 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET: Joint Exploration of User Item Profiles in Recommendation System
Apr 15, 2026Traditional recommendation systems represent users and items as dense vectors and learn to align them in a shared latent space for relevance estimation. Recent LLM-based recommenders instead leverage natural-language representations that are easier to interpret and integrate with downstream reasoning modules. This paper studies how to construct effective textual profiles for users and items, and how to align them for recommendation. A central difficulty is that the best profile format is not known a priori: manually designed templates can be brittle and misaligned with task objectives. Moreover, generating user and item profiles independently may produce descriptions that are individually plausible yet semantically inconsistent for a specific user--item pair. We propose Duet, an interaction-aware profile generator that jointly produces user and item profiles conditioned on both user history and item evidence. Duet follows a three-stage procedure: it first turns raw histories and metadata into compact cues, then expands these cues into paired profile prompts and then generate profiles, and finally optimizes the generation policy with reinforcement learning using downstream recommendation performance as feedback. Experiments on three real-world datasets show that Duet consistently outperforms strong baselines, demonstrating the benefits of template-free profile exploration and joint user-item textual alignment.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
When Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
Sep 14, 2024Owing to the unprecedented capability in semantic understanding and logical reasoning, the pre-trained large language models (LLMs) have shown fantastic potential in developing the next-generation recommender systems (RSs). However, the static index paradigm adopted by current methods greatly restricts the utilization of LLMs capacity for recommendation, leading to not only the insufficient alignment between semantic and collaborative knowledge, but also the neglect of high-order user-item interaction patterns. In this paper, we propose Twin-Tower Dynamic Semantic Recommender (TTDS), the first generative RS which adopts dynamic semantic index paradigm, targeting at resolving the above problems simultaneously. To be more specific, we for the first time contrive a dynamic knowledge fusion framework which integrates a twin-tower semantic token generator into the LLM-based recommender, hierarchically allocating meaningful semantic index for items and users, and accordingly predicting the semantic index of target item. Furthermore, a dual-modality variational auto-encoder is proposed to facilitate multi-grained alignment between semantic and collaborative knowledge. Eventually, a series of novel tuning tasks specially customized for capturing high-order user-item interaction patterns are proposed to take advantages of user historical behavior. Extensive experiments across three public datasets demonstrate the superiority of the proposed methodology in developing LLM-based generative RSs. The proposed TTDS recommender achieves an average improvement of 19.41% in Hit-Rate and 20.84% in NDCG metric, compared with the leading baseline methods.
To Copy Rather Than Memorize: A Vertical Learning Paradigm for Knowledge Graph Completion
May 23, 2023



Embedding models have shown great power in knowledge graph completion (KGC) task. By learning structural constraints for each training triple, these methods implicitly memorize intrinsic relation rules to infer missing links. However, this paper points out that the multi-hop relation rules are hard to be reliably memorized due to the inherent deficiencies of such implicit memorization strategy, making embedding models underperform in predicting links between distant entity pairs. To alleviate this problem, we present Vertical Learning Paradigm (VLP), which extends embedding models by allowing to explicitly copy target information from related factual triples for more accurate prediction. Rather than solely relying on the implicit memory, VLP directly provides additional cues to improve the generalization ability of embedding models, especially making the distant link prediction significantly easier. Moreover, we also propose a novel relative distance based negative sampling technique (ReD) for more effective optimization. Experiments demonstrate the validity and generality of our proposals on two standard benchmarks. Our code is available at https://github.com/rui9812/VLP.
Distill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Apr 01, 2022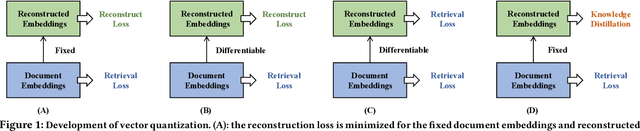
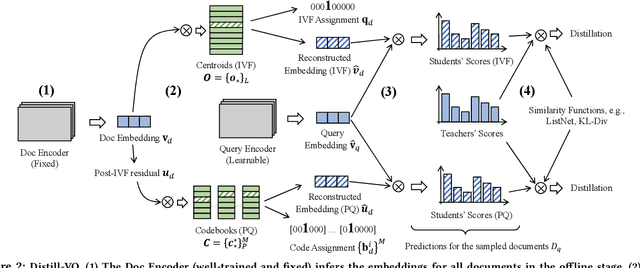
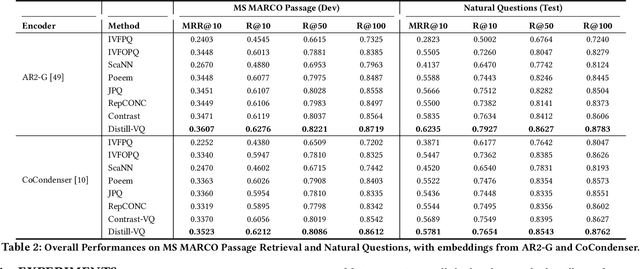
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.
Uni-Retriever: Towards Learning The Unified Embedding Based Retriever in Bing Sponsored Search
Feb 13, 2022
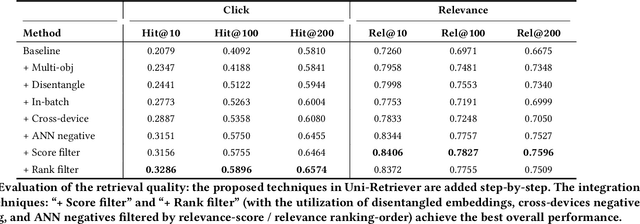
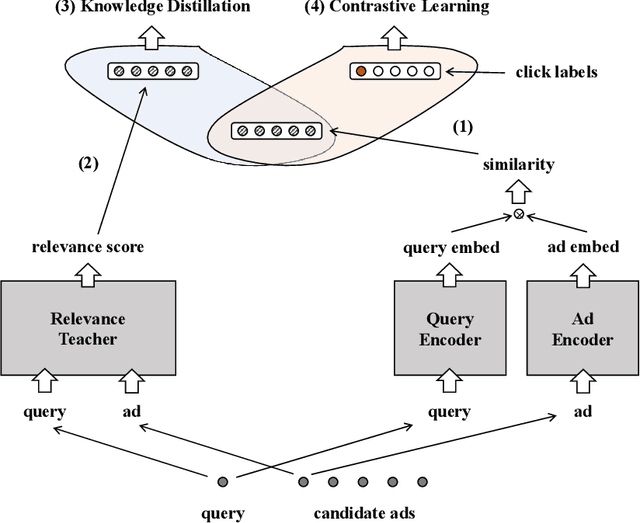
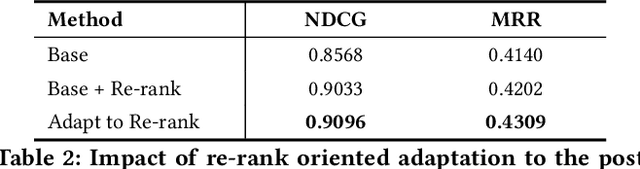
Embedding based retrieval (EBR) is a fundamental building block in many web applications. However, EBR in sponsored search is distinguished from other generic scenarios and technically challenging due to the need of serving multiple retrieval purposes: firstly, it has to retrieve high-relevance ads, which may exactly serve user's search intent; secondly, it needs to retrieve high-CTR ads so as to maximize the overall user clicks. In this paper, we present a novel representation learning framework Uni-Retriever developed for Bing Search, which unifies two different training modes knowledge distillation and contrastive learning to realize both required objectives. On one hand, the capability of making high-relevance retrieval is established by distilling knowledge from the ``relevance teacher model''. On the other hand, the capability of making high-CTR retrieval is optimized by learning to discriminate user's clicked ads from the entire corpus. The two training modes are jointly performed as a multi-objective learning process, such that the ads of high relevance and CTR can be favored by the generated embeddings. Besides the learning strategy, we also elaborate our solution for EBR serving pipeline built upon the substantially optimized DiskANN, where massive-scale EBR can be performed with competitive time and memory efficiency, and accomplished in high-quality. We make comprehensive offline and online experiments to evaluate the proposed techniques, whose findings may provide useful insights for the future development of EBR systems. Uni-Retriever has been mainstreamed as the major retrieval path in Bing's production thanks to the notable improvements on the representation and EBR serving quality.
Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval
Jan 14, 2022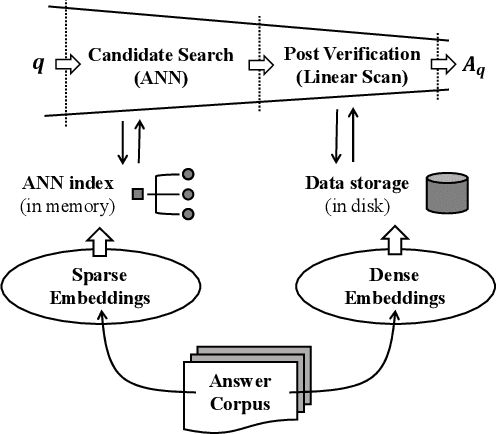
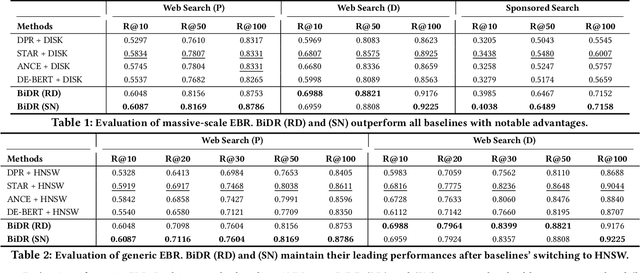
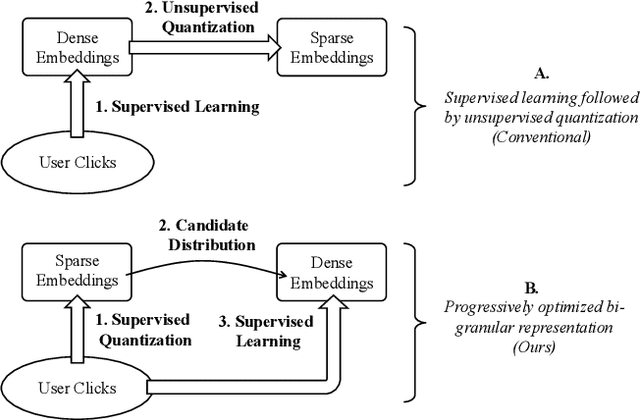

Ad-hoc search calls for the selection of appropriate answers from a massive-scale corpus. Nowadays, the embedding-based retrieval (EBR) becomes a promising solution, where deep learning based document representation and ANN search techniques are allied to handle this task. However, a major challenge is that the ANN index can be too large to fit into memory, given the considerable size of answer corpus. In this work, we tackle this problem with Bi-Granular Document Representation, where the lightweight sparse embeddings are indexed and standby in memory for coarse-grained candidate search, and the heavyweight dense embeddings are hosted in disk for fine-grained post verification. For the best of retrieval accuracy, a Progressive Optimization framework is designed. The sparse embeddings are learned ahead for high-quality search of candidates. Conditioned on the candidate distribution induced by the sparse embeddings, the dense embeddings are continuously learned to optimize the discrimination of ground-truth from the shortlisted candidates. Besides, two techniques: the contrastive quantization and the locality-centric sampling are introduced for the learning of sparse and dense embeddings, which substantially contribute to their performances. Thanks to the above features, our method effectively handles massive-scale EBR with strong advantages in accuracy: with up to +4.3% recall gain on million-scale corpus, and up to +17.5% recall gain on billion-scale corpus. Besides, Our method is applied to a major sponsored search platform with substantial gains on revenue (+1.95%), Recall (+1.01%) and CTR (+0.49%).