTL-LoRA augments LoRA by incorporating additional task-adaptive parameters that differentiate task-specific information and effectively capture shared knowledge across various tasks within low-dimensional spaces. This approach enables large language models (LLMs) pre-trained on general corpus to adapt to different target task domains with a limited number of trainable parameters. Comprehensive experimental results, including evaluations on public academic benchmarks for natural language understanding, commonsense reasoning, and image-text understanding, as well as real-world industrial text Ads relevance datasets, demonstrate that MTL-LoRA outperforms LoRA and its various variants with comparable or even fewer learnable parameters in multitask learning.
When Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
A foundation model for generalizable disease diagnosis in chest X-ray images
Oct 11, 2024Medical artificial intelligence (AI) is revolutionizing the interpretation of chest X-ray (CXR) images by providing robust tools for disease diagnosis. However, the effectiveness of these AI models is often limited by their reliance on large amounts of task-specific labeled data and their inability to generalize across diverse clinical settings. To address these challenges, we introduce CXRBase, a foundational model designed to learn versatile representations from unlabelled CXR images, facilitating efficient adaptation to various clinical tasks. CXRBase is initially trained on a substantial dataset of 1.04 million unlabelled CXR images using self-supervised learning methods. This approach allows the model to discern meaningful patterns without the need for explicit labels. After this initial phase, CXRBase is fine-tuned with labeled data to enhance its performance in disease detection, enabling accurate classification of chest diseases. CXRBase provides a generalizable solution to improve model performance and alleviate the annotation workload of experts to enable broad clinical AI applications from chest imaging.
PhyMPGN: Physics-encoded Message Passing Graph Network for spatiotemporal PDE systems
Oct 02, 2024Solving partial differential equations (PDEs) serves as a cornerstone for modeling complex dynamical systems. Recent progresses have demonstrated grand benefits of data-driven neural-based models for predicting spatiotemporal dynamics (e.g., tremendous speedup gain compared with classical numerical methods). However, most existing neural models rely on rich training data, have limited extrapolation and generalization abilities, and suffer to produce precise or reliable physical prediction under intricate conditions (e.g., irregular mesh or geometry, complex boundary conditions, diverse PDE parameters, etc.). To this end, we propose a new graph learning approach, namely, Physics-encoded Message Passing Graph Network (PhyMPGN), to model spatiotemporal PDE systems on irregular meshes given small training datasets. Specifically, we incorporate a GNN into a numerical integrator to approximate the temporal marching of spatiotemporal dynamics for a given PDE system. Considering that many physical phenomena are governed by diffusion processes, we further design a learnable Laplace block, which encodes the discrete Laplace-Beltrami operator, to aid and guide the GNN learning in a physically feasible solution space. A boundary condition padding strategy is also designed to improve the model convergence and accuracy. Extensive experiments demonstrate that PhyMPGN is capable of accurately predicting various types of spatiotemporal dynamics on coarse unstructured meshes, consistently achieves the state-of-the-art results, and outperforms other baselines with considerable gains.
Accelerating Non-Maximum Suppression: A Graph Theory Perspective
Sep 30, 2024



Non-maximum suppression (NMS) is an indispensable post-processing step in object detection. With the continuous optimization of network models, NMS has become the ``last mile'' to enhance the efficiency of object detection. This paper systematically analyzes NMS from a graph theory perspective for the first time, revealing its intrinsic structure. Consequently, we propose two optimization methods, namely QSI-NMS and BOE-NMS. The former is a fast recursive divide-and-conquer algorithm with negligible mAP loss, and its extended version (eQSI-NMS) achieves optimal complexity of $\mathcal{O}(n\log n)$. The latter, concentrating on the locality of NMS, achieves an optimization at a constant level without an mAP loss penalty. Moreover, to facilitate rapid evaluation of NMS methods for researchers, we introduce NMS-Bench, the first benchmark designed to comprehensively assess various NMS methods. Taking the YOLOv8-N model on MS COCO 2017 as the benchmark setup, our method QSI-NMS provides $6.2\times$ speed of original NMS on the benchmark, with a $0.1\%$ decrease in mAP. The optimal eQSI-NMS, with only a $0.3\%$ mAP decrease, achieves $10.7\times$ speed. Meanwhile, BOE-NMS exhibits $5.1\times$ speed with no compromise in mAP.