 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
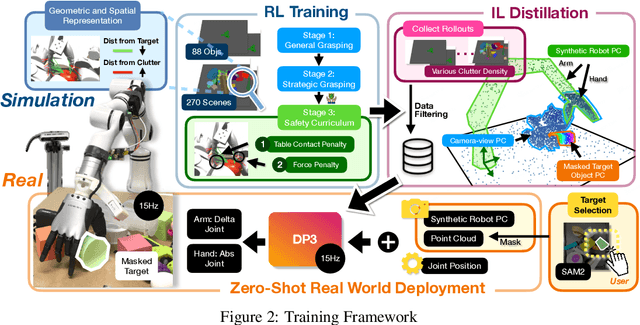


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
CheckManual: A New Challenge and Benchmark for Manual-based Appliance Manipulation
Jun 11, 2025Correct use of electrical appliances has significantly improved human life quality. Unlike simple tools that can be manipulated with common sense, different parts of electrical appliances have specific functions defined by manufacturers. If we want the robot to heat bread by microwave, we should enable them to review the microwave manual first. From the manual, it can learn about component functions, interaction methods, and representative task steps about appliances. However, previous manual-related works remain limited to question-answering tasks while existing manipulation researchers ignore the manual's important role and fail to comprehend multi-page manuals. In this paper, we propose the first manual-based appliance manipulation benchmark CheckManual. Specifically, we design a large model-assisted human-revised data generation pipeline to create manuals based on CAD appliance models. With these manuals, we establish novel manual-based manipulation challenges, metrics, and simulator environments for model performance evaluation. Furthermore, we propose the first manual-based manipulation planning model ManualPlan to set up a group of baselines for the CheckManual benchmark.
SR3D: Unleashing Single-view 3D Reconstruction for Transparent and Specular Object Grasping
May 30, 2025Recent advancements in 3D robotic manipulation have improved grasping of everyday objects, but transparent and specular materials remain challenging due to depth sensing limitations. While several 3D reconstruction and depth completion approaches address these challenges, they suffer from setup complexity or limited observation information utilization. To address this, leveraging the power of single view 3D object reconstruction approaches, we propose a training free framework SR3D that enables robotic grasping of transparent and specular objects from a single view observation. Specifically, given single view RGB and depth images, SR3D first uses the external visual models to generate 3D reconstructed object mesh based on RGB image. Then, the key idea is to determine the 3D object's pose and scale to accurately localize the reconstructed object back into its original depth corrupted 3D scene. Therefore, we propose view matching and keypoint matching mechanisms,which leverage both the 2D and 3D's inherent semantic and geometric information in the observation to determine the object's 3D state within the scene, thereby reconstructing an accurate 3D depth map for effective grasp detection. Experiments in both simulation and real world show the reconstruction effectiveness of SR3D.
To Trust Or Not To Trust Your Vision-Language Model's Prediction
May 29, 2025Vision-Language Models (VLMs) have demonstrated strong capabilities in aligning visual and textual modalities, enabling a wide range of applications in multimodal understanding and generation. While they excel in zero-shot and transfer learning scenarios, VLMs remain susceptible to misclassification, often yielding confident yet incorrect predictions. This limitation poses a significant risk in safety-critical domains, where erroneous predictions can lead to severe consequences. In this work, we introduce TrustVLM, a training-free framework designed to address the critical challenge of estimating when VLM's predictions can be trusted. Motivated by the observed modality gap in VLMs and the insight that certain concepts are more distinctly represented in the image embedding space, we propose a novel confidence-scoring function that leverages this space to improve misclassification detection. We rigorously evaluate our approach across 17 diverse datasets, employing 4 architectures and 2 VLMs, and demonstrate state-of-the-art performance, with improvements of up to 51.87% in AURC, 9.14% in AUROC, and 32.42% in FPR95 compared to existing baselines. By improving the reliability of the model without requiring retraining, TrustVLM paves the way for safer deployment of VLMs in real-world applications. The code will be available at https://github.com/EPFL-IMOS/TrustVLM.
From Strangers to Assistants: Fast Desire Alignment for Embodied Agent-User Adaptation
May 28, 2025While embodied agents have made significant progress in performing complex physical tasks, real-world applications demand more than pure task execution. The agents must collaborate with unfamiliar agents and human users, whose goals are often vague and implicit. In such settings, interpreting ambiguous instructions and uncovering underlying desires is essential for effective assistance. Therefore, fast and accurate desire alignment becomes a critical capability for embodied agents. In this work, we first develop a home assistance simulation environment HA-Desire that integrates an LLM-driven human user agent exhibiting realistic value-driven goal selection and communication. The ego agent must interact with this proxy user to infer and adapt to the user's latent desires. To achieve this, we present a novel framework FAMER for fast desire alignment, which introduces a desire-based mental reasoning mechanism to identify user intent and filter desire-irrelevant actions. We further design a reflection-based communication module that reduces redundant inquiries, and incorporate goal-relevant information extraction with memory persistence to improve information reuse and reduce unnecessary exploration. Extensive experiments demonstrate that our framework significantly enhances both task execution and communication efficiency, enabling embodied agents to quickly adapt to user-specific desires in complex embodied environments.
SpikeStereoNet: A Brain-Inspired Framework for Stereo Depth Estimation from Spike Streams
May 26, 2025



Conventional frame-based cameras often struggle with stereo depth estimation in rapidly changing scenes. In contrast, bio-inspired spike cameras emit asynchronous events at microsecond-level resolution, providing an alternative sensing modality. However, existing methods lack specialized stereo algorithms and benchmarks tailored to the spike data. To address this gap, we propose SpikeStereoNet, a brain-inspired framework and the first to estimate stereo depth directly from raw spike streams. The model fuses raw spike streams from two viewpoints and iteratively refines depth estimation through a recurrent spiking neural network (RSNN) update module. To benchmark our approach, we introduce a large-scale synthetic spike stream dataset and a real-world stereo spike dataset with dense depth annotations. SpikeStereoNet outperforms existing methods on both datasets by leveraging spike streams' ability to capture subtle edges and intensity shifts in challenging regions such as textureless surfaces and extreme lighting conditions. Furthermore, our framework exhibits strong data efficiency, maintaining high accuracy even with substantially reduced training data. The source code and datasets will be publicly available.
Extremely Simple Multimodal Outlier Synthesis for Out-of-Distribution Detection and Segmentation
May 22, 2025Out-of-distribution (OOD) detection and segmentation are crucial for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. While prior research has primarily focused on unimodal image data, real-world applications are inherently multimodal, requiring the integration of multiple modalities for improved OOD detection. A key challenge is the lack of supervision signals from unknown data, leading to overconfident predictions on OOD samples. To address this challenge, we propose Feature Mixing, an extremely simple and fast method for multimodal outlier synthesis with theoretical support, which can be further optimized to help the model better distinguish between in-distribution (ID) and OOD data. Feature Mixing is modality-agnostic and applicable to various modality combinations. Additionally, we introduce CARLA-OOD, a novel multimodal dataset for OOD segmentation, featuring synthetic OOD objects across diverse scenes and weather conditions. Extensive experiments on SemanticKITTI, nuScenes, CARLA-OOD datasets, and the MultiOOD benchmark demonstrate that Feature Mixing achieves state-of-the-art performance with a $10 \times$ to $370 \times$ speedup. Our source code and dataset will be available at https://github.com/mona4399/FeatureMixing.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025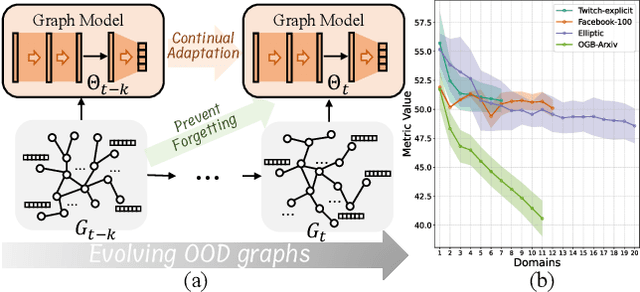
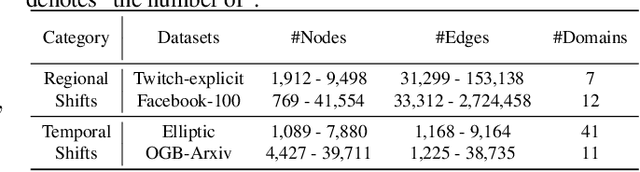
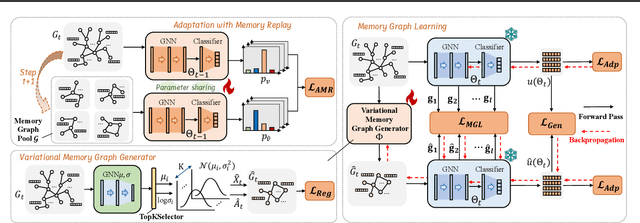
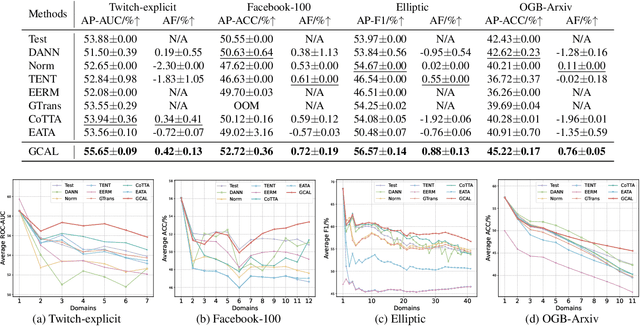
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
Adaptive Visuo-Tactile Fusion with Predictive Force Attention for Dexterous Manipulation
May 20, 2025Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However, the heterogeneous nature of these modalities makes fusion challenging. Existing methods propose strategies to obtain comprehensively fused features but often ignore the fact that each modality requires different levels of attention at different manipulation stages. To address this, we propose a force-guided attention fusion module that adaptively adjusts the weights of visual and tactile features without human labeling. We also introduce a self-supervised future force prediction auxiliary task to reinforce the tactile modality, improve data imbalance, and encourage proper adjustment. Our method achieves an average success rate of 93% across three fine-grained, contactrich tasks in real-world experiments. Further analysis shows that our policy appropriately adjusts attention to each modality at different manipulation stages. The videos can be viewed at https://adaptac-dex.github.io/.